Recientemente ha salido a la luz Roni Bandini, el programador, músico y escritor argentino de 49 años, que ha creado el ingenioso dispositivo Reggaeton Be Gone, diseñado para contrarrestar la música molesta de reguetón que reproduce el altavoz bluetooth de su vecino.
Utilizando inteligencia artificial y componentes de bajo costo, este dispositivo identifica y bloquea la música de reguetón enviada a través de altavoces bluetooth, generando interferencias que obligan al vecino a cambiar de ubicación (! o al menos esa era la idea hasta que su vecino cambió la ubicación de dicho altavoz!). Aunque reconocido localmente como un «héroe» por su invento, Bandini se muestra reticente a comercializarlo masivamente, prefiriendo compartir su conocimiento en talleres de contracultura maker pues además de este dispositivo, Bandini ha incursionado en la creación de otras máquinas innovadoras que fusionan literatura, tecnología y arte, como Rayuelomatic, BookSound y la expendedora de Literatura en Tickets.
El Reggaeton Be Gone utiliza inteligencia artificial, específicamente machine learning, para reconocer patrones sonoros y distinguir miles de canciones del género de reguetón. Su proyecto compuesto por componentes de bajo costo, como puede ser una raspberry pi , un receptor Bluetooth , un pulsador y una pequeña panta I2C, así como software de código abierto, monitorea la música que se está reproduciendo y la compara con un modelo previamente entrenado: si determina que la canción que esta «oyendo» es identificada como reguetón, intenta interferir con la señal enviada al altavoz bluetooth, con el objetivo de desconectar el altavoz o al menos dificultar la escucha para no ser molestado.
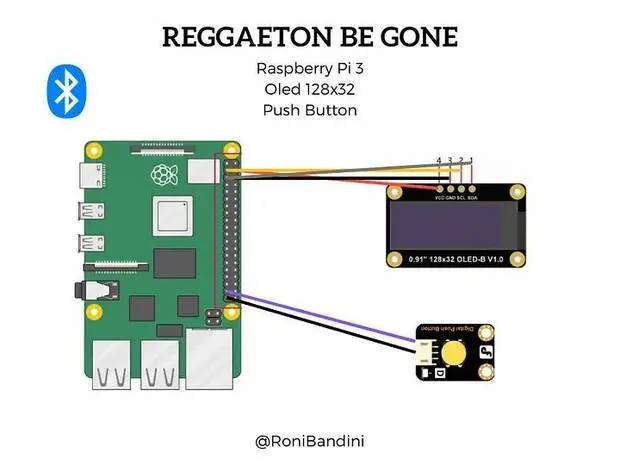
Al margen de que la idea nos pueda ser útil, sin duda al menos el concepto es claramente interesante porque nos acerca actual de como con un maquina tan limitada como puede ser un ESP32 o una Raspberry Pi (o incluso un smartphone antiguo), podemos ejecutar algoritmos de Deep Learning para cualquier cosa que se nos ocurra.
¿Como es posible ejecutar un algoritmo de IA en una maquina tan limitada?
Pues bien la clave está en Edge Impulse, una plataforma de desarrollo de aprendizaje automático (machine learning) y análisis de datos diseñada específicamente para dispositivos de «borde» o «edge» (como microcontroladores, dispositivos IoT, sensores, etc.), lo que se conoce como «TinyML«. Simplifica el proceso al permitir ingresar una base de datos, ajustar parámetros y entrenar el programa con diversos casos de implementación, lo cual elimina la necesidad de sumergirse profundamente en el desarrollo del código. La plataforma ofrece la posibilidad de realizar proyectos de detección de objetos, reconocimiento de voz, procesamiento de gestos de un acelerómetro, y más.
La plataforma permite a los desarrolladores recopilar datos de sensores, entrenar modelos de aprendizaje automático y desplegar estos modelos directamente en dispositivos de borde simplificando el desarrollo de aplicaciones de Machine Learning para dispositivos embebidos, ampliando las posibilidades de implementación en diversos campos.

Por cierto, Edge Impulse es una plataforma joven, pero grandes fabricantes de semiconductores respaldan su desarrollo. Por mencionar algunos están ARM, ST Electronics, Microchip, Nordic Semiconductor y Arduino. Podemos destacar sobre todo la colaboración con TinyML y Hackster.io. Con estos se implementan los algoritmos de aprendizaje máquina y se documentan los proyectos que se van desarrollando.
Implementación de algoritmos en minutos
Edge Impulse ofrece una plataforma intuitiva para implementar algoritmos de machine learning en cuestión de minutos, sin necesidad de ser un experto en la materia. La interfaz es muy amigable y es bastante intuitiva. Según la página oficial se puede implementar su proyecto en minutos (dejando de lado la etapa de aprendizaje).
¿Cómo funciona?
- Cree su cuenta: Regístrese en la plataforma Impulse y seleccione el tipo de proyecto que desea realizar :
- Detección de objetos
- Reconocimiento de voz ( que es el tipo de proyecto que ha usado Roni Bandini)
- Procesamiento de gestos
- Etc..
- Adquiera datos: Reúna o genere el conjunto de datos (dataset) que su proyecto necesita. En el caso de Roni Bandino por ejemplo han sido varios fragmentos de canciones. La plataforma le ofrece diversas opciones para obtener datos, como la carga de archivos CSV o la conexión a sensores en tiempo real.
- Cree un Impulse: Defina los parámetros de su modelo de machine learning y entrene el modelo con tu dataset utilizando la herramienta Impulse. La plataforma le guía a través del proceso con una interfaz amigable.
- Cargue el modelo: Descargue el modelo entrenado y cárguelo en su microcontrolador. Impulse le ofrece opciones para diferentes plataformas de hardware.
Ventajas:
- Interfaz intuitiva: Fácil de usar, incluso para principiantes en machine learning.
- Rápido y eficiente: Implementa algoritmos en minutos, sin necesidad de conocimientos avanzados de programación.
- Versátil: Soporta diferentes tipos de proyectos de machine learning.
- Flexible: Compatible con diversos microcontroladores y plataformas de hardware.
Ejemplos de proyectos:
- Detección de objetos en imágenes
- Reconocimiento de voz para control por voz
- Clasificación de gestos con un acelerómetro
- Análisis de datos de sensores en tiempo real
Impulse democratiza el acceso a la inteligencia artificial, permitiendo que cualquier persona pueda implementar algoritmos sofisticados en sus proyectos.
Otro ejemplo: clasificación de Movimientos con Edge Impulse con un Smartphone
Este tipo de proyectos explora la capacidad de Edge Impulse para tomar datos de sensores de movimiento en un smartphone y crear un modelo de machine learning
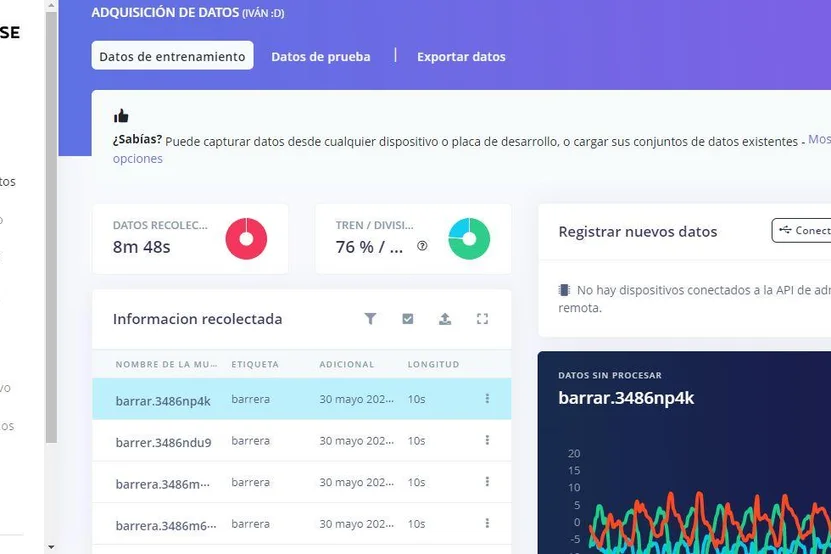
Concretaemente el proyecto que podemos ver en instructables se llevó a cabo utilizando la aplicación Edge Impulse en un smartphone, recopilando 50 rondas de 10 segundos para cada movimiento para clasificar tres movimientos cotidianos: sentadillas, peinarse y barrer.
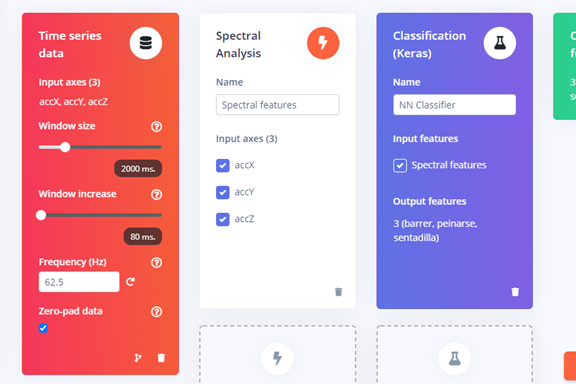
Los datos se sincronizaron con la plataforma Edge Impulse para procesarlos, extraer características y entrenar un modelo de clasificación utilizando la función «Impulse Design«.
Se ajustaron los parámetros del modelo y se verificó su precisión en la sección «Model«. Luego, se probó el modelo en tiempo real seleccionando la opción «Switch to classification mode» en el smartphone, logrando una precisión del 100% en la clasificación de los movimientos. Los resultados demostraron la capacidad del modelo para identificar movimientos en vivo.
Destaca la sensibilidad del modelo a la posición del dispositivo durante las pruebas y pero el autor recomienda acciones para mejorar la robustez del modelo, experimentar con diferentes movimientos y considerar la implementación en una aplicación móvil para una interacción más intuitiva.
Con este sencillo proyecto vemos la utilidad de la plataforma para la creación de modelos de machine learning con smartphones.
Gran compatibilidad
Con Edge Impulse, los usuarios pueden capturar datos de sensores, etiquetarlos, entrenar modelos de aprendizaje automático utilizando técnicas como la visión por computadora, el procesamiento de señales y el análisis de audio, y luego implementar estos modelos en hardware de baja potencia. Esto permite la ejecución de inferencias
A medida que aumenta la popularidad de Edge Impulse se van agregando más tarjetas de desarrollo a la lista de sistemas compatibles. Esto permite que se pueda cargar fácilmente su modelo a tu plataforma final. Ya sea un móvil, una Raspberry Pi, un Arduino 33 BLE Sense o una OpenMV, podrá cargar su modelo. La lista es bastante extensa y si la pagina no tiene soporte nativo aún, puede convertir su modelo en una librería de C++ o Java. Esto le permitirá integrarlo a cualquier plataforma que desees, siempre que tenga la capacidad adecuada de procesamiento.
Referencias:
- Edge Impulse
- Blog Edge Impulse
- Visite la página oficial de Impulse: https://byjus.com/jee/impulse/



Debe estar conectado para enviar un comentario.