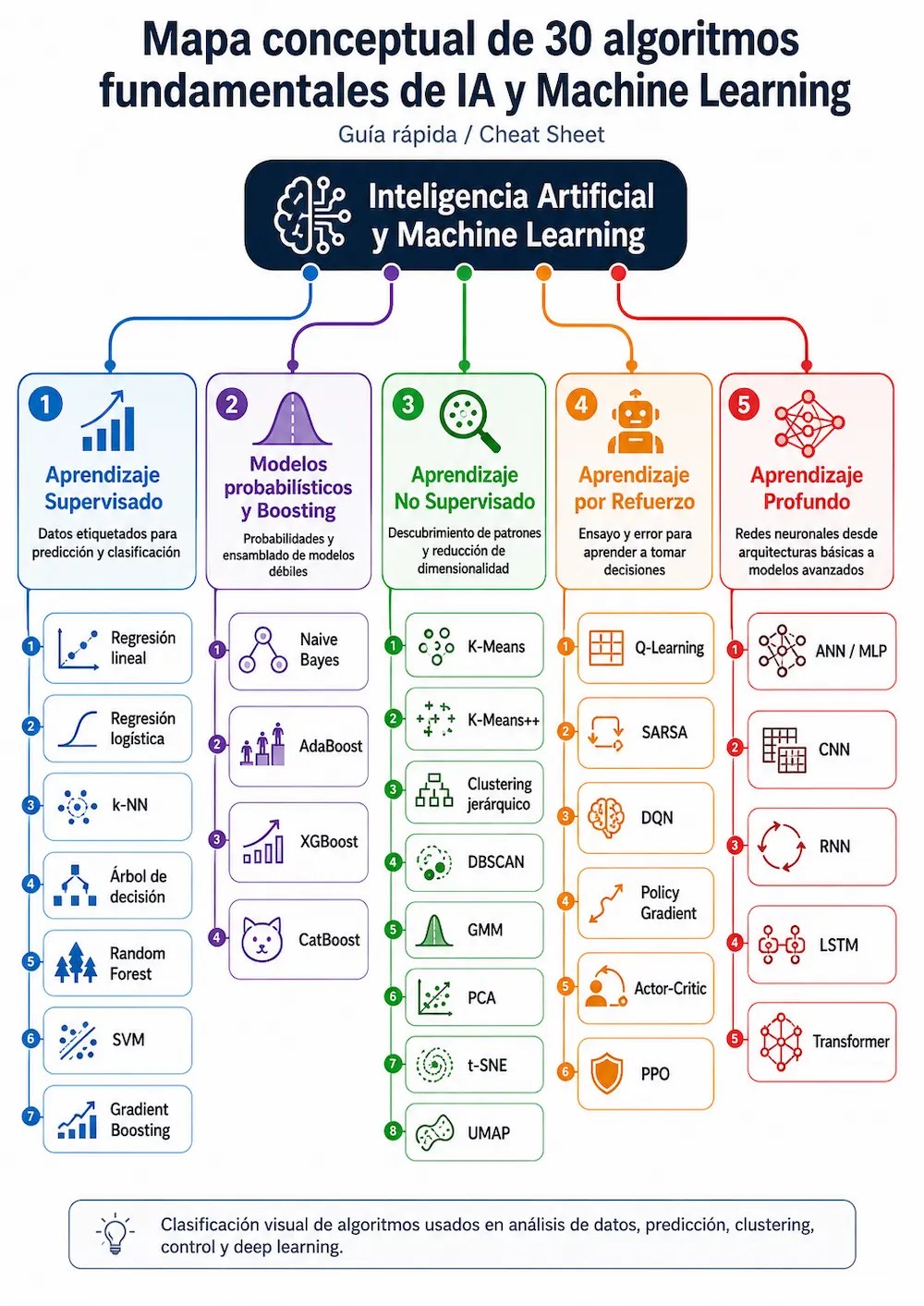
La Inteligencia Artificial —IA— y el Machine Learning —Aprendizaje Automático— ya no son conceptos reservados a laboratorios de investigación o grandes empresas tecnológicas. Hoy están detrás de muchas herramientas cotidianas: recomendaciones de películas, filtros antispam, asistentes virtuales, diagnósticos médicos, detección de fraude, traducción automática, generación de imágenes y modelos de lenguaje como los que usamos para conversar con una IA.
Pero detrás de todas estas aplicaciones hay una pregunta clave:
¿Qué algoritmo se utiliza para resolver cada tipo de problema?
El mapa conceptual anterior intenta responder precisamente a eso. Su objetivo es mostrar, de forma visual y sencilla, cómo se organizan algunos de los algoritmos más importantes de Inteligencia Artificial, Machine Learning y Deep Learning.
No se trata solo de memorizar nombres como Random Forest, K-Means, XGBoost o Transformer. Lo realmente importante es entender qué problema resuelve cada algoritmo, qué tipo de datos necesita y en qué situaciones puede aplicarse.
A continuación, repasamos las principales familias de algoritmos de IA y Machine Learning, acompañadas de ejemplos prácticos para entender mejor su utilidad.
1. Aprendizaje supervisado: aprender a partir de ejemplos conocidos
El aprendizaje supervisado se utiliza cuando disponemos de datos etiquetados. Es decir, tenemos ejemplos históricos en los que ya conocemos la respuesta correcta.
Por ejemplo, si queremos predecir el precio de una vivienda, necesitamos datos anteriores de casas con sus características y su precio real. Si queremos detectar correos spam, necesitamos mensajes previamente clasificados como spam o no spam.
Este tipo de aprendizaje se usa principalmente en dos tareas:
Regresión, cuando queremos predecir un valor numérico.
Clasificación, cuando queremos asignar una categoría.
Regresión lineal
La regresión lineal es uno de los algoritmos más sencillos y conocidos. Sirve para predecir valores continuos a partir de una o varias variables.
Ejemplo práctico: calcular el precio aproximado de una vivienda según sus metros cuadrados, ubicación, número de habitaciones y antigüedad.
También puede utilizarse para estimar ventas futuras, consumo energético o ingresos esperados.
Regresión logística
Aunque su nombre incluye la palabra “regresión”, la regresión logística se utiliza normalmente para clasificación.
Ejemplo práctico: predecir si un cliente cancelará o no una suscripción. El modelo puede analizar datos como tiempo de uso, incidencias, pagos anteriores o interacción con la plataforma.
El resultado suele expresarse como una probabilidad: por ejemplo, “este cliente tiene un 78 % de probabilidad de abandonar el servicio”.
k-NN —k-Nearest Neighbors—
El algoritmo k-NN clasifica un nuevo dato observando cuáles son sus vecinos más cercanos dentro del conjunto de datos.
Ejemplo práctico: clasificar una flor según sus características físicas, como longitud y anchura de pétalos y sépalos.
También puede aplicarse en sistemas de recomendación sencillos: si dos usuarios tienen gustos parecidos, probablemente puedan recibir recomendaciones similares.
Árbol de decisión
Un árbol de decisión funciona como una secuencia de preguntas. Cada respuesta nos lleva por una rama distinta hasta llegar a una predicción.
Ejemplo práctico: decidir si una solicitud de préstamo debe aprobarse o rechazarse según ingresos, historial crediticio, edad, estabilidad laboral y nivel de deuda.
Su principal ventaja es que resulta fácil de interpretar, ya que podemos seguir el camino lógico que llevó a una decisión.
Random Forest
Random Forest combina muchos árboles de decisión para obtener una predicción más robusta.
Ejemplo práctico: detectar operaciones bancarias fraudulentas analizando importe, ubicación, dispositivo utilizado, hora de la transacción y comportamiento habitual del cliente.
Al usar varios árboles, el modelo reduce el riesgo de depender de una única estructura de decisión.
SVM —Support Vector Machines—
Las máquinas de vectores de soporte buscan la mejor frontera posible para separar diferentes clases de datos.
Ejemplo práctico: clasificar correos electrónicos como spam o no spam a partir de palabras clave, remitente, enlaces incluidos y estructura del mensaje.
SVM también se ha utilizado mucho en clasificación de imágenes, reconocimiento de patrones y problemas donde las clases están bien separadas.
Gradient Boosting
Gradient Boosting construye modelos de manera secuencial. Cada nuevo modelo intenta corregir los errores cometidos por los anteriores.
Ejemplo práctico: predecir la probabilidad de que un usuario haga clic en un anuncio online teniendo en cuenta su historial de navegación, dispositivo, ubicación y comportamiento previo.
Es una técnica muy utilizada cuando se busca alta precisión en problemas predictivos.
2. Modelos probabilísticos y boosting: cuando la probabilidad y la combinación de modelos importan
Algunos algoritmos se basan en probabilidades. Otros combinan muchos modelos simples para construir un sistema más potente. Este grupo es especialmente útil en clasificación, análisis de texto, predicción de riesgo y problemas de datos tabulares.
Naive Bayes
Naive Bayes utiliza probabilidades para decidir a qué categoría pertenece un dato.
Ejemplo práctico: analizar comentarios de clientes y clasificarlos como positivos, negativos o neutros.
También es muy habitual en filtros antispam. El algoritmo calcula la probabilidad de que un correo sea spam según las palabras que contiene.
AdaBoost
AdaBoost combina varios modelos simples, llamados modelos débiles, para crear un modelo más preciso.
Ejemplo práctico: detectar rostros en imágenes combinando pequeños clasificadores especializados en identificar ojos, nariz, boca o contornos faciales.
Su lógica es sencilla: presta más atención a los casos que los modelos anteriores clasificaron mal.
XGBoost
XGBoost es uno de los algoritmos de boosting más populares por su rendimiento, velocidad y precisión.
Ejemplo práctico: estimar el riesgo de impago de un cliente en una entidad financiera usando información sobre ingresos, deuda, historial de pagos, tipo de contrato y comportamiento crediticio.
Es muy usado en ciencia de datos, especialmente cuando se trabaja con datos estructurados en tablas.
CatBoost
CatBoost es otro algoritmo de boosting, especialmente eficaz cuando existen muchas variables categóricas, como ciudad, tipo de producto, canal de venta o segmento de cliente.
Ejemplo práctico: predecir si un usuario comprará en una tienda online según la categoría del producto, el dispositivo utilizado, la fuente de tráfico y su historial de compras.
Su gran ventaja es que maneja muy bien datos no numéricos sin requerir tanta preparación previa.
3. Aprendizaje no supervisado: descubrir patrones ocultos
El aprendizaje no supervisado se utiliza cuando los datos no tienen etiquetas. En lugar de aprender a partir de respuestas conocidas, estos algoritmos intentan descubrir estructuras, grupos o relaciones dentro de los datos.
Es muy útil cuando no sabemos exactamente qué buscamos, pero queremos explorar la información.
K-Means
K-Means agrupa datos en un número determinado de clusters o grupos.
Ejemplo práctico: segmentar clientes de una tienda según frecuencia de compra, gasto medio y categorías favoritas.
Así, una empresa puede descubrir grupos como clientes ocasionales, compradores frecuentes, usuarios sensibles al precio o clientes premium.
K-Means++
K-Means++ mejora K-Means seleccionando de forma más inteligente los puntos iniciales de los grupos.
Ejemplo práctico: agrupar usuarios de una aplicación móvil según su comportamiento: usuarios activos, usuarios en riesgo de abandono, usuarios nuevos o usuarios intensivos.
La mejora está en que los grupos suelen ser más estables y representativos que con K-Means tradicional.
Clustering jerárquico
El clustering jerárquico crea una estructura en forma de árbol que muestra cómo se relacionan los datos en distintos niveles.
Ejemplo práctico: clasificar especies animales según similitudes genéticas, físicas o de comportamiento.
También puede utilizarse para organizar documentos, productos o perfiles de clientes en grupos y subgrupos.
DBSCAN
DBSCAN agrupa puntos según su densidad y permite detectar valores atípicos o ruido.
Ejemplo práctico: identificar zonas con alta concentración de taxis en una ciudad y detectar trayectos anómalos.
Es especialmente útil cuando los grupos tienen formas irregulares o cuando existen datos extraños que no encajan en ningún grupo.
GMM —Gaussian Mixture Models—
Los modelos de mezcla gaussiana agrupan datos suponiendo que proceden de varias distribuciones estadísticas.
Ejemplo práctico: segmentar clientes cuando los grupos no están claramente separados, sino que se solapan parcialmente.
A diferencia de otros métodos más rígidos, GMM puede asignar probabilidades de pertenencia a cada grupo.
PCA —Análisis de Componentes Principales—
PCA reduce el número de variables de un conjunto de datos conservando la mayor cantidad posible de información.
Ejemplo práctico: analizar datos de sensores industriales reduciendo cientos de señales a unas pocas variables principales para detectar fallos o anomalías.
También se utiliza para visualizar datos complejos y eliminar redundancia.
t-SNE
t-SNE sirve para visualizar datos complejos en dos o tres dimensiones, manteniendo relaciones locales entre puntos.
Ejemplo práctico: representar documentos de texto agrupados por temática después de convertirlos en vectores numéricos.
Es muy útil para explorar visualmente datos de alta dimensionalidad.
UMAP
UMAP es una técnica moderna de reducción de dimensionalidad, rápida y eficaz para grandes conjuntos de datos.
Ejemplo práctico: visualizar perfiles genéticos de pacientes para identificar subgrupos con características biológicas similares.
También se usa en análisis de imágenes, texto, biomedicina y exploración de embeddings generados por modelos de IA.
4. Aprendizaje por refuerzo: aprender mediante ensayo y error
El aprendizaje por refuerzo —Reinforcement Learning— se basa en una idea muy intuitiva: un agente aprende interactuando con un entorno.
Si toma una buena decisión, recibe una recompensa. Si toma una mala decisión, recibe una penalización. Con el tiempo, aprende qué acciones le permiten obtener mejores resultados.
Este enfoque se utiliza en robótica, videojuegos, simuladores, vehículos autónomos, optimización de rutas y sistemas de control.
Q-Learning
Q-Learning aprende qué acción conviene tomar en cada situación para maximizar la recompensa futura.
Ejemplo práctico: enseñar a un robot a encontrar la ruta más corta dentro de un almacén evitando obstáculos.
El algoritmo va aprendiendo qué caminos son mejores a medida que prueba diferentes acciones.
SARSA
SARSA es parecido a Q-Learning, pero aprende teniendo en cuenta la acción real que el agente ejecuta durante el entrenamiento.
Ejemplo práctico: entrenar a un agente virtual para moverse por un entorno con zonas seguras y zonas peligrosas.
Su comportamiento suele ser más prudente, porque aprende directamente de la política que está siguiendo.
DQN —Deep Q-Network—
DQN combina Q-Learning con redes neuronales profundas, lo que permite trabajar con entornos mucho más complejos.
Ejemplo práctico: entrenar una IA para jugar videojuegos aprendiendo directamente desde los píxeles de la pantalla.
Este enfoque marcó un avance importante en el uso de deep learning dentro del aprendizaje por refuerzo.
Policy Gradient
Los métodos Policy Gradient aprenden directamente una política de acciones, en lugar de calcular primero el valor de cada acción.
Ejemplo práctico: controlar un brazo robótico para agarrar objetos con precisión.
Son especialmente útiles cuando las acciones son continuas, como mover una articulación, ajustar velocidad o controlar dirección.
Actor-Critic
El enfoque Actor-Critic combina dos componentes: el actor, que decide qué acción tomar, y el crítico, que evalúa si esa acción fue buena o mala.
Ejemplo práctico: optimizar la conducción de un vehículo autónomo ajustando aceleración, frenado y dirección.
Esta combinación permite aprender de forma más estable y eficiente.
PPO —Proximal Policy Optimization—
PPO es un algoritmo moderno de aprendizaje por refuerzo diseñado para mejorar la estabilidad del entrenamiento.
Ejemplo práctico: entrenar agentes virtuales en simuladores 3D para caminar, correr, saltar o interactuar con objetos.
Es popular porque ofrece buenos resultados sin ser tan inestable como otros métodos avanzados.
5. Aprendizaje profundo: redes neuronales para problemas complejos
El aprendizaje profundo —Deep Learning— utiliza redes neuronales con múltiples capas para aprender representaciones complejas de los datos.
Es la base de muchos avances actuales en visión por ordenador, procesamiento del lenguaje natural, reconocimiento de voz, generación de imágenes, traducción automática y modelos de lenguaje.
ANN / MLP —Red neuronal artificial—
Una ANN o MLP es una red neuronal básica formada por capas de neuronas conectadas entre sí.
Ejemplo práctico: predecir si un cliente contratará un producto financiero a partir de edad, ingresos, historial, intereses y comportamiento previo.
Aunque es una arquitectura sencilla, sirve como base para comprender redes neuronales más avanzadas.
CNN —Convolutional Neural Networks—
Las CNN están diseñadas para procesar imágenes. Detectan patrones visuales como bordes, texturas, formas y objetos.
Ejemplo práctico: identificar tumores en imágenes médicas, clasificar fotografías de productos o reconocer señales de tráfico.
Son fundamentales en visión por ordenador.
RNN —Recurrent Neural Networks—
Las RNN procesan datos secuenciales, teniendo en cuenta información anterior dentro de una serie.
Ejemplo práctico: analizar series temporales de ventas o predecir la siguiente palabra en una frase.
Fueron muy importantes en tareas de lenguaje y señales antes de la llegada masiva de los Transformers.
LSTM —Long Short-Term Memory—
Las LSTM son una evolución de las RNN. Están diseñadas para recordar información durante periodos más largos.
Ejemplo práctico: detectar anomalías en sensores industriales o analizar el sentimiento de una reseña extensa.
Su capacidad de memoria las hace útiles en problemas donde el contexto importa.
Transformer
Los Transformers utilizan mecanismos de atención para procesar información de forma contextual y eficiente.
Ejemplo práctico: crear modelos de lenguaje capaces de resumir textos, traducir idiomas, responder preguntas, generar contenido o analizar documentos complejos.
Esta arquitectura está detrás de muchos de los avances recientes en IA generativa y grandes modelos de lenguaje.
¿Cómo elegir el algoritmo adecuado?
No existe un algoritmo perfecto para todos los casos. La elección depende del problema, del tipo de datos y del objetivo final.
Como orientación general:
- Para predecir valores numéricos, pueden usarse modelos como regresión lineal, Random Forest, Gradient Boosting o XGBoost.
- Para clasificar datos, son habituales la regresión logística, SVM, árboles de decisión, Naive Bayes o redes neuronales.
- Para agrupar datos sin etiquetas, se utilizan K-Means, DBSCAN, clustering jerárquico o GMM.
- Para reducir dimensiones y visualizar datos complejos, destacan PCA, t-SNE y UMAP.
- Para tomar decisiones mediante ensayo y error, entran en juego Q-Learning, SARSA, DQN, PPO y otros métodos de aprendizaje por refuerzo.
- Para trabajar con imágenes, texto, audio o modelos generativos, las arquitecturas de deep learning como CNN, LSTM y Transformer son especialmente relevantes.
Conclusión
Los algoritmos de Inteligencia Artificial y Machine Learning forman la base de muchos sistemas digitales actuales: motores de recomendación, asistentes virtuales, filtros antispam, sistemas de detección de fraude, diagnóstico médico, análisis de imágenes, chatbots, vehículos autónomos y modelos generativos.
En este artículo hemos hecho una introducción práctica a 30 algoritmos fundamentales de IA y Machine Learning, organizados en seis grandes áreas: aprendizaje supervisado, modelos probabilísticos, boosting, aprendizaje no supervisado, aprendizaje por refuerzo y aprendizaje profundo.
El objetivo no es convertir esta guía en una explicación matemática exhaustiva, sino ofrecer una visión clara y útil para entender qué hace cada algoritmo y cuándo puede aplicarse.
Tanto si estás empezando en ciencia de datos como si necesitas una referencia rápida, este mapa conceptual puede ayudarte a identificar qué familia de algoritmos encaja mejor con cada tipo de problema.

Deja un comentario