Diseño de MPI para el modelo de transmisión de mensajes
Antes de comenzar que es MPI vermos un par de conceptos clásicos detrás del diseño de MPI del modelo de transmisión de mensajes de programación paralela. El primer concepto es la noción de comunicador . Un comunicador define un grupo de procesos que tienen la capacidad de comunicarse entre sí. En este grupo de procesos, a cada uno se le asigna un rango único y se comunican explícitamente entre sí por sus rangos.
La base de la comunicación se basa en operaciones de envío y recepción entre procesos. Un proceso puede enviar un mensaje a otro proceso proporcionando el rango del proceso y una etiqueta única para identificar el mensaje. El receptor puede publicar una recepción para un mensaje con una etiqueta determinada (o puede que ni siquiera le importe la etiqueta) y luego manejar los datos en consecuencia. Las comunicaciones como ésta, que involucran a un remitente y un receptor, se conocen como comunicaciones punto a punto .
Hay muchos casos en los que los procesos pueden necesitar comunicarse con todos los demás. Por ejemplo, cuando un proceso de administrador necesita transmitir información a todos sus procesos de trabajo. En este caso, sería engorroso escribir código que haga todos los envíos y recibos. De hecho, a menudo no utilizaría la red de forma óptima. MPI puede manejar una amplia variedad de estos tipos de comunicaciones colectivas que involucran todos los procesos.
Se pueden utilizar mezclas de comunicaciones colectivas y punto a punto para crear programas paralelos muy complejos. De hecho, esta funcionalidad es tan poderosa que ni siquiera es necesario comenzar a describir los mecanismos avanzados de MPI.
Hello World en MPI
Vamos a sumergirnos en el código de esta lección que se encuentra en mpi_hello_world.c . A continuación se muestran algunos extractos del código.
Notará que el primer paso para crear un programa MPI es incluir los archivos de encabezado MPI con #include <mpi.h>. Después de esto, el entorno MPI debe inicializarse con:
MPI_Init(
int* argc,
char*** argv)
Durante MPI_Init, se construyen todas las variables globales e internas de MPI. Por ejemplo, se forma un comunicador en torno a todos los procesos que se generaron y se asignan rangos únicos a cada proceso. Actualmente, MPI_Inittoma dos argumentos que no son necesarios, y los parámetros adicionales simplemente se dejan como espacio adicional en caso de que futuras implementaciones los necesiten.
#include <mpi.h> #include <stdio.h>
int main(int argc, char** argv) {
// Initialize the MPI environment
MPI_Init(NULL, NULL);
// Get the number of processes
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
// Get the rank of the process
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
// Get the name of the processor
char processor_name[MPI_MAX_PROCESSOR_NAME];
int name_len;
MPI_Get_processor_name(processor_name, &name_len);
// Print off a hello world message
printf("Hello world from processor %s, rank %d out of %d processors\n",
processor_name, world_rank, world_size);
// Finalize the MPI environment.
MPI_Finalize();
}
Después MPI_Init, hay dos funciones principales que se llaman. Estas dos funciones se utilizan en casi todos los programas MPI que escribirá.
MPI_Comm_size(
MPI_Comm communicator,
int* size)
MPI_Comm_sizedevuelve el tamaño de un comunicador. En nuestro ejemplo, MPI_COMM_WORLD(que MPI construye para nosotros) incluye todos los procesos en el trabajo, por lo que esta llamada debe devolver la cantidad de procesos que se solicitaron para el trabajo.
MPI_Comm_rank(
MPI_Comm communicator,
int* rank)
MPI_Comm_rankdevuelve el rango de un proceso en un comunicador. A cada proceso dentro de un comunicador se le asigna un rango incremental a partir de cero. Los rangos de los procesos se utilizan principalmente con fines de identificación al enviar y recibir mensajes.
Una función miscelánea y menos utilizada en este programa es:
MPI_Get_processor_name(
char* name,
int* name_length)
MPI_Get_processor_nameobtiene el nombre real del procesador en el que se está ejecutando el proceso. La última convocatoria de este programa es:
MPI_Finalize()
MPI_Finalizese utiliza para limpiar el entorno MPI. No se pueden realizar más llamadas MPI después de esta.
Ejecución de la aplicación MPI hello world
Ahora revise el código y examine la carpeta del código. En él hay un archivo MAKE.
>>> git clone https://github.com/mpitutorial/mpitutorial
>>> cd mpitutorial/tutorials/mpi-hello-world/code
>>> cat makefile
EXECS=mpi_hello_world
MPICC?=mpicc
all: ${EXECS}
mpi_hello_world: mpi_hello_world.c
${MPICC} -o mpi_hello_world mpi_hello_world.c
clean:
rm ${EXECS}
Mi archivo MAKE busca la variable de entorno MPICC. Si instaló MPICH2 en un directorio local, configure su variable de entorno MPICC para que apunte a su binario mpicc. El programa mpicc en su instalación es realmente un envoltorio alrededor de gcc, y hace que compilar y vincular todas las rutinas MPI necesarias sea mucho más fácil.
>>> export MPICC=/home/kendall/bin/mpicc
>>> make
/home/kendall/bin/mpicc -o mpi_hello_world mpi_hello_world.c
Una vez compilado el programa, estará listo para ejecutarse. Ahora viene la parte en la que es posible que deba realizar alguna configuración adicional. Si está ejecutando programas MPI en un grupo de nodos, deberá configurar un archivo de host. Si simplemente está ejecutando MPI en una computadora portátil o en una sola máquina, ignore la siguiente información.
El archivo de host contiene los nombres de todas las computadoras en las que se ejecutará su trabajo MPI. Para facilitar la ejecución, debe asegurarse de que todas estas computadoras tengan acceso SSH, y también debe configurar un archivo de claves autorizadas para evitar una solicitud de contraseña para SSH. Mi archivo de host se ve así.
>>> cat host_file
cetus1
cetus2
cetus3
cetus4
Para el script de ejecución que proporcioné en la descarga, debe establecer una variable de entorno llamada MPI_HOSTS y hacer que apunte a su archivo de hosts. Mi script lo incluirá automáticamente en la línea de comandos cuando se inicie el trabajo MPI. Si no necesita un archivo de hosts, simplemente no configure la variable de entorno. Además, si tiene una instalación local de MPI, debe configurar la variable de entorno MPIRUN para que apunte al binario mpirun de la instalación.
Una vez hecho esto, puede usar el script de python run.py que se incluye en el repositorio principal. Se almacena en el directorio de tutoriales y puede ejecutar cualquier programa en todos los tutoriales (también intenta compilar los ejecutables antes de que se ejecuten). Intente lo siguiente desde la carpeta raíz mpitutorial.
>>> export MPIRUN=/home/kendall/bin/mpirun
>>> export MPI_HOSTS=host_file
>>> cd tutorials
>>> ./run.py mpi_hello_world
/home/kendall/bin/mpirun -n 4 -f host_file ./mpi_hello_world
Hello world from processor cetus2, rank 1 out of 4 processors
Hello world from processor cetus1, rank 0 out of 4 processors
Hello world from processor cetus4, rank 3 out of 4 processors
Hello world from processor cetus3, rank 2 out of 4 processors
Como era de esperar, el programa MPI se inició en todos los hosts de mi archivo de host. A cada proceso se le asignó un rango único, que se imprimió junto con el nombre del proceso. Como se puede ver en mi salida de ejemplo, la salida de los procesos está en un orden arbitrario ya que no hay sincronización involucrada antes de la impresión.
Observe cómo el script se llama mpirun. Este es el programa que utiliza la implementación de MPI para iniciar el trabajo. Los procesos se generan en todos los hosts del archivo de host y el programa MPI se ejecuta en cada proceso. Mi script proporciona automáticamente el indicador -n para establecer el número de procesos MPI en cuatro. ¡Intente cambiar el script de ejecución y lanzar más procesos! Sin embargo, no bloquee accidentalmente su sistema. 🙂
Ahora puede estar preguntando: “Mis hosts son en realidad máquinas de doble núcleo. ¿Cómo puedo hacer que MPI genere procesos en los núcleos individuales primero antes que en las máquinas individuales? » La solución es bastante sencilla. Simplemente modifique su archivo de hosts y coloque dos puntos y el número de núcleos por procesador después del nombre de host. Por ejemplo, especifiqué que cada uno de mis hosts tiene dos núcleos.
>>> cat host_file
cetus1:2
cetus2:2
cetus3:2
cetus4:2
Cuando vuelva a ejecutar el script de ejecución, ¡voilá! , el trabajo MPI genera dos procesos en solo dos de mis hosts.
>>> ./run.py mpi_hello_world
/home/kendall/bin/mpirun -n 4 -f host_file ./mpi_hello_world
Hello world from processor cetus1, rank 0 out of 4 processors
Hello world from processor cetus2, rank 2 out of 4 processors
Hello world from processor cetus2, rank 3 out of 4 processors
Hello world from processor cetus1, rank 1 out of 4 processors
Enviar y recibir son los dos conceptos fundamentales de MPI. Casi todas las funciones de MPI se pueden implementar con llamadas básicas de envío y recepción. En esta lección, discutiré cómo usar las funciones de envío y recepción de bloqueo de MPI, y también describiré otros conceptos básicos asociados con la transmisión de datos usando MPI.
Descripción general de envío y recepción con MPI
Las llamadas de envío y recepción de MPI funcionan de la siguiente manera. En primer lugar, el proceso A decide que necesita un mensaje que se enviará al proceso B . El proceso A luego empaqueta todos sus datos necesarios en un búfer para el proceso B. Estos búferes a menudo se denominan sobres, ya que los datos se empaquetan en un solo mensaje antes de la transmisión (similar a cómo las cartas se empaquetan en sobres antes de la transmisión al oficina de correos). Una vez que los datos se empaquetan en un búfer, el dispositivo de comunicación (que a menudo es una red) es responsable de enrutar el mensaje a la ubicación adecuada. La ubicación del mensaje está definida por el rango del proceso.
Aunque el mensaje se enruta a B, el proceso B todavía tiene que reconocer que desea recibir los datos de A. Una vez que hace esto, los datos se han transmitido. El proceso A reconoce que los datos se han transmitido y puede volver a funcionar.
A veces, hay casos en los que A podría tener que enviar muchos tipos diferentes de mensajes a B. En lugar de que B tenga que pasar por medidas adicionales para diferenciar todos estos mensajes, MPI permite a los remitentes y receptores especificar también las ID de mensaje con el mensaje (conocidas como etiquetas ). Cuando el proceso B solo solicita un mensaje con un determinado número de etiqueta, la red almacenará en búfer los mensajes con etiquetas diferentes hasta que B esté listo para recibirlos.
Con estos conceptos en mente, veamos los prototipos de las funciones de envío y recepción de MPI.
MPI_Send(
void* data,
int count,
MPI_Datatype datatype,
int destination,
int tag,
MPI_Comm communicator)
MPI_Recv(
void* data,
int count,
MPI_Datatype datatype,
int source,
int tag,
MPI_Comm communicator,
MPI_Status* status)
Aunque esto puede parecer un bocado al leer todos los argumentos, se vuelven más fáciles de recordar ya que casi todas las llamadas MPI usan una sintaxis similar. El primer argumento es el búfer de datos. El segundo y tercer argumento describen el recuento y el tipo de elementos que residen en el búfer. MPI_Sendenvía el recuento exacto de elementos y MPI_Recvrecibirá como máximo el recuento de elementos (más sobre esto en la próxima lección). Los argumentos cuarto y quinto especifican el rango del proceso de envío / recepción y la etiqueta del mensaje. El sexto argumento especifica el comunicador y el último argumento ( MPI_Recvsolo para ) proporciona información sobre el mensaje recibido.
Tipos de datos MPI elementales
Las funciones MPI_Sendy MPI_Recvutilizan tipos de datos MPI como un medio para especificar la estructura de un mensaje en un nivel superior. Por ejemplo, si el proceso desea enviar un número entero a otro, usaría un recuento de uno y un tipo de datos de MPI_INT. Los otros tipos de datos MPI elementales se enumeran a continuación con sus tipos de datos C equivalentes.
| Tipo de datos MPI | Equivalente de C |
|---|---|
| MPI_SHORT | int corto |
| MPI_INT | En t |
| MPI_LONG | int largo |
| MPI_LONG_LONG | largo largo int |
| MPI_UNSIGNED_CHAR | char sin firmar |
| MPI_UNSIGNED_SHORT | int corto sin firmar |
| MPI_UNSIGNED | int sin firmar |
| MPI_UNSIGNED_LONG | unsigned long int |
| MPI_UNSIGNED_LONG_LONG | unsigned long long int |
| MPI_FLOAT | flotador |
| MPI_DOUBLE | doble |
| MPI_LONG_DOUBLE | doble largo |
| MPI_BYTE | carbonizarse |
Por ahora, solo haremos uso de estos tipos de datos en los siguientes tutoriales de MPI en la categoría de principiantes. Una vez que hayamos cubierto suficientes conceptos básicos, aprenderá a crear sus propios tipos de datos MPI para caracterizar tipos de mensajes más complejos.
Programa de envío / recepción MPI
El primer ejemplo del código del tutorial está en send_recv.c . Algunas de las partes principales del programa se muestran a continuación.
// Find out rank, size
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
int number;
if (world_rank == 0) {
number = -1;
MPI_Send(&number, 1, MPI_INT, 1, 0, MPI_COMM_WORLD);
} else if (world_rank == 1) {
MPI_Recv(&number, 1, MPI_INT, 0, 0, MPI_COMM_WORLD,
MPI_STATUS_IGNORE);
printf("Process 1 received number %d from process 0\n",
number);
}
MPI_Comm_ranky MPI_Comm_sizese utilizan primero para determinar el tamaño del mundo junto con el rango del proceso. Luego, el proceso cero inicializa un número con el valor de uno negativo y envía este valor al proceso uno. Como puede ver en la else ifdeclaración, el proceso uno está llamando MPI_Recvpara recibir el número. También imprime el valor recibido. Dado que estamos enviando y recibiendo exactamente un número entero, cada proceso solicita que MPI_INTse envíe / reciba uno. Cada proceso también usa un número de etiqueta cero para identificar el mensaje. Los procesos también podrían haber utilizado la constante predefinida MPI_ANY_TAGpara el número de etiqueta, ya que solo se estaba transmitiendo un tipo de mensaje.
Puede ejecutar el código de ejemplo comprobándolo en GitHub y usando el run.pyscript.
>>> git clone https://github.com/mpitutorial/mpitutorial
>>> cd mpitutorial/tutorials
>>> ./run.py send_recv
mpirun -n 2 ./send_recv
Process 1 received number -1 from process 0
Como era de esperar, el proceso uno recibe uno negativo del proceso cero.
Programa de ping pong MPI
El siguiente ejemplo es un programa de ping pong. En este ejemplo, los procesos usan MPI_Sendy MPI_Recvpara rebotar continuamente mensajes entre sí hasta que deciden detenerse. Eche un vistazo a ping_pong.c . Las partes principales del código se ven así.
int ping_pong_count = 0;
int partner_rank = (world_rank + 1) % 2;
while (ping_pong_count < PING_PONG_LIMIT) {
if (world_rank == ping_pong_count % 2) {
// Increment the ping pong count before you send it
ping_pong_count++;
MPI_Send(&ping_pong_count, 1, MPI_INT, partner_rank, 0,
MPI_COMM_WORLD);
printf("%d sent and incremented ping_pong_count "
"%d to %d\n", world_rank, ping_pong_count,
partner_rank);
} else {
MPI_Recv(&ping_pong_count, 1, MPI_INT, partner_rank, 0,
MPI_COMM_WORLD, MPI_STATUS_IGNORE);
printf("%d received ping_pong_count %d from %d\n",
world_rank, ping_pong_count, partner_rank);
}
}
Este ejemplo está destinado a ejecutarse con solo dos procesos. Los procesos primero determinan a su pareja con algo de aritmética simple. A ping_pong_countse inicia a cero y se incrementa en cada paso de ping pong por el proceso de envío. A medida que ping_pong_countse incrementa, los procesos se turnan para ser emisor y receptor. Finalmente, después de que se alcanza el límite (diez en mi código), los procesos dejan de enviar y recibir. La salida del código de ejemplo se verá así.
>>> ./run.py ping_pong
0 sent and incremented ping_pong_count 1 to 1
0 received ping_pong_count 2 from 1
0 sent and incremented ping_pong_count 3 to 1
0 received ping_pong_count 4 from 1
0 sent and incremented ping_pong_count 5 to 1
0 received ping_pong_count 6 from 1
0 sent and incremented ping_pong_count 7 to 1
0 received ping_pong_count 8 from 1
0 sent and incremented ping_pong_count 9 to 1
0 received ping_pong_count 10 from 1
1 received ping_pong_count 1 from 0
1 sent and incremented ping_pong_count 2 to 0
1 received ping_pong_count 3 from 0
1 sent and incremented ping_pong_count 4 to 0
1 received ping_pong_count 5 from 0
1 sent and incremented ping_pong_count 6 to 0
1 received ping_pong_count 7 from 0
1 sent and incremented ping_pong_count 8 to 0
1 received ping_pong_count 9 from 0
1 sent and incremented ping_pong_count 10 to 0
La salida de los programas en otras máquinas probablemente será diferente debido a la programación del proceso. Sin embargo, como puede ver, el proceso cero y uno se turnan para enviar y recibir el contador de ping pong entre sí.
Programa de timbre
He incluido un ejemplo más MPI_Sendy el MPI_Recvuso de más de dos procesos. En este ejemplo, todos los procesos pasan un valor en forma de anillo. Echar un vistazo a ring.c . La mayor parte del código se ve así.
int token;
if (world_rank != 0) {
MPI_Recv(&token, 1, MPI_INT, world_rank - 1, 0,
MPI_COMM_WORLD, MPI_STATUS_IGNORE);
printf("Process %d received token %d from process %d\n",
world_rank, token, world_rank - 1);
} else {
// Set the token's value if you are process 0
token = -1;
}
MPI_Send(&token, 1, MPI_INT, (world_rank + 1) % world_size,
0, MPI_COMM_WORLD);
// Now process 0 can receive from the last process.
if (world_rank == 0) {
MPI_Recv(&token, 1, MPI_INT, world_size - 1, 0,
MPI_COMM_WORLD, MPI_STATUS_IGNORE);
printf("Process %d received token %d from process %d\n",
world_rank, token, world_size - 1);
}
El programa de anillo inicializa un valor a partir del proceso cero, y el valor se pasa alrededor de cada proceso. El programa termina cuando el proceso cero recibe el valor del último proceso. Como puede ver en el programa, se tiene especial cuidado para asegurar que no se bloquee. En otras palabras, el proceso cero se asegura de que haya completado su primer envío antes de intentar recibir el valor del último proceso. Todos los demás procesos simplemente llaman MPI_Recv(recibiendo de su proceso inferior vecino) y luego MPI_Send(enviando el valor a su proceso superior vecino) para pasar el valor a lo largo del anillo. MPI_SendyMPI_Recvse bloqueará hasta que se transmita el mensaje. Debido a esto, printfs debería ocurrir en el orden en que se pasa el valor. Usando cinco procesos, la salida debería verse así.
>>> ./run.py ring
Process 1 received token -1 from process 0
Process 2 received token -1 from process 1
Process 3 received token -1 from process 2
Process 4 received token -1 from process 3
Process 0 received token -1 from process 4
Como podemos ver, el proceso cero primero envía un valor negativo uno al proceso uno. Este valor se pasa por el anillo hasta que vuelve al cero del proceso.
Aunque es posible enviar la longitud del mensaje como una operación de envío / recepción separada, MPI admite mensajes dinámicos de forma nativa con solo unas pocas llamadas de función adicionales. En esta lección, repasaré cómo usar estas funciones.
La estructura MPI_Status
La funcion MPI_Recvoperación toma la dirección de una MPI_Statusestructura como argumento (que se puede ignorar con MPI_STATUS_IGNORE). Si pasamos una MPI_Statusestructura a la MPI_Recvfunción, se completará con información adicional sobre la operación de recepción después de que se complete. Los tres elementos principales de información incluyen:
- El rango del remitente . El rango del remitente se almacena en el
MPI_SOURCEelemento de la estructura. Es decir, si declaramos unaMPI_Status statvariable, se puede acceder al rango constat.MPI_SOURCE. - La etiqueta del mensaje . Se puede acceder a la etiqueta del mensaje mediante el
MPI_TAGelemento de la estructura (similar aMPI_SOURCE). - La longitud del mensaje . La longitud del mensaje no tiene un elemento predefinido en la estructura de estado. En cambio, tenemos que averiguar la longitud del mensaje con
MPI_Get_count.
MPI_Get_count(
MPI_Status* status,
MPI_Datatype datatype,
int* count)
En MPI_Get_count, el usuario pasa la MPI_Statusestructura, la datatypedel mensaje y countse devuelve. La countvariable es el número total de datatypeelementos que se recibieron.
¿Por qué sería necesaria esta información? Resulta que se MPI_Recvpuede tomar MPI_ANY_SOURCEpor el rango del remitente y MPI_ANY_TAGpor la etiqueta del mensaje. En este caso, la MPI_Statusestructura es la única forma de averiguar el remitente real y la etiqueta del mensaje. Además, MPI_Recvno se garantiza que reciba la cantidad total de elementos pasados como argumento para la llamada a la función. En cambio, recibe la cantidad de elementos que se le enviaron (y devuelve un error si se enviaron más elementos que la cantidad de recepción deseada). La función MPI_Get_count se utiliza para determinar la cantidad recibida real.
Un ejemplo de consulta de la estructura MPI_Status
El programa que consulta la MPI_Statusestructura está en check_status.c . El programa envía una cantidad aleatoria de números a un receptor, y el receptor averigua cuántos números se enviaron. La parte principal del código se ve así.
const int MAX_NUMBERS = 100;
int numbers[MAX_NUMBERS];
int number_amount;
if (world_rank == 0) {
// Pick a random amount of integers to send to process one
srand(time(NULL));
number_amount = (rand() / (float)RAND_MAX) * MAX_NUMBERS;
// Send the amount of integers to process one
MPI_Send(numbers, number_amount, MPI_INT, 1, 0, MPI_COMM_WORLD);
printf("0 sent %d numbers to 1\n", number_amount);
} else if (world_rank == 1) {
MPI_Status status;
// Receive at most MAX_NUMBERS from process zero
MPI_Recv(numbers, MAX_NUMBERS, MPI_INT, 0, 0, MPI_COMM_WORLD,
&status);
// After receiving the message, check the status to determine
// how many numbers were actually received
MPI_Get_count(&status, MPI_INT, &number_amount);
// Print off the amount of numbers, and also print additional
// information in the status object
printf("1 received %d numbers from 0. Message source = %d, "
"tag = %d\n",
number_amount, status.MPI_SOURCE, status.MPI_TAG);
}
Como podemos ver, el proceso cero envía aleatoriamente hasta MAX_NUMBERSnúmeros enteros para procesar uno. El proceso uno luego requiere MPI_Recvun total de MAX_NUMBERSnúmeros enteros. Aunque el proceso uno pasa MAX_NUMBERScomo argumento MPI_Recv, el proceso uno recibirá como máximo esta cantidad de números. En el código, procese una llamada MPI_Get_countcon MPI_INTcomo tipo de datos para averiguar cuántos enteros se recibieron realmente. Además de imprimir el tamaño del mensaje recibido, el proceso uno también imprime la fuente y la etiqueta del mensaje accediendo a los elementos MPI_SOURCEy MPI_TAGde la estructura de estado.
Como aclaración, el valor de retorno de MPI_Get_countes relativo al tipo de datos que se pasa. Si el usuario lo usara MPI_CHARcomo tipo de datos, la cantidad devuelta sería cuatro veces mayor (asumiendo que un número entero tiene cuatro bytes y un carácter es un byte). Si ejecuta el programa check_status desde el directorio de tutoriales del repositorio , la salida debería verse similar a esta.
>>> cd tutorials
>>> ./run.py check_status
mpirun -n 2 ./check_status
0 sent 92 numbers to 1
1 received 92 numbers from 0. Message source = 0, tag = 0
Como se esperaba, el proceso cero envía una cantidad aleatoria de números enteros para procesar uno, que imprime información sobre el mensaje recibido.
Usando MPI_Probe para averiguar el tamaño del mensaje
Ahora que comprende cómo funciona el MPI_Statusobjeto, podemos usarlo un poco más en nuestro beneficio. En lugar de publicar una recepción y simplemente proporcionar un búfer realmente grande para manejar todos los tamaños posibles de mensajes (como hicimos en el último ejemplo), puede usar MPI_Probepara consultar el tamaño del mensaje antes de recibirlo. El prototipo de la función se ve así.
MPI_Probe(
int source,
int tag,
MPI_Comm comm,
MPI_Status* status)
MPI_Probeparece bastante similar a MPI_Recv. De hecho, se puede pensar en MPI_Probecomo MPI_Recvque lo hace todo, pero recibir el mensaje. Similar a MPI_Recv, MPI_Probese bloqueará para un mensaje con una etiqueta y un remitente coincidentes. Cuando el mensaje esté disponible, llenará la estructura de estado con información. El usuario puede utilizar MPI_Recvpara recibir el mensaje real.
Así es como se ve el código fuente principal.
int number_amount;
if (world_rank == 0) {
const int MAX_NUMBERS = 100;
int numbers[MAX_NUMBERS];
// Pick a random amount of integers to send to process one
srand(time(NULL));
number_amount = (rand() / (float)RAND_MAX) * MAX_NUMBERS;
// Send the random amount of integers to process one
MPI_Send(numbers, number_amount, MPI_INT, 1, 0, MPI_COMM_WORLD);
printf("0 sent %d numbers to 1\n", number_amount);
} else if (world_rank == 1) {
MPI_Status status;
// Probe for an incoming message from process zero
MPI_Probe(0, 0, MPI_COMM_WORLD, &status);
// When probe returns, the status object has the size and other
// attributes of the incoming message. Get the message size
MPI_Get_count(&status, MPI_INT, &number_amount);
// Allocate a buffer to hold the incoming numbers
int* number_buf = (int*)malloc(sizeof(int) * number_amount);
// Now receive the message with the allocated buffer
MPI_Recv(number_buf, number_amount, MPI_INT, 0, 0,
MPI_COMM_WORLD, MPI_STATUS_IGNORE);
printf("1 dynamically received %d numbers from 0.\n",
number_amount);
free(number_buf);
}
Al igual que en el último ejemplo, el proceso cero elige una cantidad aleatoria de números para enviar al proceso uno. Lo que es diferente en este ejemplo es que el proceso uno ahora llama MPI_Probepara averiguar cuántos elementos el proceso cero está tratando de enviar (usando MPI_Get_count). El proceso uno luego asigna un búfer del tamaño adecuado y recibe los números. Ejecutar el código se verá similar a esto.
>>> ./run.py probe
mpirun -n 2 ./probe
0 sent 93 numbers to 1
1 dynamically received 93 numbers from 0
Aunque este ejemplo es trivial, MPI_Probeconstituye la base de muchas aplicaciones MPI dinámicas. Por ejemplo, los programas de administrador / trabajador a menudo harán un uso intensivo de los MPI_Probemensajes de trabajadores de tamaño variable.
Es hora de pasar por un ejemplo de aplicación utilizando algunos de los conceptos introducidos en el tutorial de envío y recepción y la lección MPI_Probe y MPI_Status . La aplicación simula un proceso al que me refiero como «caminar al azar».
La definición básica del problema de una caminata aleatoria es la siguiente. Dada una Min , Max , y al azar Walker W , hacen Walker W tomar S aleatoria de longitud arbitraria camina hacia la derecha. Si el proceso se sale de los límites, se reinicia. W solo puede mover una unidad hacia la derecha o hacia la izquierda a la vez.

Aunque la aplicación en sí misma es muy básica, la paralelización de la marcha aleatoria puede simular el comportamiento de una amplia variedad de aplicaciones paralelas. Más sobre eso más tarde. Por ahora, repasemos cómo paralelizar el problema del paseo aleatorio.
Paralelización del problema de la marcha aleatoria
Nuestra primera tarea, que es pertinente para muchos programas paralelos, es dividir el dominio entre procesos. El problema de la caminata aleatoria tiene un dominio unidimensional de tamaño Max – Min + 1 (ya que Max y Min son inclusivos para el caminante). Suponiendo que los caminantes solo pueden tomar pasos de tamaño entero, podemos dividir fácilmente el dominio en fragmentos de tamaño casi igual en todos los procesos. Por ejemplo, si Min es 0 y Max es 20 y tenemos cuatro procesos, el dominio se dividiría así.
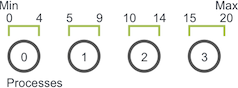
Los primeros tres procesos poseen cinco unidades del dominio, mientras que el último proceso toma las últimas cinco unidades más la unidad restante. Una vez que se ha particionado el dominio, la aplicación inicializará los caminantes. Como se explicó anteriormente, un caminante realizará caminatas S con un tamaño total de caminata aleatorio. Por ejemplo, si el caminante da un paseo de tamaño seis en el proceso cero (usando la descomposición de dominio anterior), la ejecución del caminante será así:
- El caminante comienza a dar pasos incrementales. Sin embargo, cuando alcanza el valor cuatro, ha alcanzado el final de los límites del proceso cero. El proceso cero ahora tiene que comunicar al caminante que procese uno.
- El proceso uno recibe el andador y continúa caminando hasta que alcanza su tamaño total de caminata de seis. Luego, el caminante puede continuar con una nueva caminata aleatoria.
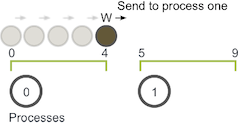
En este ejemplo, W solo tuvo que comunicarse una vez desde el proceso cero al proceso uno. Sin embargo, si W tuvo que caminar más, es posible que haya tenido que pasar por más procesos a lo largo de su camino a través del dominio.
Codificación de la aplicación usando MPI_Send y MPI_Recv
Esta aplicación se puede codificar con MPI_Sendy MPI_Recv. Antes de comenzar a mirar el código, establezcamos algunas características y funciones preliminares del programa:
- Cada proceso determina su parte del dominio.
- Cada proceso inicializa exactamente N caminantes, todos los cuales comienzan en el primer valor de su dominio local.
- Cada andador tiene dos valores enteros asociados: la posición actual del andador y el número de pasos que quedan por dar.
- Los caminantes comienzan a atravesar el dominio y pasan a otros procesos hasta que completan su recorrido.
- Los procesos terminan cuando todos los caminantes terminan.
Comencemos escribiendo código para la descomposición del dominio. La función tomará el tamaño total del dominio y encontrará el subdominio apropiado para el proceso MPI. También dará cualquier resto del dominio al proceso final. Para simplificar, solo pido MPI_Abortlos errores que se encuentren. La función, llamada decompose_domain, se ve así:
void decompose_domain(int domain_size, int world_rank,
int world_size, int* subdomain_start,
int* subdomain_size) {
if (world_size > domain_size) {
// Don't worry about this special case. Assume the domain
// size is greater than the world size.
MPI_Abort(MPI_COMM_WORLD, 1);
}
*subdomain_start = domain_size / world_size * world_rank;
*subdomain_size = domain_size / world_size;
if (world_rank == world_size - 1) {
// Give remainder to last process
*subdomain_size += domain_size % world_size;
}
}
Como puede ver, la función divide el dominio en partes pares, ocupándose del caso cuando hay un resto presente. La función devuelve un inicio de subdominio y un tamaño de subdominio.
A continuación, necesitamos crear una función que inicialice a los caminantes. Primero definimos una estructura de andador que se ve así:
typedef struct {
int location;
int num_steps_left_in_walk;
} Walker;
Nuestra función de inicialización, llamada initialize_walkers, toma los límites del subdominio y agrega caminantes a un incoming_walkersvector (por cierto, esta aplicación está en C ++).
void initialize_walkers(int num_walkers_per_proc, int max_walk_size,
int subdomain_start, int subdomain_size,
vector<Walker>* incoming_walkers) {
Walker walker;
for (int i = 0; i < num_walkers_per_proc; i++) {
// Initialize walkers in the middle of the subdomain
walker.location = subdomain_start;
walker.num_steps_left_in_walk =
(rand() / (float)RAND_MAX) * max_walk_size;
incoming_walkers->push_back(walker);
}
}
Después de la inicialización, es hora de que los caminantes progresen. Comencemos haciendo una función de caminar. Esta función se encarga de que el caminante avance hasta que haya terminado su caminata. Si se sale de los límites locales, se agrega al outgoing_walkersvector.
void walk(Walker* walker, int subdomain_start, int subdomain_size,
int domain_size, vector<Walker>* outgoing_walkers) {
while (walker->num_steps_left_in_walk > 0) {
if (walker->location == subdomain_start + subdomain_size) {
// Take care of the case when the walker is at the end
// of the domain by wrapping it around to the beginning
if (walker->location == domain_size) {
walker->location = 0;
}
outgoing_walkers->push_back(*walker);
break;
} else {
walker->num_steps_left_in_walk--;
walker->location++;
}
}
}
Ahora que hemos establecido una función de inicialización (que llena una lista de caminantes entrantes) y una función de caminar (que llena una lista de caminantes salientes), solo necesitamos dos funciones más: una función que envía caminantes salientes y una función que recibe caminantes entrantes. La función de envío se ve así:
void send_outgoing_walkers(vector<Walker>* outgoing_walkers,
int world_rank, int world_size) {
// Send the data as an array of MPI_BYTEs to the next process.
// The last process sends to process zero.
MPI_Send((void*)outgoing_walkers->data(),
outgoing_walkers->size() * sizeof(Walker), MPI_BYTE,
(world_rank + 1) % world_size, 0, MPI_COMM_WORLD);
// Clear the outgoing walkers
outgoing_walkers->clear();
}
La función que recibe los caminantes entrantes debe usarla MPI_Probeya que no sabe de antemano cuántos caminantes recibirá. Esto es lo que parece:
void receive_incoming_walkers(vector<Walker>* incoming_walkers,
int world_rank, int world_size) {
MPI_Status status;
// Receive from the process before you. If you are process zero,
// receive from the last process
int incoming_rank =
(world_rank == 0) ? world_size - 1 : world_rank - 1;
MPI_Probe(incoming_rank, 0, MPI_COMM_WORLD, &status);
// Resize your incoming walker buffer based on how much data is
// being received
int incoming_walkers_size;
MPI_Get_count(&status, MPI_BYTE, &incoming_walkers_size);
incoming_walkers->resize(
incoming_walkers_size / sizeof(Walker));
MPI_Recv((void*)incoming_walkers->data(), incoming_walkers_size,
MPI_BYTE, incoming_rank, 0, MPI_COMM_WORLD,
MPI_STATUS_IGNORE);
}
Ahora hemos establecido las funciones principales del programa. Tenemos que unir todas estas funciones de la siguiente manera:
- Inicialice los caminantes.
- Progrese a los caminantes con la
walkfunción. - Envíe cualquier caminante en el
outgoing_walkersvector. - Reciba nuevos caminantes y colóquelos en el
incoming_walkersvector. - Repita los pasos del dos al cuatro hasta que todos los caminantes hayan terminado.
El primer intento de escribir este programa se encuentra a continuación. Por ahora, no nos preocuparemos de cómo determinar cuándo han terminado todos los caminantes. Antes de mirar el código, debo advertirle: ¡este código es incorrecto! Con esto en mente, echemos un vistazo a mi código y, con suerte, podrá ver qué podría estar mal en él.
// Find your part of the domain
decompose_domain(domain_size, world_rank, world_size,
&subdomain_start, &subdomain_size);
// Initialize walkers in your subdomain
initialize_walkers(num_walkers_per_proc, max_walk_size,
subdomain_start, subdomain_size,
&incoming_walkers);
while (!all_walkers_finished) { // Determine walker completion later
// Process all incoming walkers
for (int i = 0; i < incoming_walkers.size(); i++) {
walk(&incoming_walkers[i], subdomain_start, subdomain_size,
domain_size, &outgoing_walkers);
}
// Send all outgoing walkers to the next process.
send_outgoing_walkers(&outgoing_walkers, world_rank,
world_size);
// Receive all the new incoming walkers
receive_incoming_walkers(&incoming_walkers, world_rank,
world_size);
}
Todo parece normal, pero el orden de las llamadas a funciones ha introducido un escenario muy probable: punto muerto .
Interbloqueo y prevención
Según Wikipedia, el punto muerto “se refiere a una condición específica cuando dos o más procesos están esperando que el otro libere un recurso, o más de dos procesos están esperando recursos en una cadena circular. ”En nuestro caso, el código anterior resultará en una cadena circular de MPI_Sendllamadas.
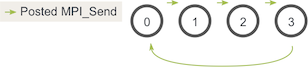
Vale la pena señalar que el código anterior en realidad no se bloqueará la mayor parte del tiempo. Aunque MPI_Sendes una llamada de bloqueo, la especificación MPI dice que MPI_Send se bloquea hasta que se pueda recuperar el búfer de envío. Esto significa que MPI_Sendvolverá cuando la red pueda almacenar el mensaje en búfer. Si los envíos finalmente no pueden ser almacenados en búfer por la red, se bloquearán hasta que se publique una recepción coincidente. En nuestro caso, hay suficientes envíos pequeños y recepciones coincidentes frecuentes como para no preocuparse por el punto muerto, sin embargo, nunca se debe suponer un búfer de red lo suficientemente grande.
Dado que solo nos estamos enfocando en MPI_Sendy MPI_Recven esta lección, la mejor manera de evitar el posible punto muerto de envío y recepción es ordenar los mensajes de manera que los envíos tengan recepciones coincidentes y viceversa. Una forma fácil de hacer esto es cambiar nuestro ciclo de modo que los procesos pares envíen caminantes salientes antes de recibir caminantes y los procesos impares hagan lo contrario. Dadas dos etapas de ejecución, el envío y la recepción ahora se verán así:
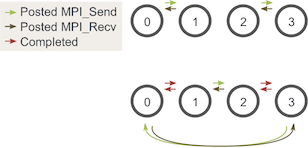
Nota : la ejecución de esto con un proceso aún puede estancarse. Para evitar esto, simplemente no realice envíos y recepciones cuando utilice un proceso.
Es posible que se esté preguntando, ¿esto todavía funciona con un número impar de procesos? Podemos volver a pasar por un diagrama similar con tres procesos:
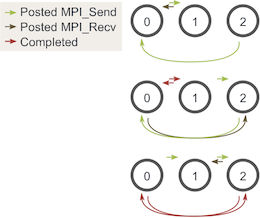
Como puede ver, en las tres etapas, hay al menos una publicación MPI_Sendque coincide con una publicada MPI_Recv, por lo que no tenemos que preocuparnos por la aparición de un punto muerto.
Determinar la finalización de todos los caminantes
Ahora viene el paso final del programa: determinar cuándo ha terminado cada caminante. Dado que los caminantes pueden caminar una longitud aleatoria, pueden terminar su viaje en cualquier proceso. Debido a esto, es difícil para todos los procesos saber cuándo han terminado todos los caminantes sin algún tipo de comunicación adicional. Una posible solución es hacer que el proceso cero realice un seguimiento de todos los caminantes que han terminado y luego les diga a todos los demás procesos cuándo terminar. Sin embargo, esta solución es bastante engorrosa ya que cada proceso tendría que informar cualquier caminante completado para procesar cero y luego también manejar diferentes tipos de mensajes entrantes.
Para esta lección, mantendremos las cosas simples. Dado que conocemos la distancia máxima que puede viajar cualquier caminante y el tamaño total más pequeño que puede viajar para cada par de envíos y recepciones (el tamaño del subdominio), podemos calcular la cantidad de envíos y recepciones que debe realizar cada proceso antes de la terminación. Usando esta característica del programa junto con nuestra estrategia para evitar el punto muerto, la parte principal final del programa se ve así:
// Find your part of the domain
decompose_domain(domain_size, world_rank, world_size,
&subdomain_start, &subdomain_size);
// Initialize walkers in your subdomain
initialize_walkers(num_walkers_per_proc, max_walk_size,
subdomain_start, subdomain_size,
&incoming_walkers);
// Determine the maximum amount of sends and receives needed to
// complete all walkers
int maximum_sends_recvs =
max_walk_size / (domain_size / world_size) + 1;
for (int m = 0; m < maximum_sends_recvs; m++) {
// Process all incoming walkers
for (int i = 0; i < incoming_walkers.size(); i++) {
walk(&incoming_walkers[i], subdomain_start, subdomain_size,
domain_size, &outgoing_walkers);
}
// Send and receive if you are even and vice versa for odd
if (world_rank % 2 == 0) {
send_outgoing_walkers(&outgoing_walkers, world_rank,
world_size);
receive_incoming_walkers(&incoming_walkers, world_rank,
world_size);
} else {
receive_incoming_walkers(&incoming_walkers, world_rank,
world_size);
send_outgoing_walkers(&outgoing_walkers, world_rank,
world_size);
}
}
Ejecutando la aplicación
A diferencia de las los apartados anteriores este código usa C ++. Al instalar MPICH2 , también instaló el compilador MPI de C ++ (a menos que lo haya configurado explícitamente de otra manera). Si instaló MPICH2 en un directorio local, asegúrese de haber configurado su variable de entorno MPICXX para que apunte al compilador mpicxx correcto para usar mi archivo MAKE.
En el código, se debe configurar el script de ejecución de la aplicación para proporcionar valores predeterminados para el programa: 100 para el tamaño del dominio, 500 para el tamaño máximo de caminata y 20 para la cantidad de caminantes por proceso. Si ejecuta el programa random_walk desde el directorio de tutoriales del repositorio , debería generar 5 procesos y producir una salida similar a esta.
>>> cd tutorials
>>> ./run.py random_walk
mpirun -n 5 ./random_walk 100 500 20
Process 2 initiated 20 walkers in subdomain 40 - 59
Process 2 sending 18 outgoing walkers to process 3
Process 3 initiated 20 walkers in subdomain 60 - 79
Process 3 sending 20 outgoing walkers to process 4
Process 3 received 18 incoming walkers
Process 3 sending 18 outgoing walkers to process 4
Process 4 initiated 20 walkers in subdomain 80 - 99
Process 4 sending 18 outgoing walkers to process 0
Process 0 initiated 20 walkers in subdomain 0 - 19
Process 0 sending 17 outgoing walkers to process 1
Process 0 received 18 incoming walkers
Process 0 sending 16 outgoing walkers to process 1
Process 0 received 20 incoming walkers
La salida continúa hasta que los procesos terminan de enviar y recibir todos los caminantes.
Puntos de comunicación y sincronización colectivos
Una de las cosas a recordar sobre la comunicación colectiva es que implica un punto de sincronización entre procesos. Esto significa que todos los procesos deben llegar a un punto en su código antes de que todos puedan comenzar a ejecutarse nuevamente.
Antes de entrar en detalles sobre las rutinas de comunicación colectiva, examinemos la sincronización con más detalle. Resulta que MPI tiene una función especial que se dedica a sincronizar procesos:
MPI_Barrier(MPI_Comm communicator)
El nombre de la función es bastante descriptivo: la función forma una barrera y ningún proceso en el comunicador puede traspasar la barrera hasta que todos llaman a la función. He aquí una ilustración. Imagine que el eje horizontal representa la ejecución del programa y los círculos representan diferentes procesos:
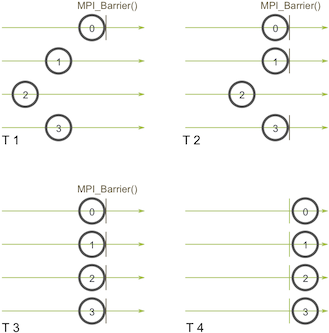
Procese cero primeras llamadas MPI_Barrieren la primera instantánea (T 1). Mientras el proceso cero está colgado en la barrera, los procesos uno y tres eventualmente lo logran (T 2). Cuando el proceso dos finalmente llega a la barrera (T 3), todos los procesos comienzan a ejecutarse nuevamente (T 4).
MPI_Barrierpuede ser útil para muchas cosas. Uno de los usos principales de MPI_Barrieres sincronizar un programa para que las partes del código paralelo puedan cronometrarse con precisión.
¿Quieres saber cómo MPI_Barrierse implementa? Seguro que sí 🙂 ¿Recuerdas el programa de timbre del tutorial de envío y recepción ? Para refrescar su memoria, escribimos un programa que pasaba un token por todos los procesos en forma de anillo. Este tipo de programa es uno de los métodos más simples para implementar una barrera, ya que un token no se puede pasar por completo hasta que todos los procesos funcionen juntos.
Una nota final sobre la sincronización: recuerde siempre que cada llamada colectiva que realiza está sincronizada. En otras palabras, si no puede completar con éxito una MPI_Barrier, tampoco podrá completar con éxito ninguna llamada colectiva. Si intenta llamar MPI_Barrieru otras rutinas colectivas sin asegurarse de que todos los procesos en el comunicador también lo llamarán, su programa quedará inactivo. Esto puede resultar muy confuso para los principiantes, ¡así que ten cuidado!
Transmitiendo con MPI_Bcast
Una transmisión es una de las técnicas de comunicación colectiva estándar. Durante una transmisión, un proceso envía los mismos datos a todos los procesos en un comunicador. Uno de los usos principales de la radiodifusión es enviar la entrada del usuario a un programa paralelo o enviar parámetros de configuración a todos los procesos.
El patrón de comunicación de una transmisión se ve así:
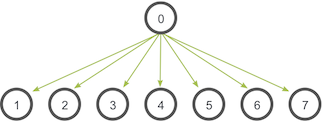
En este ejemplo, el proceso cero es el proceso raíz y tiene la copia inicial de datos. Todos los demás procesos reciben la copia de los datos.
En MPI, la transmisión se puede lograr usando MPI_Bcast. El prototipo de función se ve así:
MPI_Bcast(
void* data,
int count,
MPI_Datatype datatype,
int root,
MPI_Comm communicator)
Aunque el proceso raíz y los procesos del receptor realizan trabajos diferentes, todos llaman a la misma MPI_Bcastfunción. Cuando el proceso raíz (en nuestro ejemplo, era el proceso cero) llama MPI_Bcast, la datavariable se enviará a todos los demás procesos. Cuando todos los procesos del receptor llaman MPI_Bcast, la datavariable se completará con los datos del proceso raíz.
Transmitiendo con MPI_Send y MPI_Recv
Al principio, podría parecer que MPI_Bcastes solo un simple envoltorio alrededor de MPI_Sendy MPI_Recv. De hecho, podemos hacer que este contenedor funcione ahora mismo. Nuestra función, llamada, my_bcastse encuentra en bcast.c . Toma los mismos argumentos MPI_Bcasty se ve así:
void my_bcast(void* data, int count, MPI_Datatype datatype, int root,
MPI_Comm communicator) {
int world_rank;
MPI_Comm_rank(communicator, &world_rank);
int world_size;
MPI_Comm_size(communicator, &world_size);
if (world_rank == root) {
// If we are the root process, send our data to everyone
int i;
for (i = 0; i < world_size; i++) {
if (i != world_rank) {
MPI_Send(data, count, datatype, i, 0, communicator);
}
}
} else {
// If we are a receiver process, receive the data from the root
MPI_Recv(data, count, datatype, root, 0, communicator,
MPI_STATUS_IGNORE);
}
}
El proceso raíz envía los datos a todos los demás, mientras que los demás los reciben del proceso raíz. Fácil, ¿verdad? Si ejecuta el programa my_bcast desde el directorio de tutoriales del repositorio , la salida debería verse similar a esta.
>>> cd tutorials
>>> ./run.py my_bcast
mpirun -n 4 ./my_bcast
Process 0 broadcasting data 100
Process 2 received data 100 from root process
Process 3 received data 100 from root process
Process 1 received data 100 from root process
Lo crea o no, ¡nuestra función es realmente muy ineficiente! Imagine que cada proceso tiene solo un enlace de red saliente / entrante. Nuestra función es usar solo un enlace de red desde el proceso cero para enviar todos los datos. Una implementación más inteligente es un algoritmo de comunicación basado en árboles que puede utilizar más enlaces de red disponibles a la vez. Por ejemplo:
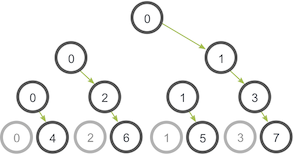
En esta ilustración, el proceso cero comienza con los datos y los envía al proceso uno. Al igual que en nuestro ejemplo anterior, el proceso cero también envía los datos al proceso dos en la segunda etapa. La diferencia con este ejemplo es que el proceso uno ahora está ayudando al proceso raíz reenviando los datos al proceso tres. Durante la segunda etapa, se utilizan dos conexiones de red a la vez. La utilización de la red se duplica en cada etapa posterior de la comunicación del árbol hasta que todos los procesos hayan recibido los datos.
Comparación de MPI_Bcast con MPI_Send y MPI_Recv
La MPI_Bcastimplementación utiliza un algoritmo de transmisión de árbol similar para una buena utilización de la red. ¿Cómo se compara nuestra función de transmisión MPI_Bcast? Podemos ejecutar compare_bcastun programa de ejemplo incluido en el código de la lección ( compare_bcast.c ). Antes de mirar el código, primero vamos a ir más de una de las funciones de sincronización de MPI – MPI_Wtime. MPI_Wtimeno toma argumentos y simplemente devuelve un número de segundos en coma flotante desde un tiempo establecido en el pasado. Similar a la timefunción de C , puede llamar a múltiples MPI_Wtimefunciones a lo largo de su programa y restar sus diferencias para obtener la sincronización de los segmentos de código.
Echemos un vistazo a nuestro código que compara my_bcast con MPI_Bcast.
for (i = 0; i < num_trials; i++) {
// Time my_bcast
// Synchronize before starting timing
MPI_Barrier(MPI_COMM_WORLD);
total_my_bcast_time -= MPI_Wtime();
my_bcast(data, num_elements, MPI_INT, 0, MPI_COMM_WORLD);
// Synchronize again before obtaining final time
MPI_Barrier(MPI_COMM_WORLD);
total_my_bcast_time += MPI_Wtime();
// Time MPI_Bcast
MPI_Barrier(MPI_COMM_WORLD);
total_mpi_bcast_time -= MPI_Wtime();
MPI_Bcast(data, num_elements, MPI_INT, 0, MPI_COMM_WORLD);
MPI_Barrier(MPI_COMM_WORLD);
total_mpi_bcast_time += MPI_Wtime();
}
En este código, num_trialses una variable que indica cuántos experimentos de sincronización se deben ejecutar. Realizamos un seguimiento del tiempo acumulado de ambas funciones en dos variables diferentes. Los tiempos medios se imprimen al final del programa. Para ver el código completo, solo mire compare_bcast.c en el código de la lección .
Si ejecuta el programa compare_bcast desde el directorio de tutoriales del repositorio , la salida debería verse similar a esta.
>>> cd tutorials
>>> ./run.py compare_bcast
/home/kendall/bin/mpirun -n 16 -machinefile hosts ./compare_bcast 100000 10
Data size = 400000, Trials = 10
Avg my_bcast time = 0.510873
Avg MPI_Bcast time = 0.126835
El script de ejecución ejecuta el código utilizando 16 procesadores, 100.000 enteros por transmisión y 10 ejecuciones de prueba para obtener resultados de tiempo. Como puede ver, mi experimento con 16 procesadores conectados a través de Ethernet muestra diferencias de tiempo significativas entre nuestra implementación ingenua y la implementación de MPI. Aquí están los resultados de cronometraje a diferentes escalas.
| Procesadores | my_bcast | MPI_Bcast |
|---|---|---|
| 2 | 0.0344 | 0.0344 |
| 4 | 0.1025 | 0.0817 |
| 8 | 0.2385 | 0.1084 |
| dieciséis | 0.5109 | 0.1296 |
Como puede ver, no hay diferencia entre las dos implementaciones en dos procesadores. Esto se debe a que MPI_Bcastla implementación del árbol no proporciona ningún uso de red adicional cuando se utilizan dos procesadores. Sin embargo, las diferencias se pueden observar claramente cuando se llega a tan solo 16 procesadores.
Introducción a MPI_Scatter
MPI_Scatteres una rutina colectiva muy similar a MPI_Bcast(Si no está familiarizado con estos términos, lea la lección anterior ). MPI_Scatterimplica un proceso raíz designado que envía datos a todos los procesos en un comunicador. La principal diferencia entre MPI_Bcasty MPI_Scatteres pequeña pero importante. MPI_Bcastenvía la misma pieza de datos a todos los procesos mientras MPI_Scatterenvía fragmentos de una matriz a diferentes procesos. Consulte la ilustración a continuación para obtener más aclaraciones.
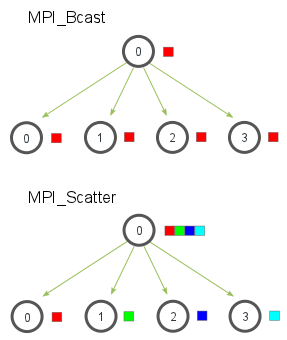
En la ilustración, MPI_Bcasttoma un solo elemento de datos en el proceso raíz (el cuadro rojo) y lo copia en todos los demás procesos. MPI_Scattertoma una matriz de elementos y distribuye los elementos en el orden de rango de proceso. El primer elemento (en rojo) va a procesar cero, el segundo elemento (en verde) va a procesar uno, y así sucesivamente. Aunque el proceso raíz (proceso cero) contiene toda la matriz de datos, MPI_Scattercopiará el elemento apropiado en el búfer receptor del proceso. Así es como se ve el prototipo de función de MPI_Scatter.
MPI_Scatter(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,
MPI_Datatype recv_datatype,
int root,
MPI_Comm communicator)
Sí, la función parece grande y aterradora, pero examinémosla con más detalle. El primer parámetro, send_dataes una matriz de datos que reside en el proceso raíz. El segundo y tercer parámetro, send_county send_datatype, dictan cuántos elementos de un tipo de datos MPI específico se enviarán a cada proceso. Si send_countes uno y send_datatypees MPI_INT, entonces el proceso cero obtiene el primer número entero de la matriz, el proceso uno obtiene el segundo número entero, y así sucesivamente. Si send_countes dos, el proceso cero obtiene el primer y el segundo enteros, el proceso uno obtiene el tercero y el cuarto, y así sucesivamente. En la práctica,send_counta menudo es igual al número de elementos de la matriz dividido por el número de procesos. ¿Qué es lo que dices? ¿El número de elementos no es divisible por el número de procesos? No se preocupe, lo cubriremos en una lección posterior 🙂
Los parámetros de recepción del prototipo de función son casi idénticos con respecto a los parámetros de envío. El recv_dataparámetro es un búfer de datos que puede contener recv_countelementos que tienen un tipo de datos de recv_datatype. Los últimos parámetros, rooty communicator, indican el proceso raíz que está dispersando la matriz de datos y el comunicador en el que residen los procesos.
Una introducción a MPI_Gather
MPI_Gatheres el inverso de MPI_Scatter. En lugar de distribuir elementos de un proceso a muchos procesos, MPI_Gathertoma elementos de muchos procesos y los reúne en un solo proceso. Esta rutina es muy útil para muchos algoritmos paralelos, como la clasificación y la búsqueda paralelas. A continuación se muestra una ilustración simple de este algoritmo.
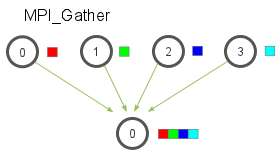
Similar a MPI_Scatter, MPI_Gathertoma elementos de cada proceso y los reúne en el proceso raíz. Los elementos están ordenados por el rango del proceso del que fueron recibidos. El prototipo de función para MPI_Gatheres idéntico al de MPI_Scatter.
MPI_Gather(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,
MPI_Datatype recv_datatype,
int root,
MPI_Comm communicator)
En MPI_Gather, solo el proceso raíz debe tener un búfer de recepción válido. Todos los demás procesos de llamadas pueden pasar NULLpor recv_data. Además, no olvide que el parámetro recv_count es el recuento de elementos recibidos por proceso , no la suma total de recuentos de todos los procesos. Esto a menudo puede confundir a los programadores MPI principiantes.
Calcular el promedio de números con MPI_Scatter y MPI_Gather
Aunque el programa que vamos a ver podría parecer bastante simple, demuestra cómo se puede usar MPI para dividir el trabajo entre procesos, realizar cálculos en subconjuntos de datos y luego agregar las piezas más pequeñas en la respuesta final. El programa sigue los siguientes pasos:
- Genere una matriz aleatoria de números en el proceso raíz (proceso 0).
- Distribuya los números a todos los procesos, dando a cada proceso la misma cantidad de números.
- Cada proceso calcula el promedio de su subconjunto de números.
- Reúna todos los promedios del proceso raíz. El proceso raíz luego calcula el promedio de estos números para obtener el promedio final.
La parte principal del código con las llamadas MPI se ve así:
if (world_rank == 0) {
rand_nums = create_rand_nums(elements_per_proc * world_size);
}
// Create a buffer that will hold a subset of the random numbers
float *sub_rand_nums = malloc(sizeof(float) * elements_per_proc);
// Scatter the random numbers to all processes
MPI_Scatter(rand_nums, elements_per_proc, MPI_FLOAT, sub_rand_nums,
elements_per_proc, MPI_FLOAT, 0, MPI_COMM_WORLD);
// Compute the average of your subset
float sub_avg = compute_avg(sub_rand_nums, elements_per_proc);
// Gather all partial averages down to the root process
float *sub_avgs = NULL;
if (world_rank == 0) {
sub_avgs = malloc(sizeof(float) * world_size);
}
MPI_Gather(&sub_avg, 1, MPI_FLOAT, sub_avgs, 1, MPI_FLOAT, 0,
MPI_COMM_WORLD);
// Compute the total average of all numbers.
if (world_rank == 0) {
float avg = compute_avg(sub_avgs, world_size);
}
Al comienzo del código, el proceso raíz crea una matriz de números aleatorios. Cuando MPI_Scatterse llama, cada proceso ahora contiene elements_per_procelementos de los datos originales. Cada proceso calcula el promedio de su subconjunto de datos y luego el proceso raíz recopila cada promedio individual. El promedio total se calcula sobre esta matriz de números mucho más pequeña.
Si ejecuta el programa avg desde el directorio de tutoriales del repositorio , la salida debería verse similar a esta. Tenga en cuenta que los números se generan aleatoriamente, por lo que su resultado final puede ser diferente al mío.
>>> cd tutorials
>>> ./run.py avg
/home/kendall/bin/mpirun -n 4 ./avg 100
Avg of all elements is 0.478699
Avg computed across original data is 0.478699
MPI_Allgather y modificación de programa medio
Hasta ahora, hemos cubierto dos rutinas MPI que realizan patrones de comunicación de muchos a uno o de uno a muchos , lo que simplemente significa que muchos procesos envían / reciben a un proceso. A menudo, es útil poder enviar muchos elementos a muchos procesos (es decir, un patrón de comunicación de muchos a muchos ). MPI_Allgathertiene esta característica.
Dado un conjunto de elementos distribuidos en todos los procesos, MPI_Allgatherreunirá todos los elementos de todos los procesos. En el sentido más básico, MPI_Allgatherva MPI_Gatherseguido de un MPI_Bcast. La siguiente ilustración muestra cómo se distribuyen los datos después de una llamada a MPI_Allgather.
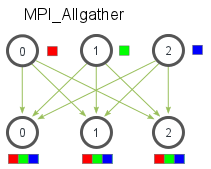
Al igual que MPI_Gather, los elementos de cada proceso se recopilan en orden de su rango, excepto que esta vez los elementos se recopilan en todos los procesos. Bastante fácil, ¿verdad? La declaración de función para MPI_Allgatheres casi idéntica a MPI_Gatherla diferencia de que no hay un proceso raíz en MPI_Allgather.
MPI_Allgather(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,
MPI_Datatype recv_datatype,
MPI_Comm communicator)
He modificado el código de cálculo promedio para usar MPI_Allgather. Puede ver la fuente en all_avg.c desde el código de esta lección . La principal diferencia en el código se muestra a continuación.
// Gather all partial averages down to all the processes
float *sub_avgs = (float *)malloc(sizeof(float) * world_size);
MPI_Allgather(&sub_avg, 1, MPI_FLOAT, sub_avgs, 1, MPI_FLOAT,
MPI_COMM_WORLD);
// Compute the total average of all numbers.
float avg = compute_avg(sub_avgs, world_size);
Los promedios parciales ahora se recopilan para todos los que usan MPI_Allgather. Los promedios ahora se imprimen de todos los procesos. La salida de ejemplo del programa debería tener el siguiente aspecto:
>>> ./run.py all_avg
/home/kendall/bin/mpirun -n 4 ./all_avg 100
Avg of all elements from proc 1 is 0.479736
Avg of all elements from proc 3 is 0.479736
Avg of all elements from proc 0 is 0.479736
Avg of all elements from proc 2 is 0.479736
Como habrá notado, la única diferencia entre all_avg.cy avg.c es que all_avg.c imprime el promedio de todos los procesos con MPI_Allgather.
Clasificación paralela: descripción general del problema
Cuando todos los procesos tienen un solo número almacenado en su memoria local, puede ser útil saber en qué orden está su número con respecto al conjunto completo de números que contienen todos los procesos. Por ejemplo, un usuario puede estar comparando los procesadores en un clúster MPI y quiere saber el orden de la velocidad de cada procesador en relación con los demás. Esta información se puede utilizar para programar tareas, etc. Como puede imaginar, es bastante difícil averiguar el orden de un número en el contexto de todos los demás números si están distribuidos entre procesos. Este problema, el problema de los rangos paralelos, es lo que vamos a resolver en esta lección.
A continuación se muestra una ilustración de la entrada y salida del rango paralelo:
Los procesos en la ilustración (etiquetados del 0 al 3) comienzan con cuatro números: 5, 2, 7 y 4. El algoritmo de rango paralelo calcula que el proceso 1 tiene rango 0 en el conjunto de números (es decir, el primer número), proceso 3 tiene rango 1, el proceso 0 tiene rango 2 y el proceso 2 tiene el último rango en el conjunto de números. Bastante simple, ¿verdad?
Definición de API de rango paralelo
Antes de sumergirnos en la solución del problema de rangos paralelos, primero decidamos cómo se comportará nuestra función. Nuestra función necesita tomar un número en cada proceso y devolver su rango asociado con respecto a todos los demás números en todos los procesos. Junto con esto, necesitaremos otra información miscelánea, como el comunicador que se está utilizando y el tipo de datos del número que se está clasificando. Dada esta definición de función, nuestro prototipo para la función de rango se ve así:
TMPI_Rank(
void *send_data,
void *recv_data,
MPI_Datatype datatype,
MPI_Comm comm)
TMPI_Ranktoma un send_databúfer que contiene un número de datatypetipo. El recv_datarecibe exactamente un número entero en cada proceso que contiene el valor de rango para send_data. La commvariable es el comunicador en el que se realiza la clasificación.
Nota – El estándar MPI dice explícitamente que los usuarios no deben nombrar sus propias funciones
MPI_<something>para evitar confundir las funciones del usuario con funciones en el propio estándar MPI. Por lo tanto, agregaremos el prefijo a las funciones en estos tutorialesT.
Resolver el problema de rangos paralelos
Ahora que tenemos nuestra definición de API, podemos profundizar en cómo se resuelve el problema de rango paralelo. El primer paso para resolver el problema de rangos paralelos es ordenar todos los números en todos los procesos. Esto debe lograrse para que podamos encontrar el rango de cada número en el conjunto completo de números. Hay varias formas de lograr esto. La forma más sencilla es reunir todos los números en un proceso y ordenarlos. En el código de ejemplo ( tmpi_rank.c ), la gather_numbers_to_rootfunción es responsable de recopilar todos los números del proceso raíz.
// Gathers numbers for TMPI_Rank to process zero. Allocates space for
// the MPI datatype and returns a void * buffer to process 0.
// It returns NULL to all other processes.
void *gather_numbers_to_root(void *number, MPI_Datatype datatype,
MPI_Comm comm) {
int comm_rank, comm_size;
MPI_Comm_rank(comm, &comm_rank);
MPI_Comm_size(comm, &comm_size);
// Allocate an array on the root process of a size depending
// on the MPI datatype being used.
int datatype_size;
MPI_Type_size(datatype, &datatype_size);
void *gathered_numbers;
if (comm_rank == 0) {
gathered_numbers = malloc(datatype_size * comm_size);
}
// Gather all of the numbers on the root process
MPI_Gather(number, 1, datatype, gathered_numbers, 1,
datatype, 0, comm);
return gathered_numbers;
}
La gather_numbers_to_rootfunción toma el número (es decir, la send_datavariable) que se recopilará, el datatypedel número y el commcomunicador. El proceso raíz debe recopilar comm_sizenúmeros en esta función, por lo que malloca una matriz de datatype_size * comm_sizelongitud. La datatype_sizevariable se recogió mediante el uso de una nueva función MPI en este tutorial – MPI_Type_size. Aunque nuestro código solo admite MPI_INTy MPI_FLOATcomo tipo de datos, este código podría ampliarse para admitir tipos de datos de diferentes tamaños. Una vez que se han recopilado los números en el proceso raíz con MPI_Gather, los números deben ordenarse en el proceso raíz para poder determinar su clasificación.
Ordenar números y mantener la propiedad
Ordenar números no es necesariamente un problema difícil en nuestra función de clasificación. La biblioteca estándar de C nos proporciona algoritmos de clasificación populares como qsort. La dificultad de ordenar con nuestro problema de rango paralelo es que debemos mantener los rangos que enviaron los números al proceso raíz. Si tuviéramos que ordenar la lista de números recopilados para el proceso raíz sin adjuntar información adicional a los números, ¡el proceso raíz no tendría idea de cómo enviar las filas de los números a los procesos solicitantes!
Para facilitar la vinculación del proceso de propiedad a los números, creamos una estructura en el código que contiene esta información. Nuestra definición de estructura es la siguiente:
// Holds the communicator rank of a process along with the
// corresponding number. This struct is used for sorting
// the values and keeping the owning process information
// intact.
typedef struct {
int comm_rank;
union {
float f;
int i;
} number;
} CommRankNumber;
La CommRankNumberestructura contiene el número que vamos a ordenar (recuerde que puede ser un flotante o un int, por lo que usamos una unión) y tiene el rango de comunicador del proceso que posee el número. La siguiente parte del código, la get_ranksfunción, es responsable de crear estas estructuras y ordenarlas.
// This function sorts the gathered numbers on the root process and
// returns an array of ordered by the process's rank in its
// communicator. Note - this function is only executed on the root
// process.
int *get_ranks(void *gathered_numbers, int gathered_number_count,
MPI_Datatype datatype) {
int datatype_size;
MPI_Type_size(datatype, &datatype_size);
// Convert the gathered number array to an array of CommRankNumbers.
// This allows us to sort the numbers and also keep the information
// of the processes that own the numbers intact.
CommRankNumber *comm_rank_numbers = malloc(
gathered_number_count * sizeof(CommRankNumber));
int i;
for (i = 0; i < gathered_number_count; i++) {
comm_rank_numbers[i].comm_rank = i;
memcpy(&(comm_rank_numbers[i].number),
gathered_numbers + (i * datatype_size),
datatype_size);
}
// Sort the comm rank numbers based on the datatype
if (datatype == MPI_FLOAT) {
qsort(comm_rank_numbers, gathered_number_count,
sizeof(CommRankNumber), &compare_float_comm_rank_number);
} else {
qsort(comm_rank_numbers, gathered_number_count,
sizeof(CommRankNumber), &compare_int_comm_rank_number);
}
// Now that the comm_rank_numbers are sorted, make an array of rank
// values for each process. The ith element of this array contains
// the rank value for the number sent by process i.
int *ranks = (int *)malloc(sizeof(int) * gathered_number_count);
for (i = 0; i < gathered_number_count; i++) {
ranks[comm_rank_numbers[i].comm_rank] = i;
}
// Clean up and return the rank array
free(comm_rank_numbers);
return ranks;
}
La get_ranksfunción primero crea una matriz de CommRankNumberestructuras y adjunta el rango de comunicador del proceso al que pertenece el número. Si el tipo de datos es MPI_FLOAT, qsortse llama con una función de clasificación especial para nuestra matriz de estructuras (consulte tmpi_rank.c para obtener el código). Del mismo modo, usamos una función de clasificación diferente si el tipo de datos es MPI_INT.
Una vez ordenados los números, debemos crear una matriz de rangos en el orden correcto para que puedan distribuirse de nuevo a los procesos solicitantes. Esto se logra haciendo la ranksmatriz y completando los valores de rango adecuados para cada una de las CommRankNumberestructuras ordenadas .
Poniendolo todo junto
Ahora que tenemos nuestras dos funciones principales, podemos ponerlas todas juntas en nuestra TMPI_Rankfunción. Esta función reúne los números del proceso raíz, ordena los números para determinar sus rangos y luego los dispersa de nuevo a los procesos solicitantes. El código se muestra a continuación:
// Gets the rank of the recv_data, which is of type datatype. The rank
// is returned in send_data and is of type datatype.
int TMPI_Rank(void *send_data, void *recv_data, MPI_Datatype datatype,
MPI_Comm comm) {
// Check base cases first - Only support MPI_INT and MPI_FLOAT for
// this function.
if (datatype != MPI_INT && datatype != MPI_FLOAT) {
return MPI_ERR_TYPE;
}
int comm_size, comm_rank;
MPI_Comm_size(comm, &comm_size);
MPI_Comm_rank(comm, &comm_rank);
// To calculate the rank, we must gather the numbers to one
// process, sort the numbers, and then scatter the resulting rank
// values. Start by gathering the numbers on process 0 of comm.
void *gathered_numbers = gather_numbers_to_root(send_data, datatype,
comm);
// Get the ranks of each process
int *ranks = NULL;
if (comm_rank == 0) {
ranks = get_ranks(gathered_numbers, comm_size, datatype);
}
// Scatter the rank results
MPI_Scatter(ranks, 1, MPI_INT, recv_data, 1, MPI_INT, 0, comm);
// Do clean up
if (comm_rank == 0) {
free(gathered_numbers);
free(ranks);
}
}
La TMPI_Rankfunción usa las dos funciones que acabamos de crear gather_numbers_to_rooty get_ranks, para obtener los rangos de los números. Luego, la función realiza la final MPI_Scatterpara dispersar los rangos resultantes a los procesos.
Si ha tenido problemas para seguir la solución al problema de rango paralelo, he incluido una ilustración de todo el flujo de datos de nuestro problema utilizando un conjunto de datos de ejemplo:
¿Tiene alguna pregunta sobre cómo funciona el algoritmo de rango paralelo? ¡Déjalos abajo!
Ejecutando nuestro algoritmo de rango paralelo
He incluido un pequeño programa en el código de ejemplo para ayudar a probar nuestro algoritmo de rango paralelo. El código se puede ver en el archivo de archivo random_rank.c en el código de la lección .
La aplicación de ejemplo simplemente crea un número aleatorio en cada proceso y llama TMPI_Rankpara obtener el rango de cada número. Si ejecuta el programa random_rank desde el directorio de tutoriales del repositorio , la salida debería verse similar a esta.
>>> cd tutorials
>>> ./run.py random_rank
mpirun -n 4 ./random_rank 100
Rank for 0.242578 on process 0 - 0
Rank for 0.894732 on process 1 - 3
Rank for 0.789463 on process 2 - 2
Rank for 0.684195 on process 3 - 1
Una introducción para reducir
Reducir es un concepto clásico de la programación funcional. La reducción de datos implica reducir un conjunto de números a un conjunto más pequeño de números a través de una función. Por ejemplo, digamos que tenemos una lista de números [1, 2, 3, 4, 5]. Reducir esta lista de números con la función de suma produciría sum([1, 2, 3, 4, 5]) = 15. De manera similar, la reducción de la multiplicación cedería multiply([1, 2, 3, 4, 5]) = 120.
Como puede haber imaginado, puede resultar muy engorroso aplicar funciones de reducción en un conjunto de números distribuidos. Junto con eso, es difícil programar de manera eficiente reducciones no conmutativas, es decir, reducciones que deben ocurrir en un orden establecido. Afortunadamente, MPI tiene una función útil llamada MPI_Reduceque manejará casi todas las reducciones comunes que un programador necesita hacer en una aplicación paralela.
MPI_Reduce
Similar a MPI_Gather, MPI_Reducetoma una matriz de elementos de entrada en cada proceso y devuelve una matriz de elementos de salida al proceso raíz. Los elementos de salida contienen el resultado reducido. El prototipo de MPI_Reducetiene este aspecto:
MPI_Reduce(
void* send_data,
void* recv_data,
int count,
MPI_Datatype datatype,
MPI_Op op,
int root,
MPI_Comm communicator)
El send_dataparámetro es una matriz de elementos de tipo datatypeque cada proceso quiere reducir. El recv_datasólo es relevante en el proceso con un rango de root. La recv_datamatriz contiene el resultado reducido y tiene un tamaño de sizeof(datatype) * count. El opparámetro es la operación que desea aplicar a sus datos. MPI contiene un conjunto de operaciones de reducción comunes que se pueden utilizar. Aunque se pueden definir operaciones de reducción personalizadas, está más allá del alcance de esta lección. Las operaciones de reducción definidas por MPI incluyen:
MPI_MAX– Devuelve el elemento máximo.MPI_MIN– Devuelve el elemento mínimo.MPI_SUM– Suma los elementos.MPI_PROD– Multiplica todos los elementos.MPI_LAND– Realiza un proceso lógico y transversal a los elementos.MPI_LOR– Realiza una lógica o transversal a los elementos.MPI_BAND– Realiza un bit a bit y a través de los bits de los elementos.MPI_BOR– Realiza un bit a bit oa través de los bits de los elementos.MPI_MAXLOC– Devuelve el valor máximo y el rango del proceso al que pertenece.MPI_MINLOC– Devuelve el valor mínimo y el rango del proceso al que pertenece.
A continuación se muestra una ilustración del patrón de comunicación de MPI_Reduce.
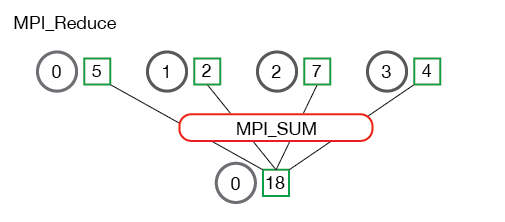
En lo anterior, cada proceso contiene un número entero. MPI_Reducese llama con un proceso raíz de 0 y se usa MPI_SUMcomo operación de reducción. Los cuatro números se suman al resultado y se almacenan en el proceso raíz.
También es útil para ver qué sucede cuando los procesos contienen múltiples elementos. La siguiente ilustración muestra la reducción de varios números por proceso.
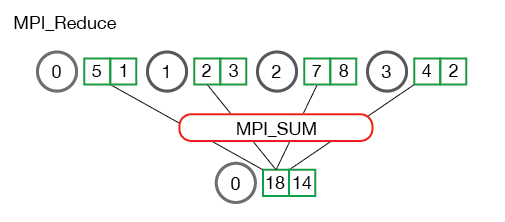
Cada uno de los procesos de la ilustración anterior tiene dos elementos. La suma resultante ocurre por elemento. En otras palabras, en lugar de sumar todos los elementos de todas las matrices en un elemento, el i- ésimo elemento de cada matriz se suma al i- ésimo elemento en la matriz de resultados del proceso 0.
Ahora que comprende cómo se MPI_Reduceve, podemos pasar a algunos ejemplos de código.
Calcular el promedio de números con MPI_Reduce
En la lección anterior , le mostré cómo calcular el promedio usando MPI_Scattery MPI_Gather. El uso MPI_Reducesimplifica bastante el código de la última lección. A continuación se muestra un extracto de reduce_avg.c en el código de ejemplo de esta lección.
float *rand_nums = NULL;
rand_nums = create_rand_nums(num_elements_per_proc);
// Sum the numbers locally
float local_sum = 0;
int i;
for (i = 0; i < num_elements_per_proc; i++) {
local_sum += rand_nums[i];
}
// Print the random numbers on each process
printf("Local sum for process %d - %f, avg = %f\n",
world_rank, local_sum, local_sum / num_elements_per_proc);
// Reduce all of the local sums into the global sum
float global_sum;
MPI_Reduce(&local_sum, &global_sum, 1, MPI_FLOAT, MPI_SUM, 0,
MPI_COMM_WORLD);
// Print the result
if (world_rank == 0) {
printf("Total sum = %f, avg = %f\n", global_sum,
global_sum / (world_size * num_elements_per_proc));
}
En el código anterior, cada proceso crea números aleatorios y realiza un local_sumcálculo. El local_sumse reduce entonces al proceso de raíz utilizando MPI_SUM. El promedio global es entonces global_sum / (world_size * num_elements_per_proc). Si ejecuta el programa reduce_avg desde el directorio de tutoriales del repositorio , la salida debería verse similar a esta.
>>> cd tutorials
>>> ./run.py reduce_avg
mpirun -n 4 ./reduce_avg 100
Local sum for process 0 - 51.385098, avg = 0.513851
Local sum for process 1 - 51.842468, avg = 0.518425
Local sum for process 2 - 49.684948, avg = 0.496849
Local sum for process 3 - 47.527420, avg = 0.475274
Total sum = 200.439941, avg = 0.501100
Ahora es el momento de pasar al hermano de MPI_Reduce– MPI_Allreduce.
MPI_Allreduce
Muchas aplicaciones paralelas requerirán acceder a los resultados reducidos en todos los procesos en lugar del proceso raíz. En un estilo complementario similar de MPI_Allgathera MPI_Gather, MPI_Allreducereducirá los valores y distribuirá los resultados a todos los procesos. El prototipo de función es el siguiente:
MPI_Allreduce(
void* send_data,
void* recv_data,
int count,
MPI_Datatype datatype,
MPI_Op op,
MPI_Comm communicator)
Como habrás notado, MPI_Allreducees idéntico MPI_Reducecon la excepción de que no necesita una identificación de proceso raíz (ya que los resultados se distribuyen a todos los procesos). A continuación se ilustra el patrón de comunicación de MPI_Allreduce:
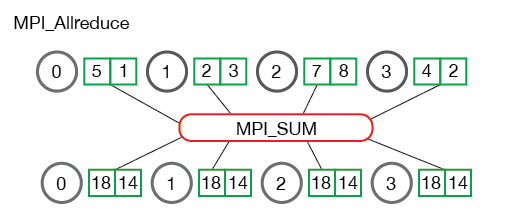
MPI_Allreducees el equivalente a hacer MPI_Reduceseguido de un MPI_Bcast. Bastante simple, ¿verdad?
Calcular la desviación estándar con MPI_Allreduce
Muchos problemas computacionales requieren hacer múltiples reducciones para resolver problemas. Uno de esos problemas es encontrar la desviación estándar de un conjunto distribuido de números. Para aquellos que lo hayan olvidado, la desviación estándar es una medida de la dispersión de los números de su media. Una desviación estándar más baja significa que los números están más juntos y viceversa para desviaciones estándar más altas.
Para encontrar la desviación estándar, primero se debe calcular el promedio de todos los números. Una vez calculado el promedio, se calculan las sumas de la diferencia al cuadrado de la media. La raíz cuadrada del promedio de las sumas es el resultado final. Dada la descripción del problema, sabemos que habrá al menos dos sumas de todos los números, lo que se traduce en dos reducciones. Un extracto de reduce_stddev.c en el código de la lección muestra cómo se ve esto en MPI.
rand_nums = create_rand_nums(num_elements_per_proc);
// Sum the numbers locally
float local_sum = 0;
int i;
for (i = 0; i < num_elements_per_proc; i++) {
local_sum += rand_nums[i];
}
// Reduce all of the local sums into the global sum in order to
// calculate the mean
float global_sum;
MPI_Allreduce(&local_sum, &global_sum, 1, MPI_FLOAT, MPI_SUM,
MPI_COMM_WORLD);
float mean = global_sum / (num_elements_per_proc * world_size);
// Compute the local sum of the squared differences from the mean
float local_sq_diff = 0;
for (i = 0; i < num_elements_per_proc; i++) {
local_sq_diff += (rand_nums[i] - mean) * (rand_nums[i] - mean);
}
// Reduce the global sum of the squared differences to the root
// process and print off the answer
float global_sq_diff;
MPI_Reduce(&local_sq_diff, &global_sq_diff, 1, MPI_FLOAT, MPI_SUM, 0,
MPI_COMM_WORLD);
// The standard deviation is the square root of the mean of the
// squared differences.
if (world_rank == 0) {
float stddev = sqrt(global_sq_diff /
(num_elements_per_proc * world_size));
printf("Mean - %f, Standard deviation = %f\n", mean, stddev);
}
En el código anterior, cada proceso calcula la cantidad local_sumde elementos y los suma usando MPI_Allreduce. Una vez que la suma global está disponible en todos los procesos, meanse calcula para que local_sq_diffse pueda calcular. Una vez que se calculan todas las diferencias cuadradas locales, se calcula global_sq_diffutilizando MPI_Reduce. El proceso de raíz puede entonces calcular la desviación estándar tomando la raíz cuadrada de la media de las diferencias cuadradas globales.
La ejecución del código de ejemplo con el script de ejecución produce un resultado similar al siguiente:
>>> ./run.py reduce_stddev
mpirun -n 4 ./reduce_stddev 100
Mean - 0.501100, Standard deviation = 0.301126
Resumen de comunicadores
Como hemos visto al aprender sobre rutinas colectivas, MPI le permite hablar con todos los procesos en un comunicador a la vez para hacer cosas como distribuir datos de un proceso a muchos procesos usando MPI_Scattero realizar una reducción de datos usando MPI_Reduce. Sin embargo, hasta ahora, sólo hemos utilizado el comunicador por defecto, MPI_COMM_WORLD.
Para aplicaciones simples, no es inusual hacer todo usando MPI_COMM_WORLD, pero para casos de uso más complejos, puede ser útil tener más comunicadores. Un ejemplo podría ser si desea realizar cálculos en un subconjunto de los procesos en una cuadrícula. Por ejemplo, es posible que todos los procesos de cada fila quieran sumar un valor. Esto nos lleva a la primera y más común función utilizada para crear nuevos comunicadores:
MPI_Comm_split(
MPI_Comm comm,
int color,
int key,
MPI_Comm* newcomm)
Como su nombre lo indica, MPI_Comm_splitcrea nuevos comunicadores al «dividir» un comunicador en un grupo de subcomunicadores en función de los valores de entrada colory key. Es importante señalar aquí que el comunicador original no desaparece, pero se crea un nuevo comunicador en cada proceso. El primer argumento, commes el comunicador que se utilizará como base para los nuevos comunicadores. Esto podría ser MPI_COMM_WORLD, pero también podría ser cualquier otro comunicador. El segundo argumento, colordetermina a qué nuevo comunicador pertenecerá cada proceso. Todos los procesos que pasan el mismo valor para colorse asignan al mismo comunicador. Si colores así MPI_UNDEFINED, ese proceso no se incluirá en ninguno de los nuevos comunicadores. El tercer argumento,key, determina el orden (rango) dentro de cada nuevo comunicador. El proceso que pasa en el valor más pequeño keyserá el rango 0, el siguiente más pequeño será el rango 1, y así sucesivamente. Si hay un empate, el proceso que tuvo el rango más bajo en el comunicador original será el primero. El argumento final newcommes cómo MPI devuelve el nuevo comunicador al usuario.
Ejemplo de uso de varios comunicadores
Ahora veamos un ejemplo simple en el que intentamos dividir un solo comunicador global en un conjunto de comunicadores más pequeños. En este ejemplo, imaginaremos que hemos dispuesto lógicamente nuestro comunicador original en una cuadrícula 4×4 de 16 procesos y queremos dividir la cuadrícula por fila. Para hacer esto, cada fila obtendrá su propio color. En la imagen de abajo, puedes ver cómo cada grupo de procesos con el mismo color a la izquierda termina en su propio comunicador a la derecha.
Veamos el código para esto.
// Get the rank and size in the original communicator
int world_rank, world_size;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
int color = world_rank / 4; // Determine color based on row
// Split the communicator based on the color and use the
// original rank for ordering
MPI_Comm row_comm;
MPI_Comm_split(MPI_COMM_WORLD, color, world_rank, &row_comm);
int row_rank, row_size;
MPI_Comm_rank(row_comm, &row_rank);
MPI_Comm_size(row_comm, &row_size);
printf("WORLD RANK/SIZE: %d/%d \t ROW RANK/SIZE: %d/%d\n",
world_rank, world_size, row_rank, row_size);
MPI_Comm_free(&row_comm);
Las primeras líneas obtienen el rango y tamaño para el comunicador original, MPI_COMM_WORLD. La siguiente línea hace la importante operación de determinar el «color» del proceso local. Recuerde que el color decide a qué comunicador pertenecerá el proceso después de la división. A continuación, vemos la importante operación de división. Lo nuevo aquí es que estamos usando el rango original ( world_rank) como clave para la operación de división. Dado que queremos que todos los procesos en el nuevo comunicador estén en el mismo orden en que estaban en el comunicador original, usar el valor de rango original tiene más sentido aquí, ya que ya estará ordenado correctamente. Después de eso, imprimimos el nuevo rango y tamaño solo para asegurarnos de que funcione. Su salida debería verse así:
WORLD RANK/SIZE: 0/16 ROW RANK/SIZE: 0/4
WORLD RANK/SIZE: 1/16 ROW RANK/SIZE: 1/4
WORLD RANK/SIZE: 2/16 ROW RANK/SIZE: 2/4
WORLD RANK/SIZE: 3/16 ROW RANK/SIZE: 3/4
WORLD RANK/SIZE: 4/16 ROW RANK/SIZE: 0/4
WORLD RANK/SIZE: 5/16 ROW RANK/SIZE: 1/4
WORLD RANK/SIZE: 6/16 ROW RANK/SIZE: 2/4
WORLD RANK/SIZE: 7/16 ROW RANK/SIZE: 3/4
WORLD RANK/SIZE: 8/16 ROW RANK/SIZE: 0/4
WORLD RANK/SIZE: 9/16 ROW RANK/SIZE: 1/4
WORLD RANK/SIZE: 10/16 ROW RANK/SIZE: 2/4
WORLD RANK/SIZE: 11/16 ROW RANK/SIZE: 3/4
WORLD RANK/SIZE: 12/16 ROW RANK/SIZE: 0/4
WORLD RANK/SIZE: 13/16 ROW RANK/SIZE: 1/4
WORLD RANK/SIZE: 14/16 ROW RANK/SIZE: 2/4
WORLD RANK/SIZE: 15/16 ROW RANK/SIZE: 3/4
No se alarme si el suyo no está en el orden correcto. Cuando imprime cosas en un programa MPI, cada proceso tiene que enviar su salida al lugar donde inició su trabajo MPI antes de que pueda imprimirse en la pantalla. Esto tiende a significar que el orden se confunde, por lo que nunca puede suponer que solo porque imprime las cosas en un orden de clasificación específico, la salida terminará en el mismo orden que espera. La salida se reorganizó aquí para que se vea bien.
Finalmente, liberamos el comunicador con MPI_Comm_free. Parece que no es un paso importante, pero es tan importante como liberar tu memoria cuando termines con cualquier otro programa. Cuando un objeto MPI ya no se utilizará, debe liberarse para poder reutilizarlo más tarde. MPI tiene un número limitado de objetos que puede crear a la vez y no liberar sus objetos podría resultar en un error de tiempo de ejecución si MPI se queda sin objetos asignables.
Otras funciones de creación de comunicadores
Si bien MPI_Comm_splites la función de creación de comunicadores más común, existen muchas otras. MPI_Comm_dupes el más básico y crea un duplicado de un comunicador. Puede parecer extraño que exista una función que solo crea una copia, pero esto es muy útil para aplicaciones que usan bibliotecas para realizar funciones especializadas, como bibliotecas matemáticas. En este tipo de aplicaciones, es importante que los códigos de usuario y los códigos de biblioteca no interfieran entre sí. Para evitar esto, lo primero que debe hacer toda aplicación es crear un duplicado de MPI_COMM_WORLD, lo que evitará el problema de que otras bibliotecas también lo utilicen MPI_COMM_WORLD. Las propias bibliotecas también deberían hacer duplicados MPI_COMM_WORLDpara evitar el mismo problema.
Otra función es MPI_Comm_create. A primera vista, esta función se parece mucho a MPI_Comm_create_group. Su firma es casi idéntica:
MPI_Comm_create(
MPI_Comm comm,
MPI_Group group,
MPI_Comm* newcomm)
Sin embargo, la diferencia clave (además de la falta del tagargumento), es que MPI_Comm_create_groupes solo colectivo sobre el grupo de procesos contenido en group, donde MPI_Comm_createes colectivo sobre cada proceso en comm. Ésta es una distinción importante ya que el tamaño de los comunicadores crece mucho. Si intenta crear un subconjunto de MPI_COMM_WORLDcuando se ejecuta con 1,000,000 de procesos, es importante realizar la operación con la menor cantidad de procesos posible, ya que el colectivo se vuelve muy costoso en tamaños grandes.
Hay otras características más avanzadas de los comunicadores que no cubrimos aquí, como las diferencias entre intercomunicadores e intracomunicadores y otras funciones avanzadas de creación de comunicadores. Estos solo se utilizan en tipos de aplicaciones muy específicos que pueden tratarse en un tutorial futuro.
Resumen de grupos
Si bien MPI_Comm_splites la forma más sencilla de crear un nuevo comunicador, no es la única forma de hacerlo. Hay formas más flexibles para crear comunicadores, sino que utilizan un nuevo tipo de objeto MPI, MPI_Group. Antes de entrar en muchos detalles sobre los grupos, veamos un poco más qué es realmente un comunicador. Internamente, MPI tiene que mantenerse al día (entre otras cosas) con dos partes principales de un comunicador, el contexto (o ID) que diferencia a un comunicador de otro y el grupo de procesos que contiene el comunicador. El contexto es lo que evita que una operación en un comunicador coincida con una operación similar en otro comunicador. MPI mantiene una identificación para cada comunicador internamente para evitar confusiones. El grupo es un poco más simple de entender ya que es solo el conjunto de todos los procesos en el comunicador. ParaMPI_COMM_WORLD, estos son todos los procesos iniciados por mpiexec. Para otros comunicadores, el grupo será diferente. En el código de ejemplo anterior, el grupo es todos los procesos que transmiten en el mismo colora MPI_Comm_split.
MPI usa estos grupos de la misma manera que generalmente funciona la teoría de conjuntos. No es necesario que esté familiarizado con toda la teoría de conjuntos para comprender las cosas, pero es útil saber qué significan dos operaciones. Aquí, en lugar de referirnos a «conjuntos», usaremos el término «grupos» como se aplica a MPI. Primero, la operación de unión crea un nuevo conjunto (potencialmente) más grande a partir de otros dos conjuntos. El nuevo conjunto incluye todos los miembros de los dos primeros conjuntos (sin duplicados). En segundo lugar, la operación de intersección crea un nuevo conjunto (potencialmente) más pequeño a partir de otros dos conjuntos. El nuevo conjunto incluye todos los miembros que están presentes en los dos conjuntos originales. Puede ver ejemplos de ambas operaciones gráficamente a continuación.
En el primer ejemplo, la unión de los dos grupos {0, 1, 2, 3}y {2, 3, 4, 5}se {0, 1, 2, 3, 4, 5}debe a que cada uno de esos elementos aparece en cada grupo. En el segundo ejemplo, la intersección de los dos grupos {0, 1, 2, 3}, y {2, 3, 4, 5}se {2, 3}debe a que solo esos elementos aparecen en cada grupo.
Usar grupos MPI
Ahora que entendemos los fundamentos de cómo funcionan los grupos, veamos cómo se pueden aplicar a las operaciones de MPI. En MPI, es fácil de obtener el conjunto de procesos en un comunicador con la llamada a la API, MPI_Comm_group.
MPI_Comm_group(
MPI_Comm comm,
MPI_Group* group)
Como se mencionó anteriormente, un comunicador contiene un contexto o ID y un grupo. La llamada MPI_Comm_groupobtiene una referencia a ese objeto de grupo. El objeto de grupo funciona de la misma manera que un objeto de comunicador, excepto que no puede usarlo para comunicarse con otros rangos (porque no tiene ese contexto adjunto). Aún puede obtener el rango y el tamaño del grupo ( MPI_Group_rankyMPI_Group_size, respectivamente). Sin embargo, lo que puede hacer con los grupos que no puede hacer con los comunicadores es usarlo para construir nuevos grupos localmente. Es importante recordar aquí la diferencia entre una operación local y una remota. Una operación remota implica la comunicación con otros rangos donde una operación local no lo hace. La creación de un nuevo comunicador es una operación remota porque todos los procesos deben decidir sobre el mismo contexto y grupo, donde la creación de un grupo es local porque no se usa para la comunicación y, por lo tanto, no necesita tener el mismo contexto para cada proceso. Puede manipular un grupo todo lo que quiera sin realizar ninguna comunicación en absoluto.
Una vez que tenga un grupo o dos, realizar operaciones en ellos es sencillo. Conseguir la unión se ve así:
MPI_Group_union(
MPI_Group group1,
MPI_Group group2,
MPI_Group* newgroup)
Y probablemente puedas adivinar que la intersección se ve así:
MPI_Group_intersection(
MPI_Group group1,
MPI_Group group2,
MPI_Group* newgroup)
En ambos casos, la operación se realiza en group1y group2y el resultado se almacena en newgroup.
Hay muchos usos de grupos en MPI. Puede comparar grupos para ver si son iguales, restar un grupo de otro, excluir rangos específicos de un grupo o usar un grupo para traducir los rangos de un grupo a otro grupo. Sin embargo, una de las adiciones recientes a MPI que tiende a ser más útil es MPI_Comm_create_group. Esta es una función para crear un nuevo comunicador, pero en lugar de hacer cálculos sobre la marcha para decidir la composición, como MPI_Comm_split, esta función toma un MPI_Groupobjeto y crea un nuevo comunicador que tiene todos los mismos procesos que el grupo.
MPI_Comm_create_group(
MPI_Comm comm,
MPI_Group group,
int tag,
MPI_Comm* newcomm)
Ejemplo de uso de grupos
Veamos un ejemplo rápido de cómo se ven los grupos de uso. A continuación, vamos a utilizar otra nueva función que le permite elegir filas específicas en un grupo y construir un nuevo grupo que contiene sólo aquellas filas, MPI_Group_incl.
MPI_Group_incl(
MPI_Group group,
int n,
const int ranks[],
MPI_Group* newgroup)
Con esta función, newgroupcontiene los procesos groupcon rangos contenidos en ranks, que es de tamaño n. ¿Quieres ver cómo funciona? Intentemos crear un comunicador que contenga los primeros rangos de MPI_COMM_WORLD.
// Get the rank and size in the original communicator
int world_rank, world_size;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
// Get the group of processes in MPI_COMM_WORLD
MPI_Group world_group;
MPI_Comm_group(MPI_COMM_WORLD, &world_group);
int n = 7;
const int ranks[7] = {1, 2, 3, 5, 7, 11, 13};
// Construct a group containing all of the prime ranks in world_group
MPI_Group prime_group;
MPI_Group_incl(world_group, 7, ranks, &prime_group);
// Create a new communicator based on the group
MPI_Comm prime_comm;
MPI_Comm_create_group(MPI_COMM_WORLD, prime_group, 0, &prime_comm);
int prime_rank = -1, prime_size = -1;
// If this rank isn't in the new communicator, it will be
// MPI_COMM_NULL. Using MPI_COMM_NULL for MPI_Comm_rank or
// MPI_Comm_size is erroneous
if (MPI_COMM_NULL != prime_comm) {
MPI_Comm_rank(prime_comm, &prime_rank);
MPI_Comm_size(prime_comm, &prime_size);
}
printf("WORLD RANK/SIZE: %d/%d \t PRIME RANK/SIZE: %d/%d\n",
world_rank, world_size, prime_rank, prime_size);
MPI_Group_free(&world_group);
MPI_Group_free(&prime_group);
MPI_Comm_free(&prime_comm);
En este ejemplo, construimos un comunicador seleccionando solo los primeros rangos MPI_COMM_WORLD. Esto se hace con MPI_Group_incly da como resultado prime_group. A continuación, pasamos ese grupo MPI_Comm_create_groupa crear prime_comm. Al final, tenemos que tener cuidado de no usar prime_commen procesos que no lo tienen, por lo tanto, verificamos para asegurarnos de que el comunicador no MPI_COMM_NULLlo esté, que se devuelve MPI_Comm_create_groupen los rangos no incluidos en ranks.
¿Quiere contribuir?
Este resumen de MPI está alojado completamente en GitHub . El autor original (Wes Kendall) ya no contribuye activamente a este sitio, pero se colocó en GitHub con la esperanza de que otros escribieran tutoriales de MPI de alta calidad. Haga clic aquí para obtener más información sobre cómo puede contribuir.







Debe estar conectado para enviar un comentario.