HDF5 es un formato de datos jerárquico que se usar en el NILMTK como fuente datos basado en HDF4 y NetCDF (otros dos formatos de datos jerárquicos).El formato de datos jerárquico, versión 5 (HDF5), es un formato de archivo de código abierto que admite datos grandes, complejos y heterogéneos. HDF5 utiliza una estructura similar a un «directorio de archivos» que le permite organizar los datos dentro del archivo de muchas formas estructuradas diferentes, como lo haría con los archivos en su computadora. El formato HDF5 también permite la incrustación de metadatos, lo que lo hace autodescriptivo .

Estructura jerárquica: un directorio de archivos dentro de un archivo
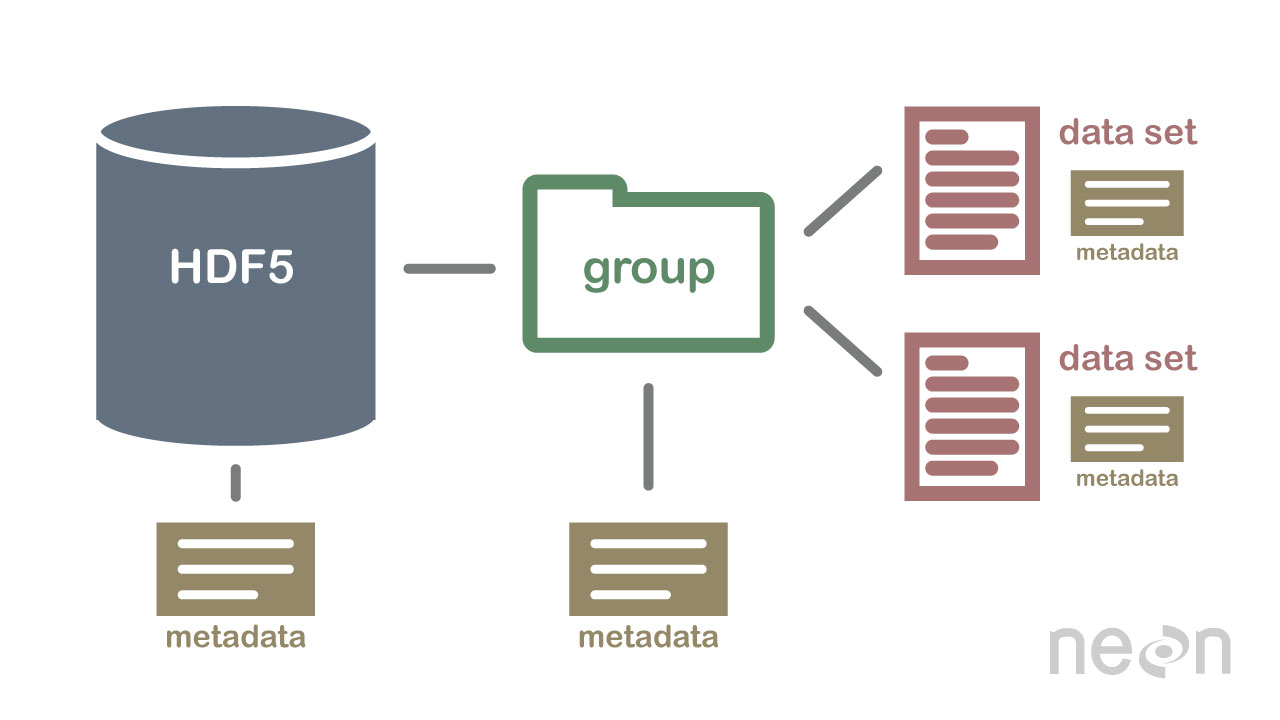
El formato HDF5 se puede considerar como un sistema de archivos contenido y descrito en un solo archivo. Piense en los archivos y carpetas almacenados en su computadora. Es posible que tenga un directorio de datos con algunos datos de temperatura para varios sitios de campo. Estos datos de temperatura se recopilan cada minuto y se resumen cada hora, día y semana. Dentro de un archivo HDF5, puede almacenar un conjunto de datos similar organizado de la misma manera que podría organizar archivos y carpetas en su computadora. Sin embargo, en un archivo HDF5, lo que llamamos «directorios» o «carpetas» en nuestras computadoras, se llaman groupsy lo que llamamos archivos en nuestra computadora datasets.
2 Términos importantes de HDF5
- Grupo: un elemento similar a una carpeta dentro de un archivo HDF5 que puede contener otros grupos O conjuntos de datos dentro de él.
- Conjunto de datos: los datos reales contenidos en el archivo HDF5. Los conjuntos de datos se almacenan a menudo (pero no es necesario) dentro de grupos en el archivo.
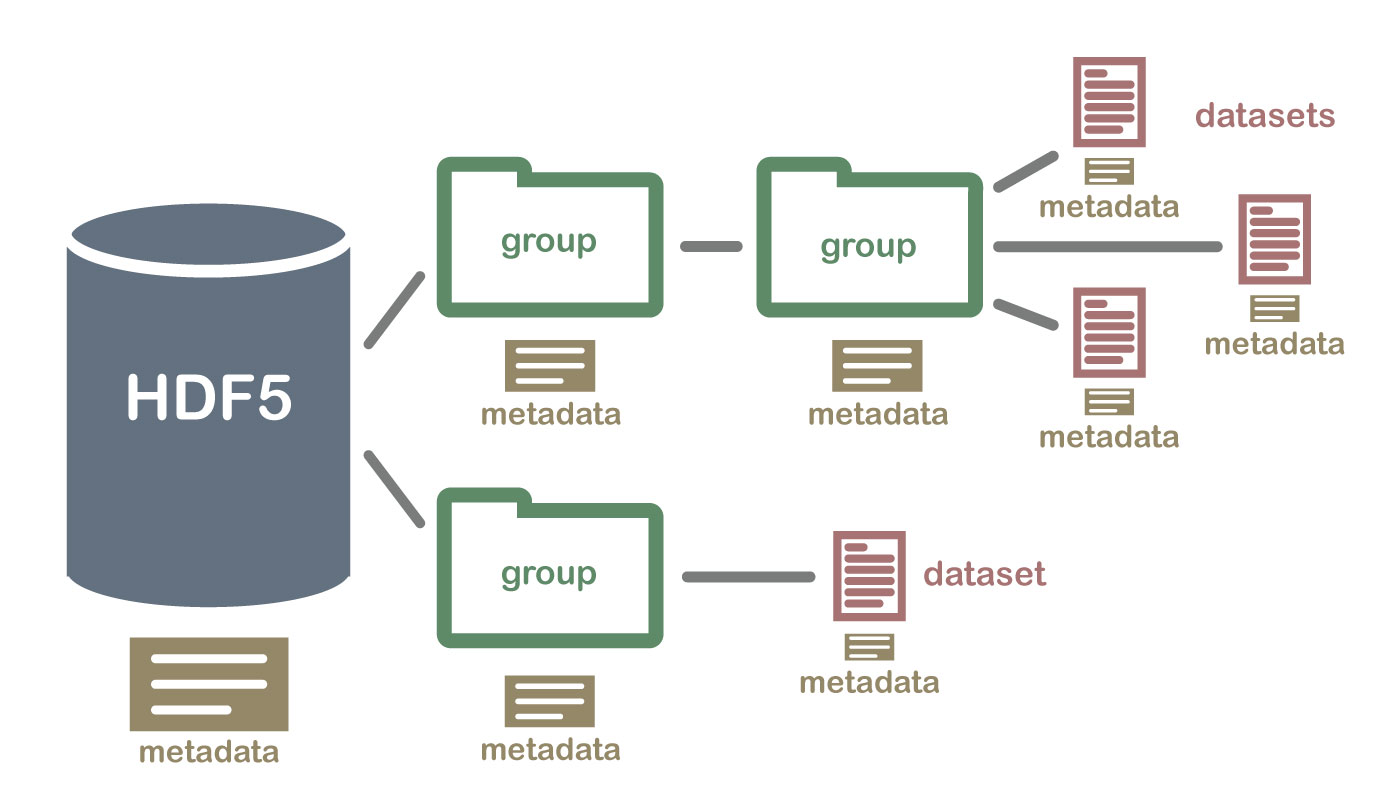
Un archivo HDF5 que contiene conjuntos de datos podría estructurarse así:
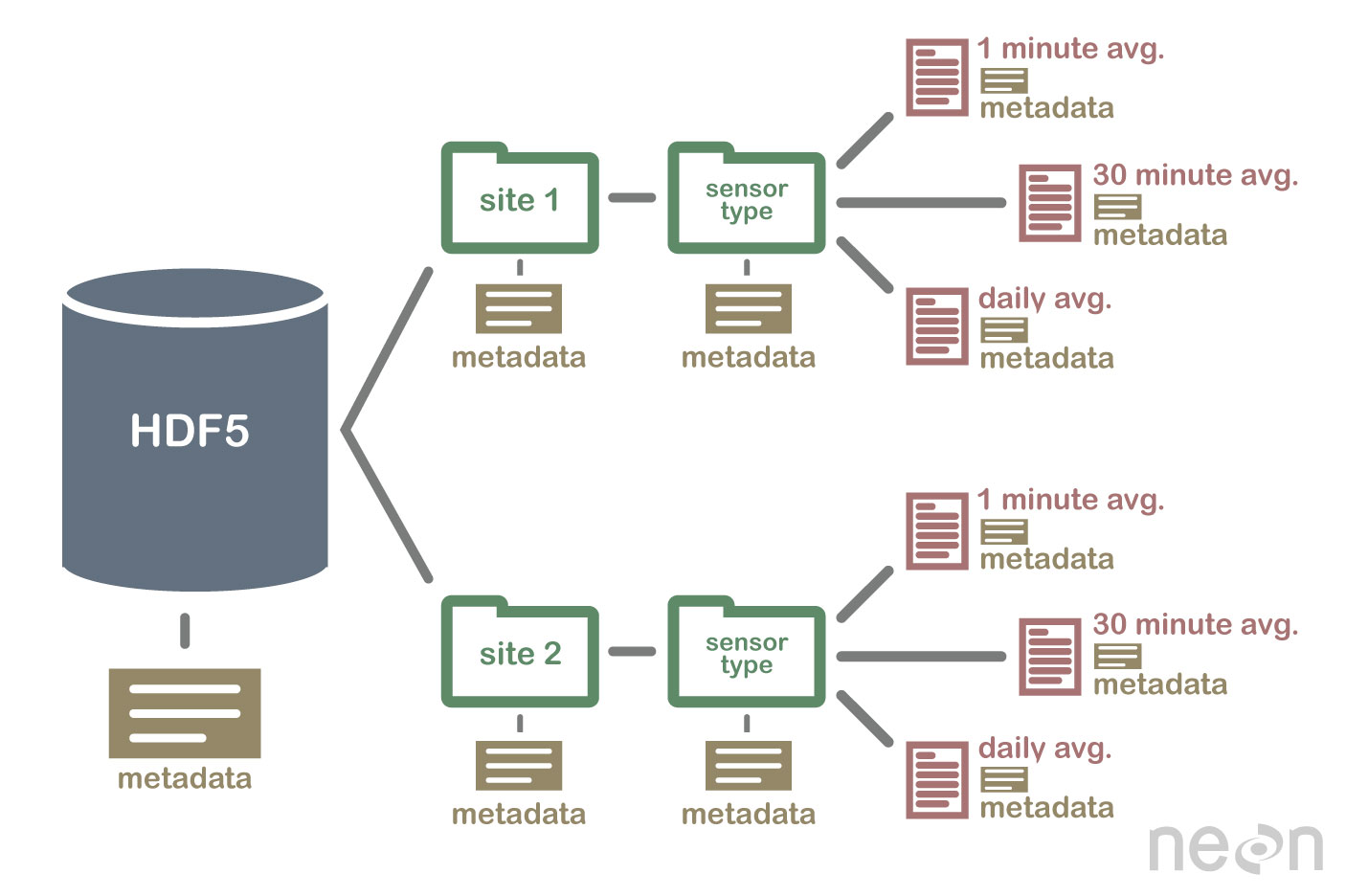
HDF5 es un formato autodescriptivo
El formato HDF5 es autodescriptivo. Esto significa que cada archivo, grupo y conjunto de datos puede tener metadatos asociados que describen exactamente cuáles son los datos. Siguiendo el ejemplo anterior, podemos incrustar información sobre cada sitio en el archivo, como por ejemplo:
- El nombre completo y la ubicación X, Y del sitio.
- Descripción del sitio.
- Cualquier documentación de interés.
De manera similar, podríamos agregar información sobre cómo se recopilaron los datos en el conjunto de datos, como descripciones del sensor utilizado para recopilar los datos de temperatura. También podemos adjuntar información, a cada conjunto de datos dentro del grupo de sitios, sobre cómo se realizó el promedio y durante qué período de tiempo están disponibles los datos.
Un beneficio clave de tener metadatos adjuntos a cada archivo, grupo y conjunto de datos es que esto facilita la automatización sin la necesidad de un documento de metadatos separado (y adicional). Usando un lenguaje de programación, como R o Python, podemos obtener información de los metadatos que ya están asociados con el conjunto de datos y que podríamos necesitar para procesar el conjunto de datos.
Subconjunto comprimido y eficiente
El formato HDF5 es un formato comprimido. El tamaño de todos los datos contenidos en HDF5 está optimizado, lo que reduce el tamaño general del archivo. Sin embargo, incluso cuando están comprimidos, los archivos HDF5 a menudo contienen grandes volúmenes de datos y, por lo tanto, pueden ser bastante grandes. Un atributo poderoso de HDF5 es data slicingmediante el cual se puede extraer un subconjunto particular de un conjunto de datos para su procesamiento. Esto significa que no es necesario leer el conjunto de datos completo en la memoria (RAM); muy útil para permitirnos trabajar de manera más eficiente con conjuntos de datos muy grandes (gigabytes o más).
Almacenamiento de datos heterogéneos
Los archivos HDF5 pueden almacenar muchos tipos diferentes de datos dentro del mismo archivo. Por ejemplo, un grupo puede contener un conjunto de conjuntos de datos para contener datos enteros (numéricos) y de texto (cadenas). O bien, un conjunto de datos puede contener tipos de datos heterogéneos (por ejemplo, tanto texto como datos numéricos en un conjunto de datos). Esto significa que HDF5 puede almacenar cualquiera de los siguientes (y más) en un archivo:
- Datos de temperatura, precipitación y PAR (radiación fotosintética activa) para un sitio o para muchos sitios
- Un conjunto de imágenes que cubren una o más áreas (cada imagen puede tener asociada información espacial específica, todo en el mismo archivo)
- Un conjunto de datos espaciales multi o hiperespectral que contiene cientos de bandas.
- Datos de campo para varios sitios que caracterizan insectos, mamíferos, vegetación y clima.
- Un conjunto de imágenes que cubren una o más áreas (cada imagen puede tener asociada información espacial única)
- ¡Y mucho más!
Formato abierto
El formato HDF5 es abierto y de uso gratuito. Las bibliotecas de apoyo (y un visor gratuito) se pueden descargar desde el sitio web de HDF Group . Como tal, HDF5 es ampliamente compatible con una gran cantidad de programas, incluidos lenguajes de programación de código abierto como R y Python, y herramientas de programación comerciales como Matlaby IDL. Los datos espaciales que se almacenan en formato HDF5 se pueden utilizar en los programas de SIG y de imagen que incluyen QGIS, ArcGISy ENVI.
Beneficios de HDF5
- Autodescripción Los conjuntos de datos con un archivo HDF5 son autodescriptivos. Esto nos permite extraer metadatos de manera eficiente sin necesidad de un documento de metadatos adicional.
- Admite datos heterogéneos : un archivo HDF5 puede contener diferentes tipos de conjuntos de datos.
- Admite datos grandes y complejos : HDF5 es un formato comprimido que está diseñado para admitir conjuntos de datos grandes, heterogéneos y complejos.
- Admite la división de datos: la «división de datos», o la extracción de partes del conjunto de datos según sea necesario para el análisis, significa que los archivos grandes no necesitan leerse por completo en la memoria o RAM de la computadora.
- Formato abierto: soporte amplio en las muchas herramientas : debido a que el formato HDF5 es abierto, es compatible con una gran cantidad de lenguajes y herramientas de programación, incluidos lenguajes de código abierto como R y
Pythonherramientas SIG abiertas comoQGIS.E
Instalación
Un archivo HDF5 es un contenedor para dos tipos de objetos: conjuntos de datos , que son colecciones de datos en forma de matriz, y grupos , que son contenedores en forma de carpeta que contienen conjuntos de datos y otros grupos. Lo más fundamental que debe recordar al usar h5py es que los grupos funcionan como diccionarios y los conjuntos de datos funcionan como matrices NumPy
Supongamos que alguien le ha enviado un archivo HDF5, mytestfile.hdf5. Lo primero que debe hacer es abrir el archivo para leerlo:
>>> import h5py
>>> f = h5py.File(‘mytestfile.hdf5’, ‘r’)
Lógicamente para usar este modulo h5py ,primero debemos instalarlos en el pc:
- Con Anaconda o Miniconda : conda install h5py
- Si puede instalarlo con pip para su plataforma (mac, linux, windows en x86) y no necesita MPI, puede instalar h5py a través de pip:pip install h5py
- Con Enthought Canopy , use el administrador de paquetes GUI o: enpkg h5py
El objeto Archivo es su punto de partida. ¿Qué se almacena en este archivo? Recuerde que h5py.File actúa como un diccionario de Python, por lo que podemos verificar las claves,
>>> list(f.keys()) ['mydataset']
Según nuestra observación, hay un conjunto de datos mydataseten el archivo. Examinemos el conjunto de datos como un objeto de conjunto de datos
>>> dset = f['mydataset']
El objeto que obtuvimos no es una matriz, sino un conjunto de datos HDF5 . Al igual que las matrices NumPy, los conjuntos de datos tienen una forma y un tipo de datos:
>>> dset.shape
(100,)
>>> dset.dtype
dtype('int32')
También admiten el corte en forma de matriz. Así es como lee y escribe datos de un conjunto de datos en el archivo:
>>> dset[...] = np.arange(100) >>> dset[0] 0 >>> dset[10] 10 >>> dset[0:100:10] array([ 0, 10, 20, 30, 40, 50, 60, 70, 80, 90])
Creación de un archivo
En este punto, es posible que se pregunte cómo mytestdata.hdf5se crea. Podemos crear un archivo configurando el modea wcuando se inicializa el objeto Archivo. Algunos otros modos son a(para acceso de lectura / escritura / creación) y r+(para acceso de lectura / escritura).
>>> import h5py
>>> import numpy as np
>>> f = h5py.File("mytestfile.hdf5", "w")
El objeto File tiene un par de métodos que parecen interesantes. Uno de ellos es create_dataset, que como su nombre indica, crea un conjunto de datos de forma y tipo dados
>>> dset = f.create_dataset("mydataset", (100,), dtype='i')
El objeto Archivo es un administrador de contexto; entonces el siguiente código también funciona
>>> import h5py
>>> import numpy as np
>>> with h5py.File("mytestfile.hdf5", "w") as f:
>>> dset = f.create_dataset("mydataset", (100,), dtype='i')
Grupos y organización jerárquica
«HDF» significa «Formato de datos jerárquico». Todos los objetos de un archivo HDF5 tienen un nombre y están organizados en una jerarquía de estilo POSIX con /-separadores:
>>> dset.name '/mydataset'
Las «carpetas» de este sistema se denominan grupos . El Fileobjeto que creamos es en sí mismo un grupo, en este caso el grupo raíz , llamado /:
>>> f.name '/'
La creación de un subgrupo se logra a través del nombre apropiado create_group. Pero primero tenemos que abrir el archivo en el modo «agregar» (leer / escribir si existe, crear de lo contrario)
>>> f = h5py.File('mydataset.hdf5', 'a')
>>> grp = f.create_group("subgroup")
Todos los Groupobjetos también tienen create_*métodos como Archivo:
>>> dset2 = grp.create_dataset("another_dataset", (50,), dtype='f')
>>> dset2.name
'/subgroup/another_dataset'
Por cierto, no es necesario que cree todos los grupos intermedios manualmente. Especificar una ruta completa funciona bien:
>>> dset3 = f.create_dataset('subgroup2/dataset_three', (10,), dtype='i')
>>> dset3.name
'/subgroup2/dataset_three'
Los grupos admiten la mayor parte de la interfaz de estilo de diccionario de Python. Recupera objetos en el archivo usando la sintaxis de recuperación de elementos:
>>> dataset_three = f['subgroup2/dataset_three']
La iteración sobre un grupo proporciona los nombres de sus miembros:
>>> for name in f: ... print(name) mydataset subgroup subgroup2
La prueba de membresía también usa nombres:
>>> "mydataset" in f True >>> "somethingelse" in f False
Incluso puede usar nombres de ruta completos:
>>> "subgroup/another_dataset" in f True
También están los familiares keys(), values(), items()y iter()métodos, así como get().
Dado que la iteración sobre un grupo solo produce sus miembros adjuntos directamente, la iteración sobre un archivo completo se logra con los Groupmétodos visit()y visititems(), que toman un invocable:
>>> def printname(name): ... print(name) >>> f.visit(printname) mydataset subgroup subgroup/another_dataset subgroup2 subgroup2/dataset_three
Atributos
Una de las mejores características de HDF5 es que puede almacenar metadatos junto a los datos que describe. Todos los grupos y conjuntos de datos admiten bits de datos adjuntos denominados atributos .
Se accede a los atributos a través del attrsobjeto proxy, que nuevamente implementa la interfaz del diccionario:
>>> dset.attrs['temperature'] = 99.5 >>> dset.attrs['temperature'] 99.5 >>> 'temperature' in dset.attrs True
Mas información en https://docs.h5py.org/en/latest/build.html