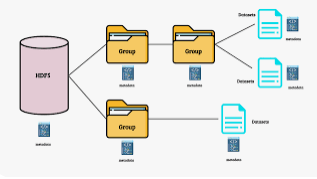
HDF5 es un formato de datos jerárquico que se usar en el NILMTK como fuente datos basado en HDF4 y NetCDF (otros dos formatos de datos jerárquicos).El formato de datos jerárquico, versión 5 (HDF5), es un formato de archivo de código abierto que admite datos grandes, complejos y heterogéneos. HDF5 utiliza una estructura similar a un «directorio de archivos» que le permite organizar los datos dentro del archivo de muchas formas estructuradas diferentes, como lo haría con los archivos en su computadora. El formato HDF5 también permite la incrustación de metadatos, lo que lo hace autodescriptivo .
El formato de archivo HDF5 es desarrollado por The HDF Group. Es un formato de archivo binario abierto con buen soporte en varios lenguajes de programación, incluido Python. En principio, podría usar cualquier lenguaje para crear su convertidor de conjuntos de datos, pero recomendamos el lenguaje Python y no hemos intentado escribir convertidores en otro idioma. Trabajar con archivos HDF5 es realmente fácil en Python usando Pandas (que, a su vez, usa el excelente paquete PyTables ).

Estructura jerárquica: un directorio de archivos dentro de un archivo
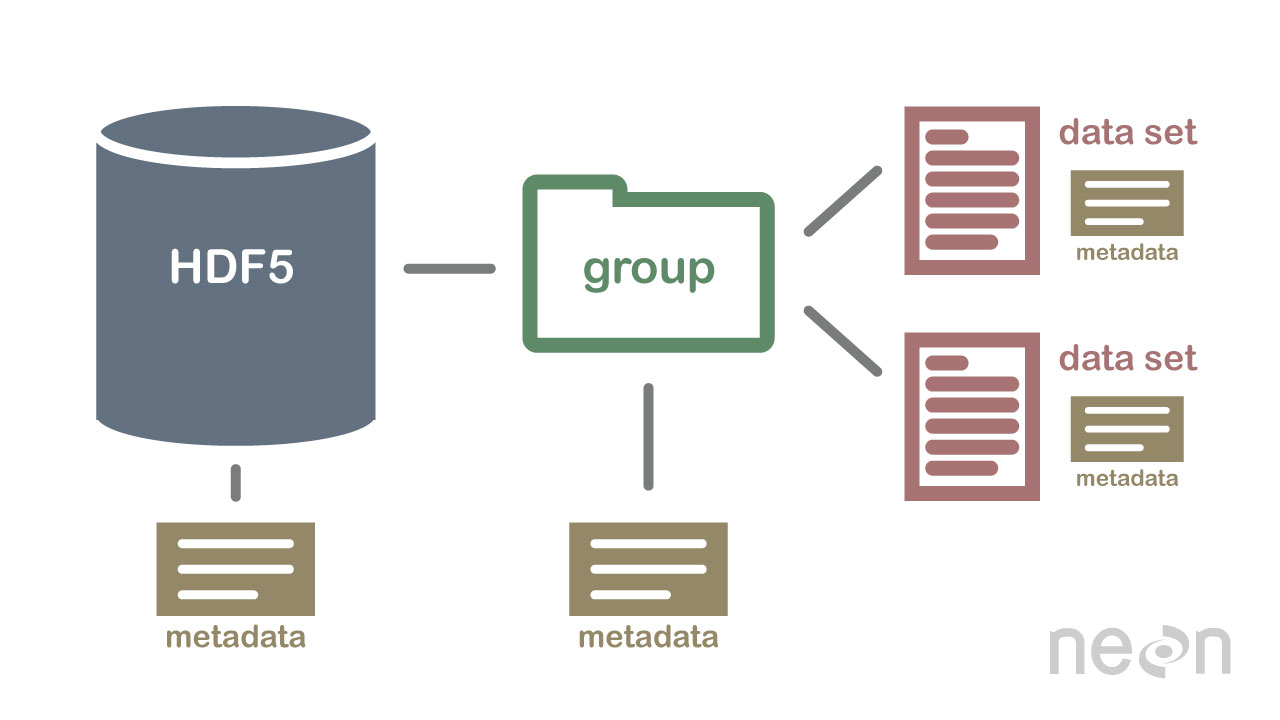
El formato HDF5 se puede considerar como un sistema de archivos contenido y descrito en un solo archivo. Piense en los archivos y carpetas almacenados en su computadora. Es posible que tenga un directorio de datos con algunos datos de temperatura para varios sitios de campo. Estos datos de temperatura se recopilan cada minuto y se resumen cada hora, día y semana. Dentro de un archivo HDF5, puede almacenar un conjunto de datos similar organizado de la misma manera que podría organizar archivos y carpetas en su computadora. Sin embargo, en un archivo HDF5, lo que llamamos «directorios» o «carpetas» en nuestras computadoras, se llaman groupsy lo que llamamos archivos en nuestra computadora datasets.
2 Términos importantes de HDF5
- Grupo: un elemento similar a una carpeta dentro de un archivo HDF5 que puede contener otros grupos O conjuntos de datos dentro de él.
- Conjunto de datos: los datos reales contenidos en el archivo HDF5. Los conjuntos de datos se almacenan a menudo (pero no es necesario) dentro de grupos en el archivo.
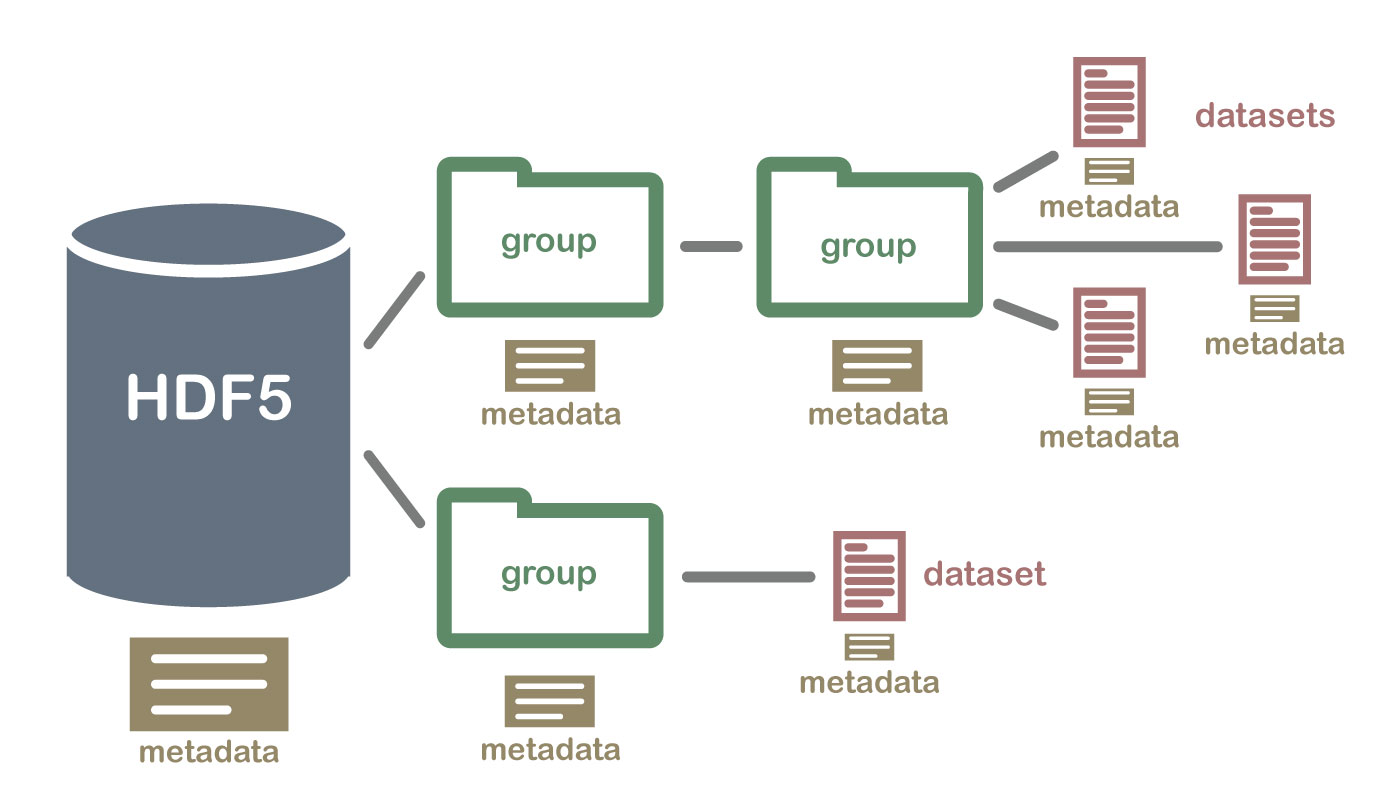
Un archivo HDF5 que contiene conjuntos de datos podría estructurarse así:
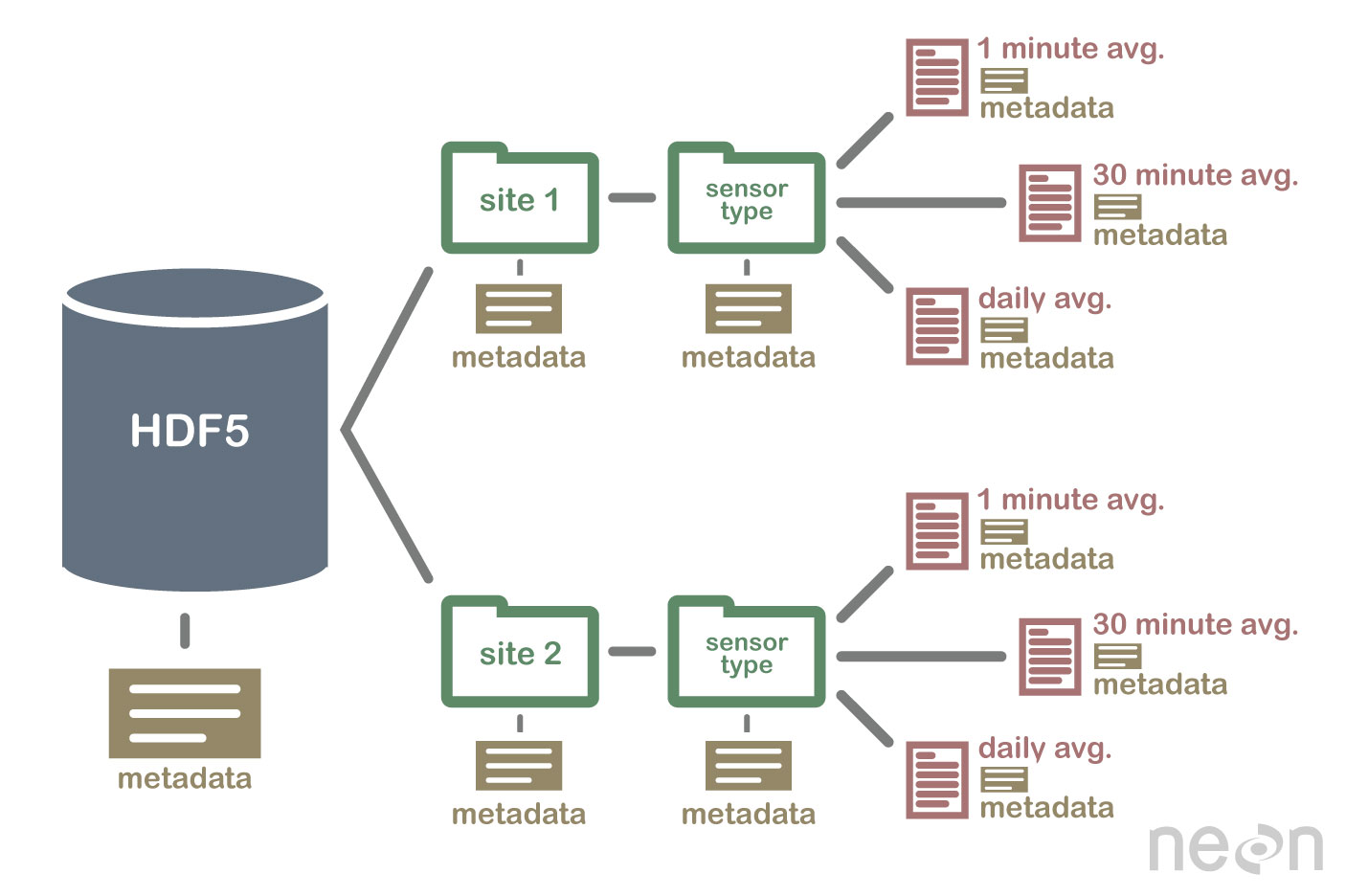
HDF5 es un formato autodescriptivo
El formato HDF5 es autodescriptivo. Esto significa que cada archivo, grupo y conjunto de datos puede tener metadatos asociados que describen exactamente cuáles son los datos. Siguiendo el ejemplo anterior, podemos incrustar información sobre cada sitio en el archivo, como por ejemplo:
- El nombre completo y la ubicación X, Y del sitio.
- Descripción del sitio.
- Cualquier documentación de interés.
De manera similar, podríamos agregar información sobre cómo se recopilaron los datos en el conjunto de datos, como descripciones del sensor utilizado para recopilar los datos de temperatura. También podemos adjuntar información, a cada conjunto de datos dentro del grupo de sitios, sobre cómo se realizó el promedio y durante qué período de tiempo están disponibles los datos.
Un beneficio clave de tener metadatos adjuntos a cada archivo, grupo y conjunto de datos es que esto facilita la automatización sin la necesidad de un documento de metadatos separado (y adicional). Usando un lenguaje de programación, como R o Python, podemos obtener información de los metadatos que ya están asociados con el conjunto de datos y que podríamos necesitar para procesar el conjunto de datos.
Subconjunto comprimido y eficiente
El formato HDF5 es un formato comprimido. El tamaño de todos los datos contenidos en HDF5 está optimizado, lo que reduce el tamaño general del archivo. Sin embargo, incluso cuando están comprimidos, los archivos HDF5 a menudo contienen grandes volúmenes de datos y, por lo tanto, pueden ser bastante grandes. Un atributo poderoso de HDF5 es data slicingmediante el cual se puede extraer un subconjunto particular de un conjunto de datos para su procesamiento. Esto significa que no es necesario leer el conjunto de datos completo en la memoria (RAM); muy útil para permitirnos trabajar de manera más eficiente con conjuntos de datos muy grandes (gigabytes o más).
Almacenamiento de datos heterogéneos
Los archivos HDF5 pueden almacenar muchos tipos diferentes de datos dentro del mismo archivo. Por ejemplo, un grupo puede contener un conjunto de conjuntos de datos para contener datos enteros (numéricos) y de texto (cadenas). O bien, un conjunto de datos puede contener tipos de datos heterogéneos (por ejemplo, tanto texto como datos numéricos en un conjunto de datos). Esto significa que HDF5 puede almacenar cualquiera de los siguientes (y más) en un archivo:
- Datos de temperatura, precipitación y PAR (radiación fotosintética activa) para un sitio o para muchos sitios
- Un conjunto de imágenes que cubren una o más áreas (cada imagen puede tener asociada información espacial específica, todo en el mismo archivo)
- Un conjunto de datos espaciales multi o hiperespectral que contiene cientos de bandas.
- Datos de campo para varios sitios que caracterizan insectos, mamíferos, vegetación y clima.
- Un conjunto de imágenes que cubren una o más áreas (cada imagen puede tener asociada información espacial única)
- ¡Y mucho más!
Formato abierto
El formato HDF5 es abierto y de uso gratuito. Las bibliotecas de apoyo (y un visor gratuito) se pueden descargar desde el sitio web de HDF Group . Como tal, HDF5 es ampliamente compatible con una gran cantidad de programas, incluidos lenguajes de programación de código abierto como R y Python, y herramientas de programación comerciales como Matlaby IDL. Los datos espaciales que se almacenan en formato HDF5 se pueden utilizar en los programas de SIG y de imagen que incluyen QGIS, ArcGISy ENVI.
Beneficios de HDF5
- Autodescripción Los conjuntos de datos con un archivo HDF5 son autodescriptivos. Esto nos permite extraer metadatos de manera eficiente sin necesidad de un documento de metadatos adicional.
- Admite datos heterogéneos : un archivo HDF5 puede contener diferentes tipos de conjuntos de datos.
- Admite datos grandes y complejos : HDF5 es un formato comprimido que está diseñado para admitir conjuntos de datos grandes, heterogéneos y complejos.
- Admite la división de datos: la «división de datos», o la extracción de partes del conjunto de datos según sea necesario para el análisis, significa que los archivos grandes no necesitan leerse por completo en la memoria o RAM de la computadora.
- Formato abierto: soporte amplio en las muchas herramientas : debido a que el formato HDF5 es abierto, es compatible con una gran cantidad de lenguajes y herramientas de programación, incluidos lenguajes de código abierto como R y
Pythonherramientas SIG abiertas comoQGIS.E
Si desea contribuir con un nuevo convertidor de conjuntos de datos a H5 (o simplemente comprender mejor los convertidores existentes), probablemente la mejor manera de ponerse al día es leer este post pues vamos a ver el diseño de los datos en un archivo NILMTK HDF5. Asimismo se recomienda eche un vistazo al convertidor REDD para NILMTK (in
nilmtk/nilmtk/dataset_converters/redd).
Los convertidores de conjuntos de datos NILMTK generan un archivo HDF5 que contiene tanto los datos de la serie temporal de cada medidor como todos los metadatos relevantes, veamos pues como crear uno nuevo.
Datos de series de tiempo
Los datos de cada medidor físico se almacenan en su propia tabla (es decir, existe una relación de uno a uno entre las tablas del archivo HDF5 y los medidores físicos).
Ubicación de la mesa (llaves)
Las tablas en HDF5 se identifican mediante una clave jerárquica. Cada clave es una cuerda. Los niveles de la jerarquía están separados por un /carácter en la clave. NILMTK usa claves en la forma /building<i>/elec/meter<j>donde iy json números enteros que comienzan desde 1. ies la instancia del edificio y jes la instancia del medidor. Por ejemplo, la tabla que almacena datos de la instancia 1 del medidor en la instancia 1 del edificio tendría la clave /building1/elec/meter1. (Usamos elecen la jerarquía para permitirnos, en el futuro, agregar soporte para otros tipos de sensores como medidores de agua y gas).
Contenido de cada tabla
Ilustración
| poder | energía | Voltaje | |
|---|---|---|---|
| activo | reactivo | ||
| 2014-07-01T05: 00: 14 + 00: 00 | 0,1 | 0,01 | 231.1 |
| 2014-07-01T05: 00: 15 + 00: 00 | 100,5 | 10,5 | 232,1 |
Columna de índice
La columna de índice es una fecha y hora representada en el disco como una marca de tiempo UNIX de precisión de nanosegundos (!) Almacenada como un int de 64 bits sin firmar. En Python, usamos un archivo con reconocimiento de zona horaria numpy.datetime64. El marco de datos debe ordenarse en orden ascendente en la columna de índice (marca de tiempo).
Para evitar problemas más adelante, la columna de índice debe tener valores únicos. Si hay duplicados, el convertidor debe eliminar uno de los elementos o eliminar la ambigüedad si es posible.
Columnas de medida
Cada columna, excepto la columna de índice, contiene una medida tomada por el medidor. Estas medidas pueden ser demanda de potencia, energía, energía acumulada, voltaje o corriente. Cada medición se representa como un número de coma flotante de 32 bits.
Siempre usamos unidades SI o unidades derivadas del SI y NILMTK asume que no se ha aplicado ningún prefijo de unidad (por ejemplo, ‘kilo-‘ o ‘mega-‘). En otras palabras, NILMTK asume un multiplicador de unidad de 1. Por ejemplo, siempre usamos vatios (no kW) para la potencia activa. Si el conjunto de datos de origen usa, digamos, kW, multiplique estos valores por 1000 en su convertidor.
Etiquetas de columna
Las etiquetas de columna son jerárquicas con 2 niveles ( las etiquetas jerárquicas son muy bien compatibles con Pandas ). El nivel superior describe lo que se physical_quantityestá midiendo. El nivel de segundos describe el typeque, en la actualidad, se usa para las columnas de energía y potencia para describir si la medición de corriente alterna es apparent, activeo reactive. Usamos un vocabulario controlado para ambos physical_quanitityy type. Para los detalles completos de este vocabulario controlado, por favor consulte la documentación physical_quantityy typeen virtud de la measurementspropiedad para el objeto MeterDevice en NILM metadatos .
Compresión
Usamos zlibpara comprimir nuestros archivos HDF5. bzip2da como resultado archivos un poco más pequeños (261 MB bzip2frente a 273 MB zlibpara REDD) pero no parece ser compatible con HDFView .
Metadatos
Para que NILMTK pueda cargar el conjunto de datos, necesitamos agregar metadatos al archivo HDF5. NILMTK utiliza el esquema de metadatos de NILM .
Si el conjunto de datos ya está descrito en YAML usando el esquema de metadatos NILM, simplemente llame nilm_metadata.convert_yaml_to_hdf5().
Si el conjunto de datos aún no se describe mediante el esquema de metadatos de NILM, será necesario hacerlo. Si se trata de un conjunto de datos pequeño, puede escribir manualmente los archivos YAML y luego convertirlos a HDF5 (así es como funciona nuestro convertidor REDD). Si se trata de un conjunto de datos grande, sería mejor convertir mediante programación los propios metadatos del conjunto de datos en metadatos NILM y almacenar los metadatos directamente en el archivo HDF5.
Los metadatos NILM nos permiten describir muchos de los objetos que normalmente encontramos en un conjunto de datos de energía desagregado. A continuación se muestra un diagrama de clases UML que muestra todas las clases y las relaciones entre clases:

Un diamante negro oscuro indica una relación de «composición», mientras que un diamante hueco indica una «agregación». Por ejemplo, la relación entre Datasety Buildingse lee como ‘ cada conjunto de datos contiene cualquier número de edificios y cada edificio pertenece exactamente a un conjunto de datos ‘. Usamos diamantes huecos para indicar que los objetos de una clase se refieren a objetos de otra clase. Por ejemplo, cada Applianceobjeto se refiere exactamente a uno ApplianceType. Las instancias de las clases en el área sombreada de la izquierda están diseñadas para enviarse con cada conjunto de datos, mientras que los objetos de las clases de la derecha son comunes a todos los conjuntos de datos y se almacenan dentro del proyecto de metadatos NILM como los ‘metadatos centrales’. Algunos ApplianceTypescontienen Appliances, de ahí el cuadro que representa elAppliance class sobresale ligeramente en el área de ‘metadatos centrales’ a la derecha.
A continuación, usaremos ejemplos para ilustrar cómo crear un esquema de metadatos para un conjunto de datos.
Ejemplo simple
La siguiente ilustración muestra un diagrama de cableado de red de dibujos animados para un edificio doméstico. Las líneas negras indican cables de red. Esta casa tiene un suministro de red de fase dividida (común en América del Norte, por ejemplo). La lavadora extrae energía a través de ambas divisiones. Todos los demás electrodomésticos obtienen energía de una sola división.
El texto a continuación muestra una descripción minimalista (utilizando el esquema de metadatos NILM) del diagrama de cableado anterior. El YAML a continuación entraría en el archivo building1.yaml:
instancia : 1 # este es el primer edificio en el conjunto de datos
elec_meters : # un diccionario donde cada clave es un medidor instancia
1 :
site_meter : true # meter 1 mide el agregado de todo el edificio
2 :
site_meter : true
3 :
submeter_of : 1 # meter 3 está directamente aguas abajo del medidor 1
4 :
submeter_of : 1
5 :
submeter_of : 2
6 :
submeter_of : 2
7 :
submeter_of: 6
electrodomésticos :
- { tipo : hervidor , instancia : 1 , sala : cocina , medidores : [ 3 ]}
- { tipo : lavadora , instancia : 1 , medidores : [ 4 , 5 ]}
- { tipo : luz , instancia : 1 , sala : cocina , metros : [ 7 ]}
- { tipo : luz , instancia : 2 , múltiple : verdadero , metros : [ 6 ]}
elec_meterscontiene un diccionario de diccionarios. Cada clave es una instancia de medidor (un identificador entero único dentro del edificio). Comenzamos a numerar desde 1 porque eso es común en los conjuntos de datos existentes. Cada valor del elec_metersdict es un diccionario que registra información sobre ese medidor específico (consulte la documentación sobre el esquema de ElecMeter para obtener información completa). site_meterse establece en truesi este medidor mide la demanda de energía agregada de todo el edificio. submeter_ofregistra la instancia de medidor del medidor aguas arriba. De esta forma, podemos especificar jerarquías de cableado de complejidad arbitraria.
applianceses una lista de diccionarios. Cada diccionario describe un solo dispositivo. El aparato type(por ejemplo, «hervidor» o «lavadora») se toma de un vocabulario controlado definido en los metadatos de NILM. Consulte el esquema del dispositivo para obtener más información.
Para cada aparato, también debemos especificar un instance(un número entero que, dentro de cada edificio, nos permite distinguir entre múltiples instancias de un aparato en particular type). También debemos especificar una lista de meters. Cada elemento de esta lista es un número entero que corresponde a un metro instance. De esta manera, podemos especificar qué medidor está directamente aguas arriba de este aparato. La gran mayoría de los electrodomésticos solo especificará un medidor. Usamos dos metros para los electrodomésticos norteamericanos que obtienen energía de ambas conexiones de red. Usamos tres metros para electrodomésticos trifásicos.
Representar a REDD utilizando metadatos de NILM
El conjunto de datos de referencia de desagregación de energía (REDD) ( Kolter & Johnson 2011 ) fue el primer conjunto de datos públicos que se publicó para la comunidad de desagregación de energía. Consta de seis viviendas. Se mide la demanda de energía agregada de cada hogar y también se miden sus circuitos. REDD proporciona datos de baja frecuencia (período de muestreo de 3 segundos) y de alta frecuencia. Solo especificaremos los datos de baja frecuencia en este ejemplo.
Los metadatos NILM se pueden especificar como YAML o como metadatos dentro de un archivo binario HDF5. YAML probablemente sea mejor para la distribución con un conjunto de datos. NILMTK utiliza HDF5 para almacenar tanto los datos como los metadatos. Las estructuras de datos son muy similares sin importar si los metadatos están representados en el disco como YAML o HDF5. La principal diferencia es dónde se almacenan los metadatos. En este ejemplo, solo consideraremos YAML. Los archivos YAML se almacenan en un metadatadirectorio incluido con el conjunto de datos. Para obtener detalles sobre dónde se almacena esta información dentro de HDF5, consulte las secciones relevantes de la página de metadatos del conjunto de datos .
Primero especificaremos los detalles del conjunto de datos, luego los detalles sobre cada edificio.
Conjunto de datos
Usaremos el esquema del conjunto de datos para describir el nombre del conjunto de datos, los autores, la ubicación geográfica, etc. Si desea crear una descripción mínima de metadatos de un conjunto de datos, no necesita especificar nada para el Dataset.
Esta información se almacenaría en formato dataset.yaml.
Primero, especifiquemos el nombre del conjunto de datos y los creadores:
name : REDD long_name : The Reference Energy Disaggregation Creadores del conjunto de datos : - Kolter, Zico - Johnson, Matthew publicación_fecha : 2011 institución : Massachusetts Institute of Technology (MIT) contacto : [email protected] # Zico se trasladó de MIT a CMU descripción : Varias semanas de datos de energía para 6 hogares diferentes. Asunto : Demanda de energía desagregada de los edificios domésticos. number_of_buildings : 6 zona horaria : EE . UU. / Este # MIT está en la costa este geo_location : localidad : Massachusetts # aldea, pueblo, ciudad o estado país : EE . UU . # Código de país estándar de dos letras definido por ISO 3166-1 alpha-2 latitud : 42.360091 # Coorindates del MIT longitud : -71.09416 related_documents : - http://redd.csail.mit.edu - > J. Zico Kolter y Matthew J. Johnson. REDD: un conjunto de datos públicos para la investigación de desagregación de energía. En actas del taller SustKDD sobre aplicaciones de minería de datos en sostenibilidad, 2011. esquema : https://github.com/nilmtk/nilm_metadata/tree/v0.2
La tensión nominal de la red se puede deducir del geo_location:countryvalor.
Dispositivos de medición
A continuación, describimos las características comunes de cada tipo de medidor utilizado para registrar los datos. Consulte la sección de documentación sobre MeterDevice para obtener detalles completos. Puede pensar en esto como la ‘hoja de especificaciones’ suministrada con cada modelo de medidor utilizado para registrar el conjunto de datos. Esta información se almacenaría en formato meter_devices.yaml.
Esta estructura de datos es un gran diccionario. Cada clave es un nombre de modelo. Cada valor es un diccionario que describe el medidor:
eMonitor :
modelo : eMonitor
fabricante : Powerhouse Dynamics
fabricante_url : http://powerhousedynamics.com
descripción : >
Mide la demanda de potencia a nivel de circuito. Viene con 24 CT.
Esta página de preguntas frecuentes sugiere que el eMonitor mide la
potencia
real (activa) : http://www.energycircle.com/node/14103 aunque el readme.txt de
REDD dice que todos los canales registran la potencia aparente. sample_period : 3 # el intervalo entre muestras. En segundos.
max_sample_period : 50 # Intervalo máximo permitido entre muestras. Segundos.
medidas :
- physical_quantity : el poder # potencia, la tensión, la energía, la corriente?
tipo : activo # activo (potencia real), reactivo o aparente?
Upper_limit : 5000
lower_limit : 0
inalámbrico : falso
REDD_whole_house :
description : >
Medidor de potencia de bricolaje de REDD que se utiliza para medir formas
de
onda de CA en toda la casa a alta frecuencia. Para citar su artículo: "TC de TED (http://www.theenergydetective.com) para medir la corriente en la
red eléctrica, una sonda de osciloscopio Pico TA041
(http://www.picotechnologies.com) para medir el voltaje de una de
las dos fases en el hogar, y un
conversor analógico a digital
NI-9239 de National Instruments para transformar ambas señales
analógicas en lecturas digitales.Este conversor A / D tiene una resolución de
24 bits con ruido de aproximadamente 70 µV, que determina el nivel de ruido de nuestras lecturas de corriente y voltaje: los TED CTs
están clasificados para circuitos de 200 amperios y un máximo de 3 voltios, por lo que podemos
diferenciar entre corrientes de aproximadamente
((200)) (70 × 10−6) / (3) = 4,66 mA, correspondientes a cambios
de
potencia de aproximadamente 0,5 vatios. Del mismo modo, puesto que utilizamos un 1: 100 de tensión de escalón de descenso en la sonda del osciloscopio, podemos detectar tensión
diferencias de unos 7mV ".
Sample_period : 1
max_sample_period : 30
mediciones :
- physical_quantity : potencia
tipo : aparente
UPPER_LIMIT : 50000
LOWER_LIMIT : 0
inalámbrica : falsa
Edificios, contadores de electricidad y electrodomésticos
Finalmente, necesitamos especificar metadatos para cada edificio en el conjunto de datos. La información sobre cada contador de electricidad y cada aparato se especifica junto con el edificio. Los metadatos de cada edificio entran donde i es un número entero que comienza en 1. Por ejemplo,building<i>.yamlbuilding1.yaml
Describiremos house_1desde REDD. Primero, describimos la información básica sobre el house_1uso del esquema de construcción :
instancia : 1 # este es el primer edificio en el conjunto de datos original_name : house_1 # nombre original del conjunto de datos REDD elec_meters : # ver abajo aparatos : # ver abajo
Ahora sabemos la ubicación geográfica específica de house_1en REDD. Como tal, podemos asumir que house_1solo ‘heredará’ geo_locationy timezonede los datasetmetadatos. Si supiéramos la ubicación geográfica de house_1entonces podríamos especificarlo en building1.yaml.
A continuación, especificamos cada contador de electricidad y el cableado entre los contadores utilizando el esquema ElecMeter . elec_meterses un diccionario. Cada clave es una instancia de medidor. Cada valor es un diccionario que describe ese medidor. Para ser breve, no mostraremos todos los medidores:
elec_meters :
1 :
site_meter : true
device_model : REDD_whole_house # claves en el diccionario
meter_devices data_location : house_1 / channel_1.dat
2 :
site_meter : true
device_model : REDD_whole_house
data_location : house_1 / channel_2.dat
3 :
submeter_of : 0 # '0' significa 'uno de los site_meters '. No sabemos
# qué medidor de sitio alimenta qué dispositivo en REDD.
device_model : eMonitor
data_location : house_1 / channel_3.dat
4 :
submeter_of : 0
device_model : eMonitor
data_location : house_4 / channel_4.dat
También podríamos especificar atributos como, pero ninguno de estos es relevante para REDD.room, floor, preprocessing_applied, statistics, upstream_meter_in_building
Ahora podemos especificar qué electrodomésticos se conectan a qué medidores.
Para referencia, aquí es el original labels.datde house_1REDD:
1 red 2 red 3 horno 4 horno 5 frigorífico 6 lavavajillas 7 salidas_cocina 8 salidas_cocina 9 iluminación 10 lavadora_secadora 11 microondas 12 baño_gfi 13 calefacción_eléctrica 14 estufa 15 salidas_cocina 16 salidas_cocina 17 iluminación 18 iluminación 19 lavadora_secadora 20 lavadora_secadora
Usamos el esquema de dispositivo para especificar dispositivos. En REDD, todos los medidores miden circuitos usando pinzas de TC en la caja de fusibles de las casas. Algunos circuitos suministran energía a electrodomésticos individuales . Otros circuitos suministran energía a grupos de electrodomésticos.
appliances es una lista de diccionarios.
Comencemos demostrando cómo describimos los circuitos que suministran energía a un aparato individual:
electrodomésticos : - tipo : nevera instancia : 1 metros : [ 5 ] original_name : nevera
Recuerde del ejemplo simple que el valor de dispositivo typese toma del vocabulario controlado por metadatos de NILM de tipos de dispositivo. original_namees el nombre utilizado en REDD, antes de la conversión al vocabulario controlado por metadatos NILM.
Ahora especificamos dos aparatos de 240 voltios. Los hogares norteamericanos tienen suministros de red de fase dividida. Cada división es de 120 voltios en relación con el neutro. Las dos divisiones son de 240 voltios entre sí. Los electrodomésticos grandes pueden conectarse a ambas divisiones para consumir mucha energía. REDD mide por separado ambas divisiones para estos electrodomésticos grandes, por lo que especificamos dos medidores por dispositivo de 240 voltios:
electrodomésticos :
- Tipo : horno eléctrico de
ejemplo : 1
metros : [ 3 , 4 ] # el horno obtiene la energía de ambas piernas 120 voltios
original_name : horno
- original_name : washer_dryer
tipo : lavadora secadora
ejemplo : 1
metros : [ 10 , 20 ]
componentes : # podemos especificar qué componentes se conectan a la que la pierna
- Tipo : motor
metros : [ 10 ]
- Tipo : elemento de calentamiento eléctrico
metros : [ 20 ]
Ahora especificamos cargas que no son dispositivos individuales sino que son categorías de dispositivos:
electrodomésticos :
- original_name : kitchen_outlets
room : kitchen
type : sockets # sockets se trata como una
instancia de electrodoméstico : 1
multiple : true # probablemente más de 1 socket
metros : [ 7 ]
- original_name : kitchen_outlets
habitación : cocina
tipo : sockets
instancia : 2 # 2da instancia de 'sockets' en este edificio
multiple : true # probablemente más de 1 socket
metros : [ 8 ]
- nombre_original : tipo de iluminación
: instancia de luz : 1 múltiplo : verdadero # es probable que tenga más de 1 metro de luz : [ 9 ]
- nombre_original : tipo de iluminación
: instancia de luz : 2 # 2da instancia de 'luz' en este edificio multiple : metros verdaderos : [ 17 ]
- nombre_original : tipo de iluminación
: instancia de luz : 3 # 3ra instancia de 'luz' en este edificio multiple : metros verdaderos : [ 18 ]
- nombre_original : baño_gfi # interruptor de falla a tierra
habitación : baño
tipo : instancia desconocida
: 1 múltiplo : medidores verdaderos : [ 12 ]
Tenga en cuenta que si tenemos varias instancias distintas del mismo tipo de dispositivo, entonces debemos usar objetos de dispositivo separados para cada instancia y no debemos agruparlos como un único objeto de dispositivo con varios meters. Solo especificamos múltiples meterspor appliancesi hay un solo aparato que obtiene energía de más de una fase o línea de alimentación.
En REDD, las casas 3, 5 y 6 también tienen un electronicscanal. ¿Cómo manejaríamos esto en NILM Metadata? Este es un medidor que no registra un solo aparato, pero registra una categoría de aparatos. Afortunadamente, debido a que NILM Metadata usa una estructura de herencia para los metadatos centrales, ya tenemos un (CE = Consumer Electronics). El objeto se construyó primero para actuar como una superclase abstracta para todos los objetos de electrónica de consumo, pero resulta útil para REDD:CE applianceCE appliance
- nombre_original : tipo de electrónica : instancia de dispositivo CE : 1 múltiplo : medidores verdaderos : [ 6 ]
Hemos visto cómo representar el conjunto de datos REDD utilizando Metadatos NILM. El ejemplo anterior muestra la mayor parte de la estructura del esquema de metadatos NILM para conjuntos de datos. Hay muchos más atributos que se pueden adjuntar a esta estructura básica. Consulte la documentación de metadatos del conjunto de datos para obtener detalles completos de todos los atributos y valores que se pueden usar.
Metadatos centrales
Una segunda parte del proyecto de metadatos NILM son los ‘metadatos centrales’. Estos ‘metadatos centrales’ se almacenan en el propio proyecto de metadatos NILM y consisten en información como la asignación del tipo de dispositivo a la categoría del dispositivo; y la asignación del código de país a los valores de voltaje nominal.
Metadatos del conjunto de datos
Esta página describe el esquema de metadatos para describir un conjunto de datos.
Hay dos formatos de archivo para los metadatos: YAML y HDF5. Los archivos de metadatos YAML deben estar en una metadatacarpeta. Cada sección de este documento comienza describiendo dónde se almacenan los metadatos relevantes en ambos formatos de archivo.
Conjunto de datos
Este objeto describe aspectos sobre todo el conjunto de datos. Por ejemplo, el nombre del conjunto de datos, los autores, la ubicación geográfica de todo el conjunto de datos, etc.
- Ubicación en YAML:
dataset.yaml - Ubicación en HDF5:
store.root._v_attrs.metadata
Atributos de metadatos (algunos de estos atributos están adaptados de Dublin Core Metadata Initiative (DCMI)):
| nombre: | (cadena) (obligatorio) Nombre corto del conjunto de datos. por ejemplo, ‘REDD’ o ‘UK-DALE’. El elemento DCMI equivalente es ‘título’. Si este conjunto de datos es el resultado de un algoritmo de desagregación, el nombre se establecerá en un nombre corto para el algoritmo; por ejemplo, ‘CO’ o ‘FHMM’. |
|---|---|
| nombre largo: | (cadena) Nombre completo del conjunto de datos, p. ej. ‘Conjunto de datos de desagregación de energía de referencia’. |
| creadores: | (lista de cadenas) en el formato ‘<Último nombre>, <Nombre inicial>’. Elemento DCMI. |
| zona horaria: | (cadena) Utilice el nombre de TZ estándar de la base de datos de zona horaria de IANA (también conocida como Olson), por ejemplo, ‘América / New_York’ o ‘Europa / Londres’. |
| fecha: | (cadena) Formato ISO 8601. por ejemplo, ‘2014-06-23’ Idéntico al elemento DCMI de ‘fecha’. |
| contacto: | (cadena) Dirección de correo electrónico |
| institución: | (cuerda) |
| descripción: | (cadena) Elemento DCMI. Breve descripción legible por humanos. por ejemplo, describa la frecuencia de muestreo, la ubicación geográfica, etc. |
| número_de_edificios: | |
| (En t) | |
| identificador: | (cadena): un identificador de objeto digital (DOI) o URI para el conjunto de datos. Elemento DCMI. |
| tema: | (cadena): Por ejemplo, ¿este conjunto de datos se refiere a edificios domésticos o comerciales? ¿Incluye datos desglosados dispositivo por dispositivo o solo datos de todo el edificio? Elemento DCMI. Texto libre legible por humanos. |
| cobertura_espacial: | |
| (cadena): Cobertura espacial. por ejemplo, «Sur de Inglaterra». Relacionado con el elemento DCMI de ‘cobertura’. Texto libre legible por humanos. | |
| periodo de tiempo: | ( TimeFrame , ver más abajo) Fechas de inicio y finalización para todo el conjunto de datos. |
| fondos: | (lista de cadenas) Una lista de todas las fuentes de financiación utilizadas para producir este conjunto de datos. |
| editor: | (cadena) La entidad responsable de hacer que el recurso esté disponible. Los ejemplos de un editor incluyen una persona, una organización o un servicio. Elemento DCMI. |
| geo_location: | (dictar)localidad:(cadena) aldea, pueblo, ciudad o estadopaís:(cadena) Utilice un código de país estándar de dos letras definido por ISO 3166-1 alpha-2 . por ejemplo, «GB» o «EE. UU.».latitud:(número)longitud:(número) |
| lista_derechos: | (lista de dictados) Licencia (s) bajo las cuales este conjunto de datos esliberado. Relacionado con el elemento DCMI de ‘derechos’. Cada elemento tiene estos atributos:uri:(cadena) URI de licencianombre:(cadena) Nombre de la licencia |
| description_of_subjects: | |
| (cadena) Una breve descripción de cómo se reclutaron los sujetos. ¿Son todos estudiantes de doctorado, por ejemplo? ¿Fueron incentivados a reducir su consumo de energía? ¿Cómo fueron elegidos? | |
| documentos relacionados: | |
| (lista de cadenas) Referencias sobre este conjunto de datos (por ejemplo, referencias a artículos académicos o páginas web). También describa brevemente el contenido de cada referencia (por ejemplo, ¿contiene una descripción de la configuración de medición? ¿O un análisis de los datos?) Relacionado con el elemento DCMI de ‘relación’. | |
| esquema: | (cadena) La URL de la versión (etiqueta) de NILM_metadata con la que se validan estos metadatos. por ejemplo, https://github.com/nilmtk/nilm_metadata/tree/v0.2 |
MeterDevice
Metadatos que describen cada modelo de medidor utilizado en el conjunto de datos. (Tenga en cuenta que ElecMeter se usa para representar instancias individuales de medidores en un edificio, mientras que MeterDevicese usa para representar información común a todas las instancias de una marca y modelo específico de medidor). Piense en esta sección como un catálogo de modelos de medidores utilizados en el conjunto de datos.
- Ubicación en YAML:
meter_devices.yaml - Ubicación en HDF5:
store.root._v_attrs.metadataenmeter_devices
Un gran dict. Las claves son nombres de modelo de dispositivo (por ejemplo, ‘EnviR’). El propósito es registrar información sobre modelos específicos de medidor. Los valores son dictados con estas claves:
| modelo: | (cadena) (obligatorio) El nombre del modelo de este dispositivo medidor. |
|---|---|
| model_url: | (cadena) La URL con más información sobre este modelo de medidor. |
| fabricante: | (cuerda) |
| fabricante_url: | |
| (cuerda) | |
| sample_period: | (número) (obligatorio) El período de muestreo nominal del medidor (es decir, el período de tiempo entre muestras consecutivas) en segundos. |
| período_máximo_muestra: | |
(número) (obligatorio) El tiempo máximo permitido entre muestras consecutivas. Suponemos que el medidor está apagado durante cualquier intervalo superior a max_sample_period. En otras palabras, definimos un «espacio» como dos muestras cualesquiera que estén más que max_sample_periodseparadas. | |
| mediciones: | (lista) (obligatorio) El orden es el orden de las columnas en la tabla de datos.cantidad física: (cadena) (obligatorio) Uno de {‘potencia’, ‘energía’, ‘energía acumulada’, ‘voltaje’, ‘corriente’, ‘frecuencia’, ‘factor de potencia’, ‘estado’, ‘ángulo de fase’, ‘total distorsión armónica ‘,’ temperatura ‘}. Las columnas de ‘estado’ almacenan un ID de estado entero donde 0 está apagado y> 0 se refiere a estados definidos. (TODO: almacenar el mapeo de la identificación del estado por dispositivo al nombre del estado). Unidades: ángulo de fase: grados; potencia: vatios; energía: kWh; voltaje: voltios; corriente: amperios; temperatura: grados centígrados.escribe:(cadena) (requerido para ‘potencia’ y ‘energía’) Tipo de corriente alternativa (CA). Uno de {‘reactivo’, ‘activo’, ‘aparente’}.limite superior:(número)límite inferior:(número) |
| descripción: | (cuerda) |
| pagar por adelantado: | (booleano) ¿Es este un medidor de prepago? |
| inalámbrico: | (booleano) |
| configuración_inalámbrica: | |
| (dict) Todas las cadenas son texto libre legible por humanos:base:(cadena) Descripción de la estación base utilizada. Fabricante, modelo, versión, etc.protocolo:(cadena) por ejemplo, ‘zibgee’, ‘WiFi’, ‘personalizado’. Si es personalizado, agregue un enlace a la documentación si está disponible.Frecuencia de carga: (número) MHz | |
| registrador de datos: | (cadena) Descripción del registrador de datos utilizado |
Edificio
- Ubicación en YAML:
building<I>.yaml - Ubicación en HDF5:
store.root.building<I>._v_attrs.metadata
| ejemplo: | (int) (obligatorio) La instancia de construcción en este conjunto de datos, comenzando desde 1 |
|---|---|
| nombre original: | (cadena) Nombre original del edificio a partir de metadatos antiguos (metadatos anteriores a NILM). |
| medidores_electricos: | (dictado de dictados) (obligatorio) Cada clave es un número entero (> = 1) que representa la instancia del medidor en este edificio. Cada valor es un ElecMeter. Consulte la sección a continuación sobre ElecMeter . |
| accesorios: | (lista de dictados) (obligatorio) Consulte la sección a continuación sobre el aparato . |
| medidores de agua: | (dictado de dictados) Misma estructura que elec_meters. |
| medidores_gás: | (dictado de dictados) Misma estructura que elec_meters. |
| descripción: | (cuerda) |
| habitaciones: | (lista de dictados):nombre:(cadena) (obligatorio) uno de {‘salón’, ‘cocina’, ‘dormitorio’, ‘lavadero’, ‘garaje’, ‘sótano’, ‘baño’, ‘estudio’, ‘guardería’, ‘pasillo’, ‘ comedor ‘,’ al aire libre ‘}ejemplo:(int) (opcional. Empieza desde 1. Si está ausente, se supone que es 1.)descripción:(cuerda)suelo:(int) La planta baja es el piso 0. |
| n_ocupantes: | (int) Modo número de ocupantes. |
| description_of_occupants: | |
| (cadena) texto libre que describe a los ocupantes. ¿Número de niños, adolescentes, adultos, jubilados? ¿Demografía? ¿Estuvieron todos los ocupantes fuera de la casa durante todos los días de la semana? | |
| periodo de tiempo: | ( TimeFrame , ver más abajo) |
| periodos_unoccupied: | |
| (lista de objetos TimeFrame , ver más abajo) Períodos en los que este edificio estuvo vacío durante más de un día (por ejemplo, días festivos) | |
| año de construcción: | |
| (int) Año calendario de construcción de cuatro dígitos. | |
| mejoras_energéticas: | |
| (lista de cadenas) ¿Alguna modificación posterior a la construcción? Alguna combinación de {‘fotovoltaica’, ‘solar térmica’, ‘aislamiento de paredes huecas’, ‘aislamiento de loft’, ‘aislamiento de paredes sólidas’, ‘doble acristalamiento’, ‘acristalamiento secundario’, ‘triple acristalamiento’} | |
| calefacción: | (lista ordenada de cadenas, con el combustible más dominante primero) Alguna combinación de {‘gas natural’, ‘electricidad’, ‘carbón’, ‘madera’, ‘biomasa’, ‘petróleo’, ‘GLP’} |
| caldera_comunal: | |
| booleano (establecido en verdadero si la calefacción es proporcionada por una caldera compartida para los apartamentos) | |
| propiedad: | (cadena) uno de {‘alquilado’, ‘comprado’} |
| tipo de construcción: | (cadena) uno de {‘bungalow’, ‘casa de campo’, ‘independiente’, ‘final de la terraza’, ‘plano’, ‘adosado’, ‘terraza intermedia’, ‘residencias de estudiantes’, ‘fábrica’, ‘ oficina ‘,’ universidad ‘} |
Construyendo metadatos que se heredan de Dataset pero que pueden ser anulados por Building:
- geo_location
- zona horaria
- periodo de tiempo
ElecMeter
Los ElecMeters son los valores del elec_metersdictado de cada edificio (consulte la sección sobre metadatos del edificio más arriba).
| device_model: | (cadena) (obligatorio) modelque ingresameter_devices |
|---|---|
| submeter_of: | (int) (requerido) la instancia de medidor del medidor aguas arriba. O configúrelo para 0que signifique » uno de los site_meters «. En la práctica, 0se interpretará como “aguas abajo de un ‘Grupo de medidores’ que representa todos los medidores del sitio sumados”. |
| submeter_of_is_uncertain: | |
| (booleano) Se establece en verdadero si el valor de submeter_of es incierto. | |
| upstream_meter_in_building: | |
| (int) Si el medidor de aguas arriba está en un edificio diferente, especifique aquí esa instancia de edificio. Si se deja en blanco, asumimos que el medidor de aguas arriba está en el mismo edificio que este medidor. | |
| site_meter: | (booleano): requerido y establecido en Verdadero si se trata de un medidor de sitio (es decir, el medidor más alejado aguas arriba) de lo contrario no es necesario. Si hay varias fases de red (por ejemplo, red trifásica) o múltiples ‘divisiones’ de red (por ejemplo, en América del Norte, donde hay dos divisiones de 120 voltios), configure site_meter=trueen cada medidor del sitio. Se deben configurar todos los medidores que no sean del sitio directamente aguas abajo de los medidores del sitio submeter_of=0. Opcionalmente, utilice también phasepara describir qué fase mide este medidor. ¿Qué sucede si hay varios medidores de sitio en paralelo?(es decir, hay contadores redundantes)? Por ejemplo, tal vez haya un medidor de sitio instalado por la empresa de servicios públicos que proporciona lecturas poco frecuentes; y también hay un elegante medidor de sitio digital que mide en el mismo punto en el árbol de cableado y, por lo tanto, en cierto sentido, el medidor de servicios públicos puede considerarse ‘redundante’ pero se incluye en el conjunto de datos para la comparación). En esta situación, configure site_meter=trueen cada medidor de sitio. A continuación, configure disabled=truetodos menos el medidor de sitio «favorecido» (que normalmente sería el medidor de sitio que proporciona las «mejores» lecturas). Es importante configurarlo de disabled=truemanera que NILMTK no sume los medidores de sitios paralelos. Los medidores de sitio deshabilitados también deben configurarse submeter_ofcon el ID del medidor de sitio habilitado. Se deben configurar todos los medidores que no sean del sitio directamente aguas abajo de los medidores del sitio submeter_of=0. |
| medidor_de_servicio: | (booleano) requerido y establecido en Verdadero si este medidor fue instalado por la empresa de servicios públicos. De lo contrario, no es necesario. |
| periodo de tiempo: | ( Objeto TimeFrame ) |
| nombre: | (cadena) (opcional) p. ej., ‘total del primer piso’. |
| fase: | (int o string) (opcional) Se usa en configuraciones de múltiples fases. |
| habitación: | (cuerda) . por ejemplo, «cocina» o «dormitorio, 2». Si no se especifica (p. Ej., ‘Habitación: cocina’, se asume que es ‘cocina, 1’ (es decir, instancia de cocina 1). Si los metadatos del edificio especifican un conjunto de , la habitación especificada aquí se introducirá en la del edificio (pero no en todos). Los conjuntos de datos enumeran todas las habitaciones de cada edificio).<room name>[,<instance>]instanceroomsrooms |
|---|---|
| suelo: | (int) No es necesario si roomse especifica. Planta baja es 0. |
| ubicación_de_datos: | (cadena) (obligatorio) Ruta relativa al directorio raíz del conjunto de datos. ej house1/channel_2.dat. Tablas de referencia y columnas dentro de un archivo jerárquico, por ejemplo data.h5?table=/building1/elec/meter1, o, si estos metadatos se almacenan en el mismo archivo HDF que los datos del sensor, simplemente use la clave, por ejemplo /building1/elec/meter1. |
| discapacitado: | (bool): se establece en verdadero si NILMTK debe ignorar este canal. Esto es útil si, por ejemplo, este canal es un site_meter redundante. |
| preprocessing_applied: | |
| (dict): cada tecla es opcional y solo está presente si se ha ejecutado esa función de preprocesamiento.acortar:(dictar)límite inferior:limite superior: | |
| Estadísticas: | (lista de dictados): cada dictado describe estadísticas para un conjunto de períodos de tiempo. Cada dictado tiene:marcos de tiempo:(lista de objetos TimeFrame ) (obligatorio) Los plazos sobre los que se calcularon estas estadísticas. Si las estadísticas se refieren a la serie temporal completa, ingrese el inicio y el final de la serie temporal como el único TimeFrame.buenas_secciones:(lista de objetos TimeFrame )contiguous_sections: (lista de objetos TimeFrame )energía_total:(dic) kWhactivo:(número)reactivo:(número)aparente:(número)Tenga en cuenta que algunas de estas estadísticas se almacenan en caché por NILMTK en building<I>/elec/cache/meter<K>/<statistic_name>. Para obtener más detalles, consulte la cadena de documentación de nilmtk.ElecMeter._get_stat_from_cache_or_compute(). |
WaterMeter y GasMeter
Mismos atributos que ElecMeter .
Aparato
Cada dictado de aparato tiene:
| escribe: | (cadena) (obligatorio) tipo de aparato (p. ej., «hervidor»). Utilice vocabulario controlado por metadatos NILM. Consulte nilm_metadata / central_metadata / appliance_types / *. Yaml . Cada *.yamlarchivo nilm_metadata/central_metadata/appliance_typeses un diccionario grande. Cada clave de estos diccionarios es un dispositivo legal type. |
|---|---|
| ejemplo: | (int a partir de 1) (obligatorio) instancia de este electrodoméstico dentro del edificio. |
| metros: | (lista de ints) (requerido) instancias de medidor directamente aguas arriba de este aparato. Esta es una lista para manejar el caso en el que algunos electrodomésticos obtienen energía de ambas patas de 120 voltios en una casa de América del Norte. O electrodomésticos trifásicos. |
| dispositivo_dominante: | |
| (booleano) (obligatorio si hay varios aparatos conectados a un medidor). ¿Este aparato es responsable de la mayor parte de la demanda de energía en este medidor? | |
| on_power_threshold: | |
| (número) vatios. No requerido. El valor predeterminado se toma del tipo de dispositivo . El umbral (en vatios) que se utiliza para decidir si el dispositivo está encendido o apagado . | |
| máximo poder: | (número) vatios. No requerido. |
| min_off_duration: | |
| (número) (segundos) No es necesario. | |
| min_on_duration: | |
| (número) (segundos) No es necesario. | |
| habitación: | ver ElecMeter-room |
| múltiple: | (booleano) Verdadero si hay más de uno de estos dispositivos representados por este único applianceobjeto. Si hay exactamente un dispositivo, no lo especifique multiple. |
| contar: | (int) Si hay más de uno de estos dispositivos representados por este applianceobjeto y si se conoce el número exacto de dispositivos, especifique ese número aquí. |
| control: | (lista de cadenas) Proporcione una lista de todos los métodos de control que se aplican. Por ejemplo, una grabadora de video sería tanto «manual» como «temporizador». El vocabulario es: {‘temporizador’, ‘manual’, ‘movimiento’, ‘luz del sol’, ‘termostato’, ‘siempre encendido’} |
| clasificación_eficiencia: | |
| (dic):Nombre de certificacion: (cadena) por ejemplo, ‘SEDBUK’ o ‘Energy Star 5.0’clasificación:(cadena) por ejemplo, ‘A +’ | |
| consumo_nominal: | |
| (dict): Especificaciones informadas por el fabricante.en el poder:(número) potencia activa en vatios cuando está encendido.energía de reserva:(número) potencia activa en vatios cuando está en espera.energía_por_año: (número) kWh por añoenergía_por_ciclo: (número) kWh por ciclo | |
| componentes: | (lista de dictados): componentes de este aparato. Cada dict es un dict de Appliance. |
| modelo: | (cuerda) |
| fabricante: | (cuerda) |
| marca: | (cuerda) |
| nombre original: | (cuerda) |
| model_url: | (cadena) URL para este modelo de dispositivo |
| fabricante_url: | |
| (cadena) URL del fabricante | |
| fechas_activas: | (lista de objetos TimeFrame , ver más abajo) Puede usarse para especificar un cambio en el dispositivo a lo largo del tiempo (por ejemplo, si un dispositivo se reemplaza por otro). |
| año_de_compra: | |
| (int) Año de cuatro dígitos. | |
| año de fabricación: | |
| (int) Año de cuatro dígitos. | |
| subtipo: | (cuerda) |
| número de pieza: | (cuerda) |
| gtin: | (int) http://en.wikipedia.org/wiki/Global_Trade_Item_Number |
| versión: | (cuerda) |
| portátil: | (booleano) |
Se especifican propiedades adicionales para algunos tipos de dispositivos. Busque objetos en nilm_metadata/central_metadata/appliances/*.yamlpara obtener más detalles.
Cuando un objeto Appliance se usa como componente de un ApplianceType, entonces el objeto Appliance puede tener un distributionsdict (ver ApplianceType:distributionsen Metadatos del dispositivo central ) especificado y también puede usar una propiedad que evita que el sistema fusione categorías del componente en el dispositivo contenedor.do_not_merge_categories: true
Periodo de tiempo
Representa un marco de tiempo arbitrario. Si el inicio o el final están ausentes, suponga que es igual al inicio o al final del conjunto de datos, respectivamente. Utilice el formato ISO 8601 para fechas o fechas (por ejemplo, 2014-03-17 o 2014-03-17T21: 00: 52 + 00: 00)
| comienzo: | (cuerda) |
|---|---|
| fin: | (cuerda) |
Metadatos del dispositivo central
Herencia
- herencia protípica; como JavaScript
- los dictados se actualizan; las listas se amplían; otras propiedades se sobrescriben
- profundidad de herencia arbitraria
Componentes
- recursivo
- Las categorías de dispositivo contenedor se actualizan con categorías de cada componente (a menos que se establezca en el componente)
do_not_merge_categories: true
Subtipos frente a un nuevo objeto secundario
Los objetos de especificación de dispositivo pueden tomar una propiedad de ‘subtipo’. ¿Por qué no utilizar la herencia para todos los subtipos? La regla general es que si un subtipo es funcionalmente diferente a su padre, entonces debe especificarse como un objeto independiente o secundario (por ejemplo, una encimera de gas y una encimera eléctrica claramente tienen perfiles de consumo de electricidad radicalmente diferentes) pero si las diferencias son menor (por ejemplo, una radio digital frente a una radio analógica), los aparatos deben especificarse como subtipos del mismo objeto.
Convenciones de nombres
- las propiedades están en minúsculas con guiones bajos, por ejemplo, subtipo
- los nombres de los objetos (no marcas y modelos específicos) están en minúsculas con espacios, a menos que sean acrónimos, en cuyo caso están en mayúsculas (por ejemplo, ‘LED’)
- los nombres de las categorías están en minúsculas con espacios
Ejemplo
Para demostrar el sistema de herencia, veamos cómo especificar una caldera.
Primero, NILM Metadata especifica un objeto de ‘aparato de calefacción’, que se puede considerar la ‘clase base’:
aparato de calefacción :
padre : categorías de aparato
: tradicional : tamaño de calefacción : grande
A continuación, especificamos un objeto ‘caldera’, que hereda de ‘aparato de calefacción’:
# ------------- CALDERAS ------------------------
caldera : # todas las calderas excepto las calderas eléctricas
padre : aparato de calefacción
sinónimos : [ horno ]
# Las categorías del objeto hijo se agregan
# a las categorías existentes en el padre.
categorías :
google_shopping :
- climatización
- hornos y calderas
# Aquí especificamos que las calderas tienen un componente
# que es en sí mismo un objeto cuyo padre
# es "bomba de agua".
componentes :
- tipo : bomba de agua
# Las calderas tienen una propiedad que la mayoría de los demás aparatos
# no tienen: una fuente de combustible. Especificamos
propiedades #
adicionales usando la sintaxis de esquema JSON. additional_properties :
fuel :
enum : [ gas natural , carbón , madera , petróleo , GLP ]
subtipos :
- combi
- regular
# Podemos especificar los diferentes mecanismos que
# controlan la caldera. Esto es útil, por ejemplo,
# si queremos encontrar todos los aparatos que
# deben controlarse manualmente (por ejemplo, tostadoras)
control : [ manual , temporizador , termostato ]
# También podemos declarar conocimientos previos sobre calderas.
# Por ejemplo, sabemos que las calderas tienden a estar en
# baños, lavaderos o cocinas
distribuciones :
habitación :
distribución_de_datos :
categorías : [ baño , servicios públicos , cocina ]
valores : [ 0.3 , 0.2 , 0.2 ]
# Si los valores no suman a 1 entonces el supuesto
# es que la masa de probabilidad restante se distribuye igualmente a
# todas las demás habitaciones.
fuente : subjetivo # ¡Estos valores son básicamente conjeturas!
Finalmente, en los metadatos del conjunto de datos en sí, podemos hacer:
tipo : caldera fabricante : Worcester modelo : Greenstar 30CDi convencional de gas natural habitación : baño year_of_purchase : 2011 combustible : gas natural subtipo : regulares part_number : 41-311-71 efficiency_rating : certification_name : SEDBUK calificación : Un nominal_consumption : on_power : 70
Detalles del esquema
A continuación se muestra un diagrama de clases UML que muestra todas las clases y las relaciones entre clases:
A continuación describimos todas las clases y sus atributos y posibles valores.
ApplianceType
Tiene muchos de los atributos que tiene Appliance , además de:
- on_power_threshold
- min_off_duration
- min_on_duration
- control
- componentes
| padre: | (cadena) Nombre del objeto ApplianceType principal del que hereda este objeto. |
|---|---|
| categorías: | (dictar)tradicional:(enumeración) uno de {húmedo, frío, electrónica de consumo, TIC, cocina, calefacción}Talla:(enumeración) uno de {small, large}eléctrico:(lista de cadenas) Cualquier combinación de:iluminación, incandescente, fluorescente, compacta, lineal, LEDresistadorelectrónica de potenciaSMPS, sin PFC, PFC pasivo, PFC activomotor de inducción monofásico, arranque-marcha del condensador, par constantemisceláneo:(enumeración) uno de {misc, sockets}google_shopping: (lista de cadenas) cualquier cosa del esquema de Google Shopping. por ejemplo: control de clima ‘,’ hornos y calderas ‘,’ energía renovable ‘,’ energía solar ‘,’ paneles solares ‘,’ computadoras ‘,’ electrónica ‘,’ computadoras portátiles ‘,’ impresoras y fotocopiadoras ‘,’ impresión, copia, escanear y enviar por fax ‘,’ impresoras ‘,’ aparatos de lavandería ‘,’ cocina y comedor ‘,’ aparatos de cocina ‘,’ panificadoras ‘ |
| subtipos: | (lista de cadenas) Una lista de todos los subtipos válidos. |
| propiedades_adicionales: | |
| (dict) Se utiliza para especificar propiedades adicionales que se pueden especificar para dispositivos de este tipo de dispositivo. Cada llave es una propiedad. Cada valor es una definición de esquema JSON de la propiedad. | |
| do_not_inherit: | (lista de cadenas) propiedades que no deben heredarse del padre. |
| sinónimos: | (lista de cadenas) |
| componentes_usuales: | |
| (lista de cadenas) Solo una lista de sugerencias para lectores humanos. | |
| n_ancestros: | (int) Completado por _concatenate_complete_object. |
| distribuciones: | (dict) Distribución de variables aleatorias.en el poder:(lista de objetos anteriores ) bin_edges en unidades de vatioson_duration:(lista de objetos anteriores ) bin_edges en unidades de segundosoff_duration:(lista de objetos anteriores ) bin_edges en unidades de segundosuso_hora_por_día: (lista de objetos anteriores ) bin_edges = [0,1,2,…, 24]uso_día_por_semana: (lista de objetos anteriores ) categorías = [‘mon’, ‘tue’,…, ‘sun’]use_month_per_year: (lista de objetos anteriores ) bin_edges están en unidades de días (necesitamos los bordes de bin porque los meses no tienen la misma longitud). El primer contenedor representa enero.habitaciones:(lista de objetos anteriores ) Distribución categórica en las habitaciones donde es probable que se utilice este aparato. Por ejemplo, para un frigorífico, podría ser «cocina: 0,9, garaje: 0,1». Utilice los nombres de habitación estándar definidos en room.json (los nombres de categoría en las distribuciones no se validan automáticamente).subtipos:(lista de objetos anteriores ) Distribución categórica sobre los subtipos.correlaciones_de_dispositivo: (lista de objetos anteriores ) lista de otros aparatos. Probabilidad de que este aparato esté encendido dado que el otro aparato está encendido. Por ejemplo, ‘ tv: 0.1 , amp: 0.4,…’ significa que hay un 10% de probabilidad de que este aparato esté encendido si el televisor está encendido. El nombre de cada categoría puede ser solo un nombre de dispositivo (p. Ej., ‘Nevera’) o <nombre de dispositivo>, <instancia de dispositivo> p. Ej., ‘Nevera, 1’propiedad_por_país: (lista de objetos anteriores ) Probabilidad de que este electrodoméstico sea propiedad de un hogar en cada país (es decir, una distribución categórica donde las categorías son el código de país estándar de dos letras definido por ISO 3166-1 alfa-2. Por ejemplo, ‘GB’ o ‘EE. UU.’ . http://en.wikipedia.org/wiki/ISO_3166-1_alpha-2 ). Si la probabilidad se refiere a todo el mundo, utilice «GLOBAL» como código de país.propiedad_por_continente: (lista de objetos anteriores ) Probabilidad de que este electrodoméstico sea propiedad de un hogar en cada país (es decir, una distribución categórica donde las categorías son el código de continente estándar de dos letras definido en http://en.wikipedia.org/wiki/List_of_sovereign_states_and_dependent_territories_by_continent_%28data_file% 29 |
|---|
País
Un gran dict que especifica información específica del país. Especificado ennilm_metadata/central_metadata/country.yaml
Cada clave es un ‘país’ (cadena). Utilice un código de país estándar de dos letras definido por ISO 3166-1 alpha-2 . por ejemplo, «GB» o «EE. UU.».
Cada valor es un dict con los siguientes atributos:
| tensión_de_ red: | (dic):nominal:(número) (requerido) voltioslimite superior:(número) voltioslímite inferior:(número) voltiosdocumentos relacionados: (lista de cadenas) |
|---|
Previo
Representar conocimientos previos. Para las variables continuas, especifique la distribución de los datos (es decir, los datos representados en un histograma) o una estimación de densidad (un modelo ajustado a los datos), o ambos. Para las variables categóricas, especifique la distribución categórica.
| distribución_de_datos: | |
|---|---|
| (dict) Distribución de los datos expresados comofrecuencias normalizadas por intervalo discreto (para variables continuas) o por categoría (para variables categóricas). Se puede usar ‘categorías’ en lugar de ‘bin_edges’ para variables continuas donde tenga sentido; por ejemplo, donde cada contenedor representa un día de la semanabin_edges:(lista de números de lista de cadenas) (obligatorio) | bin_edges | == | valores | + 1categorías:(lista de cadenas) (obligatorio) | bin_edges | == | valores |valores:(lista de números) (obligatorio) Las frecuencias normalizadas. Para variables continuas, en integral sobre el rango debe ser 1. Para variables categóricas, la suma de frecuencias puede ser <= 1. Si <1, el sistema asumirá que la masa restante se distribuye equitativamente en todas las demás categorías. Por ejemplo, para la probabilidad de que un frigorífico esté en una habitación específica, basta con indicar que la probabilidad de que un frigorífico esté en la cocina es 0,9. | |
| modelo: | (dict) Un modelo ajustado para describir la densidad de probabilidadfunción (para variables continuas) o la función de masa de probabilidad (para variables discretas). Use propiedades adicionales para los parámetros relevantes, escritas como letras griegas en inglés en minúsculas, por ejemplo, ‘mu’ y ‘lambda’, excepto para las estadísticas de resumen donde usamos alguna combinación de ‘min’, ‘max’, ‘mean’, ‘mode’ .nombre_distribucion: (enumeración) uno de {‘normal’, ‘gaussiano inverso’, ‘resumen de estadísticas’}sum_of_squared_error: (número) |
| n_datapoints: | (En t) |
| Fecha Preparada: | (cadena) Formato de fecha ISO 8601 |
| fuente: | (enumeración) uno de {‘subjetivo’, ‘empírico a partir de datos’, ‘empírico a partir de publicación’}. ¿Cuál es la fuente de este previo? Si es de publicación, utilice related_documentspara proporcionar referencias. Si procede de datos, proporcione detalles mediante las propiedades softwarey training_data. |
| documentos relacionados: | |
| (lista de cadenas) Si ‘fuente == empírica de la publicación’ entonces ingrese la (s) referencia (s) aquí. | |
| software: | (cadena) el software utilizado para generar el anterior a partir de los datos. |
| específico a: | (dic):país:(cadena) código de país estándar de dos letras definido por ISO 3166-1 alpha-2, por ejemplo, ‘GB’ o ‘US’.continente:(cadena) código continente estándar de dos letras definido en WikiPedia |
| distancia: | (int) esto se completa con la concatenate_complete_objectfunción e informa la distancia (en número de generaciones) entre este objeto anterior y el más derivado. En otras palabras, cuanto mayor sea este número, menos específico del objeto es este anterior. Si no se establece, el anterior se aplica al objeto actual. |
| from_appliance_type: | |
(cadena) esto lo completa la concatenate_complete_objectfunción e informa el nombre del tipo de dispositivo de la jerarquía del ancestro de donde proviene esta distribución. | |
| descripción: | (cuerda) |
| datos de entrenamiento: | (conjunto de dictados). Cada elemento es un dictado con estas propiedades:conjunto de datos:(cadena) Nombre corto del conjunto de datosedificios:(lista de dictados):building_id:(En t)fechas:(lista de objetos de esquema de intervalo )país:(cadena) código de país estándar de dos letras definido por ISO 3166-1 alpha-2, por ejemplo, ‘GB’ o ‘US’. |
DesgloseModelo
Esto aún no está especialmente bien definido. Solo un boceto inicial. La idea básica es que podríamos especificar modelos para cada tipo de aparato.
| tipo_de_dispositivo: | (cadena) Referencia al ApplianceType específico que estamos modelando. |
|---|---|
| tipo de modelo: | (enumeración) uno de {‘HMM’, ‘FHMM’, ‘optimización para gobernador’} |
| parámetros: | (dict) Parámetros específicos de cada tipo de modelo. |
DisaggregationModel reutiliza varias propiedades de Prior :
- datos de entrenamiento
- específico a
- software
- documentos relacionados
- Fecha Preparada
- descripción

Deja un comentario