
El objetivo de esta post es en primer lugar comprender como se puede ejecutar la multitarea en el ESP32 para después ver como se implementa un algoritmo de cálculo de potencia simple en el ESP32 y probar la aceleración ejecutándolo en los dos núcleos del microcontrolador.
El ESP32 viene con 2 microprocesadores Xtensa LX6 de 32 bits: core 0 y core 1. Entonces, es dual core. Cuando ejecutamos código en Arduino IDE, de forma predeterminada, se ejecuta en el núcleo 1. En esta publicación, le mostraremos cómo ejecutar código en el segundo núcleo ESP32 mediante la creación de tareas. Puede ejecutar piezas de código simultáneamente en ambos núcleos y hacer que su ESP32 sea multitarea. Como nota imporante no necesariamente necesita ejecutar doble núcleo para lograr la multitarea.
El ESP32 por tanto tiene dos núcleos Tensilica LX6 [1] que podemos usar para ejecutar código. Al momento de escribir, la forma más fácil de controlar la ejecución de código en los diferentes núcleos del ESP32 es usando FreeRTOS y asignar una tarea a cada CPU
Aunque de forma genérica son muchos los beneficios de tener más de un núcleo disponible para ejecutar código, uno de los más importantes es aumentar el rendimiento de nuestros programas. Entonces, aunque veremos en este post cómo ejecutar código en los dos núcleos del ESP32, también comprobaremos el aumento de rendimiento que podemos obtener de eso mediante una aplicación simple que sea capaz de calcular una potencia de los números de una matriz. Lo ejecutaremos en un solo núcleo y luego dividiremos el procesamiento por los dos núcleos y verificaremos si hay una ganancia en el tiempo de ejecución. Finalmente, solo para comparar, también dividiremos la ejecución entre cuatro tareas (dos asignadas a cada núcleo) solo para verificar si hay alguna aceleración para generar más tareas que núcleos.

Introducción
El ESP32 viene con 2 microprocesadores Xtensa LX6 de 32 bits, por lo que es de doble núcleo:
- Núcleo 0
- Núcleo 1

Cuando subimos el código al ESP32 usando el IDE de Arduino, simplemente se ejecuta; no tenemos que preocuparnos de qué núcleo ejecuta el código.
Hay una función que puede usar para identificar en qué núcleo se está ejecutando el código:
xPortGetCoreID()Si usa esa función en un boceto de Arduino, verá que tanto setup() para la configuración() como el loopo()se ejecutan en el núcleo 1. Pruébelo usted mismo cargando el siguiente boceto en su ESP32.
void setup() {
Serial.begin(115200);
Serial.print("setup() running on core ");
Serial.println(xPortGetCoreID());
}
void loop() {
Serial.print("loop() running on core ");
Serial.println(xPortGetCoreID());
}
Abra el Serial Monitor a una velocidad de transmisión de 115200 y verifique el núcleo en el que se ejecuta el boceto de Arduino.

Crear tareas
Arduino IDE es compatible con FreeRTOS para ESP32, que es un sistema operativo en tiempo real. Esto nos permite manejar varias tareas en paralelo que se ejecutan de forma independiente. Las tareas son fragmentos de código que ejecutan algo. Por ejemplo, puede hacer parpadear un LED, realizar una solicitud de red, medir lecturas de sensores, publicar lecturas de sensores, etc.
Para asignar partes específicas de código a un núcleo específico, debe crear tareas. Al crear una tarea, puede elegir en qué núcleo se ejecutará, así como su prioridad. Los valores de prioridad comienzan en 0, en el que 0 es la prioridad más baja. El procesador ejecutará primero las tareas con mayor prioridad.
Para crear tareas necesita seguir los siguientes pasos:
1. Crear un identificador de tarea. Un ejemplo para Task1:
TaskHandle_t Task1;2. En la configuración()crear una tarea asignada a un núcleo específico usando elxTaskCreatePinnedToCorefunción. Esa función toma varios argumentos, incluida la prioridad y el núcleo donde se debe ejecutar la tarea (el último parámetro).
xTaskCreatePinnedToCore(
Task1code, /* Function to implement the task */
"Task1", /* Name of the task */
10000, /* Stack size in words */
NULL, /* Task input parameter */
0, /* Priority of the task */
&Task1, /* Task handle. */
0); /* Core where the task should run */3. Después de crear la tarea, debe crear una función que contenga el código para la tarea creada. En este ejemplo, debe crear la tarea e1código()función. Así es como se ve la función de tarea:
Void Task1code( void * parameter) {
for(;;) {
Code for task 1 - infinite loop
(...)
}
}los for(;;)crean un bucle infinito. Por lo tanto, esta función se ejecuta de manera similar a la función loop(). Puede usarlo como un segundo ciclo en su código, por ejemplo.
Si durante la ejecución de su código desea eliminar la tarea creada, puede utilizar la función vTareaEliminar(), que acepta el identificador de tareas (Tarea 1) como argumento:
vTaskDelete(Task1);Veamos cómo funcionan estos conceptos con un ejemplo sencillo.
Crear tareas en diferentes núcleos: ejemplo
Para seguir este ejemplo usaremos las siguientes partes:
- Tablero ESP32 DOIT DEVKIT V1
- 2 LED de 5 mm
- 2 resistencias de 330 ohmios
- Tablero de circuitos
- Cables puente
Para crear diferentes tareas que se ejecuten en diferentes núcleos, crearemos dos tareas que parpadeen los LED con diferentes tiempos de retraso . Conectaremos mediante dos resistencias en serie de 330 ohmios el cátodo de un led rojo al puerto 4 (GPIO4) y el otro cátodo del led verde al GPIO2 uniendo ambas masas y conectando estas al ping GND del ESP32 .
El plano resultante seria similar al siguiente diagrama:

Crearemos dos tareas ejecutándose en diferentes núcleos:
- Task1 se ejecuta en el núcleo 0;
- Task2 se ejecuta en el núcleo 1;

Cargue el siguiente boceto en su ESP32 para hacer parpadear cada LED en un núcleo diferente:
TaskHandle_t Task1;
TaskHandle_t Task2;
// LED pins
const int led1 = 2;
const int led2 = 4;
void setup() {
Serial.begin(115200);
pinMode(led1, OUTPUT);
pinMode(led2, OUTPUT);
//create a task that will be executed in the Task1code() function, with priority 1 and executed on core 0
xTaskCreatePinnedToCore(
Task1code, /* Task function. */
"Task1", /* name of task. */
10000, /* Stack size of task */
NULL, /* parameter of the task */
1, /* priority of the task */
&Task1, /* Task handle to keep track of created task */
0); /* pin task to core 0 */
delay(500);
//create a task that will be executed in the Task2code() function, with priority 1 and executed on core 1
xTaskCreatePinnedToCore(
Task2code, /* Task function. */
"Task2", /* name of task. */
10000, /* Stack size of task */
NULL, /* parameter of the task */
1, /* priority of the task */
&Task2, /* Task handle to keep track of created task */
1); /* pin task to core 1 */
delay(500);
}
//Task1code: blinks an LED every 1000 ms
void Task1code( void * pvParameters ){
Serial.print("Task1 running on core ");
Serial.println(xPortGetCoreID());
for(;;){
digitalWrite(led1, HIGH);
delay(1000);
digitalWrite(led1, LOW);
delay(1000);
}
}
//Task2code: blinks an LED every 700 ms
void Task2code( void * pvParameters ){
Serial.print("Task2 running on core ");
Serial.println(xPortGetCoreID());
for(;;){
digitalWrite(led2, HIGH);
delay(700);
digitalWrite(led2, LOW);
delay(700);
}
}
void loop() {
}
Cómo funciona el código
Nota: en el código creamos dos tareas y asignamos una tarea al núcleo 0 y otra al núcleo 1. Los bocetos de Arduino se ejecutan en el núcleo 1 de forma predeterminada. Por lo tanto, podría escribir el código para Task2 en el loop()(no hubo necesidad de crear otra tarea). En este caso, creamos dos tareas diferentes con fines de aprendizaje.
Sin embargo, según los requisitos de su proyecto, puede ser más práctico organizar su código en tareas como se muestra en este ejemplo.
El código comienza creando un identificador de tarea para Task1 y Task2 llamadoTarea 1yTarea 2.
TaskHandle_t Task1;
TaskHandle_t Task2;Asigne GPIO 2 y GPIO 4 a los LED:
const int led1 = 2;
const int led2 = 4;En la configuración(), inicialice el monitor serie a una velocidad en baudios de 115200:
Serial.begin(115200);Declare los LED como salidas:
pinMode(led1, OUTPUT);
pinMode(led2, OUTPUT);Luego, cree Task1 usando la función xTaskCreatePinnedToCore() :
xTaskCreatePinnedToCore(
Task1code, /* Task function. */
"Task1", /* name of task. */
10000, /* Stack size of task */
NULL, /* parameter of the task */
1, /* priority of the task */
&Task1, /* Task handle to keep track of created task */
0); /* pin task to core 0 */Task1 se implementará con eltarea1código()función. Entonces, necesitamos crear esa función más adelante en el código. Le damos a la tarea la prioridad 1 y la anclamos al núcleo 0.
Creamos Task2 usando el mismo método:
xTaskCreatePinnedToCore(
Task2code, /* Task function. */
"Task2", /* name of task. */
10000, /* Stack size of task */
NULL, /* parameter of the task */
1, /* priority of the task */
&Task2, /* Task handle to keep track of created task */
1); /* pin task to core 0 */Después de crear las tareas, necesitamos crear las funciones que ejecutarán esas tareas.
void Task1code( void * pvParameters ){
Serial.print("Task1 running on core ");
Serial.println(xPortGetCoreID());
for(;;){
digitalWrite(led1, HIGH);
delay(1000);
digitalWrite(led1, LOW);
delay(1000);
}
}La función para Task1 se llamatarea1código()(Puedes llamarlo como quieras). Para fines de depuración, primero imprimimos el núcleo en el que se ejecuta la tarea:
Serial.print("Task1 running on core ");
Serial.println(xPortGetCoreID());Entonces, tenemos un ciclo infinito similar alcírculo()en el boceto de Arduino. En ese ciclo, parpadeamos el LED1 cada segundo.
Lo mismo sucede con Task2, pero parpadeamos el LED con un tiempo de retraso diferente.
void Task2code( void * pvParameters ){
Serial.print("Task2 running on core ");
Serial.println(xPortGetCoreID());
for(;;){
digitalWrite(led2, HIGH);
delay(700);
digitalWrite(led2, LOW);
delay(700);
}
}Finalmente, el bucle loop tiene ()la función está vacía:
void loop() { }Nota: como se mencionó anteriormente, el bucle loop ()se ejecuta en el núcleo 1. Entonces, en lugar de crear una tarea para ejecutar en el núcleo 1, simplemente puede escribir su código dentro del loop().
Demostración
Suba el código a su ESP32. Asegúrese de tener la placa y el puerto COM correctos seleccionados.
Abra el monitor serie a una velocidad en baudios de 115200. Debería recibir los siguientes mensajes:

Como era de esperar, Task1 se ejecuta en el núcleo 0, mientras que Task2 se ejecuta en el núcleo 1.
En su circuito, un LED debe parpadear cada 1 segundo y el otro debe parpadear cada 700 milisegundos.

En resumen:
- El ESP32 es de doble núcleo;
- Los bocetos de Arduino se ejecutan en el núcleo 1 de forma predeterminada;
- Para usar core 0 necesitas crear tareas;
- Puede usar la función TaskCreatePinnedToCore() para fijar una tarea específica a un núcleo específico;
- Con este método, puede ejecutar dos tareas diferentes de forma independiente y simultánea utilizando los dos núcleos.
Hemos visto un ejemplo simple con LED. La idea es utilizar este método con proyectos más avanzados con aplicaciones del mundo real. Por ejemplo, puede ser útil usar un núcleo para tomar lecturas de sensores y otro para publicar esas lecturas en un sistema de automatización del hogar. Ahora a continuación usando la multitarea vamos a calcular como aumenta la aceleración usando ambos núcleos
Cálculo de aceleración
Básicamente, lo que queremos comprobar es cuánto aumenta la velocidad de ejecución de nuestro programa cuando pasamos de una ejecución de un solo núcleo a una ejecución de doble núcleo. Entonces, una de las formas más fáciles de hacerlo es calcular la relación entre el tiempo de ejecución del programa que se ejecuta en un solo núcleo y el que se ejecuta en los dos núcleos del ESP32 [2].
Mediremos el tiempo de ejecución para cada enfoque utilizando la función Arduino micros , que devuelve la cantidad de microsegundos desde que la placa comenzó a ejecutar el programa [3].
Entonces, para medir un bloque de ejecución de código, haremos algo similar a lo que se indica a continuación.
start = micros();
//Run code
end = micros();
execTime = end - start;
Podríamos haber usado la función FreeRTOS xTaskGetTickCount para una mayor precisión, pero la función micros será suficiente para lo que queremos mostrar y es una función muy conocida de Arduino.
Variables globales
Comenzaremos nuestro código declarando algunas variables globales auxiliares. No vamos a necesitar ningún include.
Como vamos a comparar aceleraciones en diferentes situaciones, vamos a especificar una matriz con múltiples exponentes para probar. Además, vamos a tener una variable con el tamaño de la matriz, para que podamos iterarla. Primero vamos a probar valores pequeños para el exponente y luego comenzaremos a aumentarlos mucho.
int n[10] = {2, 3, 4, 5, 10, 50, 100, 1000, 2000, 10000 };
int nArraySize = 10;
También vamos a tener algunas variables para almacenar el tiempo de ejecución del código en los diferentes casos de uso. Reutilizaremos las variables de inicio y finalización de la ejecución , pero usaremos una variable diferente para cada caso de uso: ejecución de una tarea, ejecución de dos tareas y ejecución de cuatro tareas. De esta forma, almacenaremos los valores para una última comparación.
unsigned long start;
unsigned long end;
unsigned long execTimeOneTask, execTimeTwoTask, execTimeFourTask ;Luego, declararemos un semáforo de conteo para poder sincronizar la función de configuración (que se ejecuta en una tarea de FreeRTOS) con las tareas que vamos a ejecutar. Consulte esta publicación para obtener una explicación detallada sobre cómo lograr este tipo de sincronización.
Tenga en cuenta que la función xSemaphoreCreateCounting recibe como entrada el recuento máximo y el recuento inicial del semáforo. Como tendremos como máximo 4 tareas para sincronizar, su valor máximo será 4.
SemaphoreHandle_t barrierSemaphore = xSemaphoreCreateCounting( 4, 0 );
Finalmente, declararemos dos arreglos: uno con los valores iniciales (llamado bigArray ) y otro para almacenar los resultados (llamado resultArray ). Haremos sus tallas grandes.
int bigArray[10000], resultArray[10000];
La tarea de FreeRTOS
Definiremos la función que implementará nuestro algoritmo de cálculo de potencia, para ser lanzada como tarea. Si necesita ayuda con los detalles sobre cómo definir una tarea de FreeRTOS, consulte este tutorial anterior.
Lo primero que debemos tener en cuenta es que nuestra función recibirá algunos parámetros de configuración. Dado que en algunos de los casos de uso vamos a dividir la ejecución del algoritmo en varias tareas, necesitamos controlar la parte de la matriz que cubrirá cada tarea.
Para crear solo una tarea genérica que pueda responder a todos nuestros casos de uso, pasaremos como parámetro los índices de la matriz de la que será responsable la tarea. Además, vamos a pasar el exponente, así que ahora sabemos cuántas multiplicaciones necesitamos realizar. Puede consultar con más detalle cómo pasar un argumento a una tarea de FreeRTOS en este tutorial anterior.
Entonces, primero definiremos una estructura con estos 3 parámetros, para poder pasarla a nuestra función. Puedes leer más sobre estructuras aquí . Tenga en cuenta que esta estructura se declara fuera de cualquier función. Entonces, el código se puede colocar cerca de la declaración de variables globales.
struct argsStruct {
int arrayStart;
int arrayEnd;
int n;
};Como ya tenemos declarada nuestra estructura, dentro de la función declararemos una variable del tipo de esta estructura. Luego, asignaremos el parámetro de entrada de la función a esta variable. Recuerde que los parámetros se pasan a las funciones de FreeRTOS como un puntero a nulo ( void * ) y es nuestra responsabilidad devolverlo al tipo original.
Tenga en cuenta también que le pasamos a la función un puntero a la variable original y no a la variable real, por lo que necesitamos usar el puntero para acceder al valor.
argsStruct myArgs = *((argsStruct*)parameters);Ahora, implementaremos la función de cálculo de potencia. Tenga en cuenta que podríamos haber usado la función Arduino pow , pero luego explicaré por qué no lo hicimos. Entonces, implementaremos la función con un ciclo donde multiplicaremos un valor por sí mismo n veces.
Comenzamos declarando una variable para contener el producto parcial. Luego, haremos un ciclo for para iterar todos los elementos de la matriz asignada a la tarea. Recuerda que este era nuestro objetivo inicial. Luego, para cada elemento, calcularemos su potencia y al final le asignaremos el valor a la matriz de resultados. Esto asegura que usaremos los mismos datos en todas nuestras pruebas y no cambiaremos la matriz original.
Para un código más limpio, podríamos haber implementado el algoritmo pow en una función dedicada, pero se intenta minimizar las llamadas a funciones auxiliares para un código más compacto.
Verifique el código a continuación. Dejo ahí comentada una línea de código para calcular la potencia usando la función pow , así que puedes probarlo si quieres. Tenga en cuenta que los resultados de aceleración serán considerablemente diferentes. Además, para acceder a un elemento de una variable de estructura, usamos el nombre de la variable punto («.») el nombre del elemento.
int product;
for (int i = myArgs.arrayStart; i < myArgs.arrayEnd; i++) {
product = 1;
for (int j = 0; j < myArgs.n; j++) {
product = product * bigArray[i];
}
resultArray[i]=product;
//resultArray [i] = pow(bigArray[i], myArgs.n);
}Compruebe el código de función completo a continuación. Tenga en cuenta que al final del código estamos aumentando el semáforo de conteo global en una unidad. Esto se hace para asegurar la sincronización con la función de configuración, ya que contaremos el tiempo de ejecución a partir de ahí. Además, al final, estamos eliminando la tarea.
void powerTask( void * parameters ) {
argsStruct myArgs = *((argsStruct*)parameters);
int product;
for (int i = myArgs.arrayStart; i < myArgs.arrayEnd; i++) {
product = 1;
for (int j = 0; j < myArgs.n; j++) {
product = product * bigArray[i];
}
resultArray[i]=product;
//resultArray [i] = pow(bigArray[i], myArgs.n);
}
xSemaphoreGive(barrierSemaphore);
vTaskDelete(NULL);
}
La función de configuración
Vamos a hacer todo el código restante en la función de configuración, por lo que nuestro ciclo principal estará vacío. Comenzaremos abriendo una conexión en serie para generar los resultados de nuestras pruebas.
Serial.begin(115200);
Serial.println();Ahora, inicializaremos nuestra matriz con algunos valores para aplicar el cálculo. Tenga en cuenta que no nos preocupa el contenido de la matriz ni el resultao real, sino los tiempos de ejecución. Entonces, vamos a inicializar la matriz con valores aleatorios solo para mostrar esas funciones, ya que no vamos a imprimir la matriz que contendrá los resultados.
Primero vamos a llamar a la función randomSeed , por lo que los valores aleatorios generados diferirán en diferentes ejecuciones del programa [4]. Si el pin analógico está desconectado, devolverá un valor correspondiente a ruido aleatorio, lo cual es ideal para pasar como entrada de la función randomSeed .
Después de eso, podemos simplemente llamar a la función aleatoria , pasando como argumentos los valores mínimo y máximo que se pueden devolver [4]. Nuevamente, estamos haciendo esto solo con fines ilustrativos, ya que no vamos a imprimir el contenido de las matrices.
randomSeed(analogRead(0));
for (int i = 0; i < 10000; i++) {
bigArray[i] = random(1, 10);
}Ahora, vamos a definir las variables que se utilizarán como argumentos para nuestras tareas. Recuerda la estructura declarada anteriormente, que contendrá los índices del arreglo que procesará cada tarea y el exponente.
Entonces, el primer elemento de la estructura es el índice inicial, el segundo es el índice final y el tercero es el exponente. Declararemos estructuras para cada caso de uso (una tarea, dos tareas y cuatro tareas) como se puede ver en el código a continuación. Tenga en cuenta que en el último elemento de la estructura estamos pasando un elemento de la matriz global que declaramos con los exponentes. Entonces, como veremos en el código final, iteraremos toda la matriz, pero por ahora mantengamos las cosas simples.
argsStruct oneTask = { 0 , 1000 , n[i] };
argsStruct twoTasks1 = { 0 , 1000 / 2 , n[i] };
argsStruct twoTasks2 = { 1000 / 2 , 1000 , n[i] };
argsStruct fourTasks1 = { 0 , 1000 / 4 , n[i] };
argsStruct fourTasks2 = { 1000 / 4 , 1000 / 4 * 2, n[i]};
argsStruct fourTasks3 = { 1000 / 4 * 2, 1000 / 4 * 3, n[i]};
argsStruct fourTasks4 = { 1000 / 4 * 3 , 1000, n[i]};Ahora, vamos a hacer la prueba usando una sola tarea. Empezamos por obtener el tiempo de ejecución con la función micros. Luego, usaremos la función xTaskCreatePinnedToCore para crear una tarea de FreeRTOS anclada a uno de los núcleos. Elegiremos el núcleo 1.
Vamos a pasar como parámetro la dirección de la variable de estructura oneTask , que contiene los argumentos necesarios para que se ejecute la función. No olvides el yeso al vacío* .
Una cosa muy importante a tener en cuenta es que aún no hemos analizado qué tareas pueden haber sido lanzadas por el núcleo de Arduino y que pueden influir en el tiempo de ejecución. Entonces, para garantizar que nuestra tarea se ejecutará con mayor prioridad, le asignaremos un valor de 20. Recuerde, los números más altos significan una mayor prioridad de ejecución para el programador de FreeRTOS.
Después de iniciar la tarea, solicitaremos una unidad del semáforo, asegurándonos de que la función de configuración se mantendrá hasta que la nueva tarea termine de ejecutarse. Finalmente, imprimiremos el tiempo de ejecución.
Serial.println("");
Serial.println("------One task-------");
start = micros();
xTaskCreatePinnedToCore(
powerTask, /* Function to implement the task */
"powerTask", /* Name of the task */
10000, /* Stack size in words */
(void*)&oneTask, /* Task input parameter */
20, /* Priority of the task */
NULL, /* Task handle. */
1); /* Core where the task should run */
xSemaphoreTake(barrierSemaphore, portMAX_DELAY);
end = micros();
execTimeOneTask = end - start;
Serial.print("Exec time: ");
Serial.println(execTimeOneTask);
Serial.print("Start: ");
Serial.println(start);
Serial.print("end: ");
Serial.println(end);Esto es más o menos lo que vamos a hacer para el resto de los casos de uso. La única diferencia es que vamos a lanzar más tareas y vamos a intentar sacar más unidades del semáforo (tantas como tareas lanzadas para ese caso de uso).
Consulte el código fuente completo a continuación, que ya incluye los casos de uso para ejecutar el código con dos tareas (una por núcleo ESP32) y cuatro tareas (dos por núcleo ESP32). Además, al final de la función de configuración, incluye la impresión de los resultados de aceleración para cada iteración.
Tenga en cuenta que el parámetro extra de la función Serial.println indica el número de lugares decimales para el número de punto flotante.
int n[10] = {2, 3, 4, 5, 10, 50, 100, 1000, 2000, 10000 };
int nArraySize = 10;
struct argsStruct {
int arrayStart;
int arrayEnd;
int n;
};
unsigned long start;
unsigned long end;
unsigned long execTimeOneTask, execTimeTwoTask, execTimeFourTask ;
SemaphoreHandle_t barrierSemaphore = xSemaphoreCreateCounting( 4, 0 );
int bigArray[10000], resultArray[10000];
void setup() {
Serial.begin(115200);
Serial.println();
randomSeed(analogRead(0));
for (int i = 0; i < 10000; i++) {
bigArray[i] = random(1, 10);
}
for (int i = 0; i < nArraySize; i++) {
Serial.println("#############################");
Serial.print("Starting test for n= ");
Serial.println(n[i]);
argsStruct oneTask = { 0 , 1000 , n[i] };
argsStruct twoTasks1 = { 0 , 1000 / 2 , n[i] };
argsStruct twoTasks2 = { 1000 / 2 , 1000 , n[i] };
argsStruct fourTasks1 = { 0 , 1000 / 4 , n[i] };
argsStruct fourTasks2 = { 1000 / 4 , 1000 / 4 * 2, n[i]};
argsStruct fourTasks3 = { 1000 / 4 * 2, 1000 / 4 * 3, n[i]};
argsStruct fourTasks4 = { 1000 / 4 * 3 , 1000, n[i]};
Serial.println("");
Serial.println("------One task-------");
start = micros();
xTaskCreatePinnedToCore(
powerTask, /* Function to implement the task */
"powerTask", /* Name of the task */
10000, /* Stack size in words */
(void*)&oneTask, /* Task input parameter */
20, /* Priority of the task */
NULL, /* Task handle. */
1); /* Core where the task should run */
xSemaphoreTake(barrierSemaphore, portMAX_DELAY);
end = micros();
execTimeOneTask = end - start;
Serial.print("Exec time: ");
Serial.println(execTimeOneTask);
Serial.print("Start: ");
Serial.println(start);
Serial.print("end: ");
Serial.println(end);
Serial.println("");
Serial.println("------Two tasks-------");
start = micros();
xTaskCreatePinnedToCore(
powerTask, /* Function to implement the task */
"powerTask", /* Name of the task */
10000, /* Stack size in words */
(void*)&twoTasks1, /* Task input parameter */
20, /* Priority of the task */
NULL, /* Task handle. */
0); /* Core where the task should run */
xTaskCreatePinnedToCore(
powerTask, /* Function to implement the task */
"coreTask", /* Name of the task */
10000, /* Stack size in words */
(void*)&twoTasks2, /* Task input parameter */
20, /* Priority of the task */
NULL, /* Task handle. */
1); /* Core where the task should run */
for (int i = 0; i < 2; i++) {
xSemaphoreTake(barrierSemaphore, portMAX_DELAY);
}
end = micros();
execTimeTwoTask = end - start;
Serial.print("Exec time: ");
Serial.println(execTimeTwoTask);
Serial.print("Start: ");
Serial.println(start);
Serial.print("end: ");
Serial.println(end);
Serial.println("");
Serial.println("------Four tasks-------");
start = micros();
xTaskCreatePinnedToCore(
powerTask, /* Function to implement the task */
"powerTask", /* Name of the task */
10000, /* Stack size in words */
(void*)&fourTasks1, /* Task input parameter */
20, /* Priority of the task */
NULL, /* Task handle. */
0); /* Core where the task should run */
xTaskCreatePinnedToCore(
powerTask, /* Function to implement the task */
"powerTask", /* Name of the task */
10000, /* Stack size in words */
(void*)&fourTasks2, /* Task input parameter */
20, /* Priority of the task */
NULL, /* Task handle. */
0); /* Core where the task should run */
xTaskCreatePinnedToCore(
powerTask, /* Function to implement the task */
"powerTask", /* Name of the task */
10000, /* Stack size in words */
(void*)&fourTasks3, /* Task input parameter */
20, /* Priority of the task */
NULL, /* Task handle. */
1); /* Core where the task should run */
xTaskCreatePinnedToCore(
powerTask, /* Function to implement the task */
"powerTask", /* Name of the task */
10000, /* Stack size in words */
(void*)&fourTasks4, /* Task input parameter */
20, /* Priority of the task */
NULL, /* Task handle. */
1); /* Core where the task should run */
for (int i = 0; i < 4; i++) {
xSemaphoreTake(barrierSemaphore, portMAX_DELAY);
}
end = micros();
execTimeFourTask = end - start;
Serial.print("Exec time: ");
Serial.println(execTimeFourTask);
Serial.print("Start: ");
Serial.println(start);
Serial.print("end: ");
Serial.println(end);
Serial.println();
Serial.println("------Results-------");
Serial.print("Speedup two tasks: ");
Serial.println((float) execTimeOneTask / execTimeTwoTask, 4 );
Serial.print("Speedup four tasks: ");
Serial.println((float)execTimeOneTask / execTimeFourTask, 4 );
Serial.print("Speedup four tasks vs two tasks: ");
Serial.println((float)execTimeTwoTask / execTimeFourTask, 4 );
Serial.println("#############################");
Serial.println();
}
}
void loop() {
}
void powerTask( void * parameters ) {
argsStruct myArgs = *((argsStruct*)parameters);
int product;
for (int i = myArgs.arrayStart; i < myArgs.arrayEnd; i++) {
product = 1;
for (int j = 0; j < myArgs.n; j++) {
product = product * bigArray[i];
}
resultArray[i]=product;
//resultArray [i] = pow(bigArray[i], myArgs.n);
}
xSemaphoreGive(barrierSemaphore);
vTaskDelete(NULL);
}
Probando el código
Para probar el código, simplemente cárguelo con el IDE de Arduino y abra el monitor serie. Debería obtener un resultado similar a la figura 1. Naturalmente, los tiempos de ejecución pueden variar.

Figura 1 : Salida del programa de prueba de aceleración.
Los resultados para cada exponente se muestran en la siguiente tabla, en la tabla 1.
| Exponente | 1 tarea [µs] | 2 tareas [µs] | 4 tareas [µs] | Acelerar 1 tarea frente a 2 tareas | Acelerar 1 tarea frente a 4 tareas | Acelerar 2 tareas vs 4 tareas |
| 2 | 229 | 183 | 296 | 1.2514 | 0.7736 | 0.6182 |
| 3 | 271 | 207 | 325 | 1.3092 | 0.8338 | 0.6369 |
| 4 | 312 | 224 | 340 | 1.3929 | 0.9176 | 0.6588 |
| 5 | 354 | 249 | 367 | 1.4217 | 0.9646 | 0.6785 |
| 10 | 556 | 347 | 451 | 1.6023 | 1.2328 | 0.7694 |
| 50 | 2235 | 1188 | 1305 | 1.8813 | 1.7126 | 0.9103 |
| 100 | 4331 | 2234 | 2343 | 1.9387 | 1.8485 | 0.9535 |
| 1000 | 42072 | 21108 | 21212 | 1.9932 | 1.9834 | 0.9951 |
| 2000 | 83992 | 42138 | 42190 | 1.9933 | 1.9908 | 0.9988 |
| 10000 | 419400 | 210283 | 210310 | 1.9945 | 1.9942 | 0.9999 |
Tabla 1 – Resultados de aceleración para los exponentes definidos en el código.
Analizando los resultados
Para comprender los resultados, primero debemos tener en cuenta que no se puede paralelizar completamente todo el programa. Entonces, siempre habrá partes del código que se ejecuten en un solo núcleo, como el lanzamiento de las tareas o los mecanismos de sincronización.
Aunque no teníamos este caso de uso, muchos algoritmos de paralelización también tienen una parte en la que cada resultado parcial se agrega secuencialmente (por ejemplo, si tenemos varias tareas calculando el valor máximo de su parte de la matriz y luego la tarea principal calcula el valor máximo entre todos los resultados parciales).
Entonces, hagamos lo que hagamos, teóricamente no podemos lograr una aceleración igual a la cantidad de núcleos (hay algunas excepciones en, por ejemplo, algoritmos que buscan un valor específico y salen cuando lo encuentran, pero no nos compliquemos).
Entonces, mientras más cómputos ejecutemos en paralelo versus la porción que ejecutamos en secuencia, más aceleración tendremos. Y eso es precisamente lo que vemos en nuestros resultados. Si comenzamos con un exponente de 2 , nuestra aceleración de la ejecución de una tarea a dos tareas es solo de 1.2514 .
Pero a medida que aumentamos el valor del exponente, hacemos más iteraciones del ciclo más interno y, por lo tanto, más cálculos podemos realizar en paralelo. Así, a medida que aumentamos el exponente, vemos un aumento de la aceleración. Por ejemplo, con un exponente de 1000 , nuestra aceleración es 1.9933 . Lo cual es un valor muy alto en comparación con el anterior.
Entonces, esto significa que la parte secuencial se diluye y para grandes exponentes la paralelización compensa. Tenga en cuenta que podemos lograr este tipo de valores altos porque el algoritmo es muy simple y fácil de paralelizar. Además, debido a la forma en que FreeRTOS maneja las prioridades y los cambios de contexto de ejecución de tareas, no hay mucha sobrecarga después de que se ejecutan las tareas. Una computadora normal tiende a tener más cambios de contexto entre subprocesos y, por lo tanto, la sobrecarga secuencial es mayor.
Tenga en cuenta que no usamos la función pow para mostrar esta progresión en los valores de aceleración. La función pow usa flotantes, lo que significa que su implementación es más intensiva en computación. Entonces, obtendríamos aceleraciones mucho mejores en exponentes más bajos porque la parte paralela sería mucho más relevante que la secuencial. Puede comentar nuestro algoritmo implementado y usar la función pow para comparar los resultados.
Además, es importante tener en cuenta que lanzar más tareas que la cantidad de núcleos no aumenta la velocidad. De hecho, tiene el efecto contrario. Como podemos ver en los resultados, la aceleración de ejecutar con 4 tareas siempre es menor que la de ejecutar con 2 tareas. De hecho, para exponentes bajos, en realidad es más lento ejecutar el código con 4 tareas (aunque estén divididas entre los dos núcleos del ESP32) que ejecutar con una tarea en un solo núcleo.
Esto es normal porque cada CPU solo puede ejecutar una tarea en un momento dado y, por lo tanto, lanzar más tareas que CPU significa más tiempo secuencial para manejarlas y más sobrecarga en los puntos de sincronización.
Sin embargo, tenga en cuenta que esto no siempre es blanco y negro. Si las tareas tuvieran algún tipo de punto de rendimiento en el que dejarían de esperar algo, entonces tener más tareas que núcleos podría ser beneficioso para usar los ciclos de CPU libres. Sin embargo, en nuestro caso, las CPU nunca rinden y siempre se están ejecutando, por lo que no hay ningún beneficio en lanzar más de 2 tareas, en cuanto a la aceleración.
La ley de Amdhal
Para complementar los resultados, veremos la ley de Amdahl . Entonces, vamos a aplicar algunas transformaciones a la fórmula de aceleración que estábamos usando. La fórmula inicial era que la aceleración es igual al tiempo de ejecución secuencial (lo llamaremos T ) dividido por el tiempo de ejecución en paralelo (lo llamaremos T Paralelo ).

Pero, como vimos, hay una parte del tiempo de ejecución que siempre es secuencial y otra que puede ser paralelizada. Llamemos p a la fracción del programa que podemos ejecutar en paralelo. Como es una fracción, su valor estará entre 0 y 1.
Entonces, podemos representar el tiempo de ejecución secuencial T como la porción que puede ejecutarse en paralelo ( p*T ) más la porción que no puede (1-p)*T .

Como solo podemos dividir la parte paralela entre los núcleos de nuestra máquina, el tiempo T Parallel es similar a la fórmula anterior, excepto que la parte paralela aparece dividida por la cantidad de núcleos que tenemos disponibles.
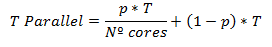
Entonces, nuestra fórmula de aceleración se convierte en:

Ahora tenemos la aceleración escrita en función de T , el tiempo de ejecución original sin mejoras. Entonces, podemos dividir cada término por T :

Entonces, ahora tenemos la aceleración escrita en función de la parte que puede ejecutarse en paralelo y la cantidad de núcleos. Para terminar, supongamos que tenemos una cantidad infinita de núcleos disponibles para ejecutar (el caso de uso real sería un número muy grande, pero analizaremos matemáticamente la fórmula).

Como una constante dividida por infinito es igual a 0, terminamos con:

Así que, aunque la aceleración aumenta con la cantidad de recursos disponibles para la paralelización (la cantidad de núcleos, en nuestro caso), lo cierto es que la máxima aceleración teórica posible está limitada por la parte no paralela, que no podemos optimizar.
Esta es una conclusión interesante para que decidamos si vamos o no a la paralelización. Algunas veces, los algoritmos pueden paralelizarse fácilmente y tenemos una tremenda aceleración, otras el esfuerzo necesario no justifica la ganancia.
Además, otra cosa importante a tener en cuenta es que el mejor algoritmo secuencial no siempre es el mejor después de la paralelización. Entonces, a veces, es mejor usar un algoritmo que tiene menos rendimiento en la ejecución secuencial, pero termina siendo mucho mejor que el mejor secuencial en la paralelización.
Resumen
Con este post, confirmamos que las funciones disponibles para la ejecución multinúcleo funcionan bien y podemos aprovecharlas para obtener beneficios de rendimiento.
La última parte más teórica tenía el objetivo de mostrar que la paralelización no es un tema trivial, y uno no puede saltar directamente a un enfoque paralelo sin un análisis previo y esperar una aceleración igual a la cantidad de núcleos disponibles. Este razonamiento se extiende más allá del alcance del ESP32 y se aplica a la computación paralela en general.
Entonces, para aquellos que van a comenzar con la computación paralela utilizando el ESP32 para mejorar el rendimiento, es un buen comienzo para aprender primero algunos de los conceptos más teóricos.
Finalmente, tenga en cuenta que el código está orientado a mostrar los resultados, por lo que se podrían haber hecho muchas optimizaciones, como lanzar las tareas en un ciclo en lugar de repetir el código o condensar el algoritmo en una función.
Además, no buscábamos los resultados de la ejecución para confirmar que la matriz de salida era la misma porque ese no era nuestro enfoque principal. Naturalmente, pasar de secuencial a paralelo requiere una implementación cuidadosa del código y la ejecución de muchas pruebas para garantizar que el resultado sea el mismo.
Mas información en
[1] https://espressif.com/en/products/hardware/esp32/overview
[2] http://www.dcc.fc.up.pt/~fds/aulas/PPD/1112/metrics_en.pdf
[3] https://www.arduino.cc/en/reference/micros
[4] https://www.arduino.cc/en/reference/random
[5] https://techtutorialsx.com/2017/05/16/esp32-dual-core-execution-speedup/

Deja un comentario