
Dado el auge de los medidores de electricidad inteligentes y la amplia adopción de tecnología de generación de electricidad como los paneles solares, hay una gran cantidad de datos disponibles sobre el uso de electricidad.
Estos datos representan una serie temporal multivariante de variables relacionadas con la energía, que a su vez podrían usarse para modelar e incluso pronosticar el consumo futuro de electricidad.
Nuestro objetivos en este post son:
- Conocer el conjunto de datos de consumo de energía del hogar que describe el uso de electricidad para una sola casa durante cuatro años.
- Cómo explorar y comprender el conjunto de datos mediante un conjunto de gráficos de líneas para los datos de la serie y el histograma para las distribuciones de datos.
- Cómo usar la nueva comprensión del problema para considerar diferentes encuadres del problema de predicción, formas en que se pueden preparar los datos y métodos de modelado que se pueden usar.

Todos los ejemplos que vamos a ver los implementaremos en Python . Python es un lenguaje de programación interpretado de alto nivel, desarrollado por Guido van Rossum a finales de los años 80. Se caracteriza por su sintaxis clara y legible, lo cual lo hace muy amigable para principiantes en la programación.
Python es multipropósito y se utiliza en una amplia gama de aplicaciones, desde desarrollo web y científico, hasta análisis de datos, inteligencia artificial y automatización de tareas. Es conocido por su filosofía de diseño que enfatiza la legibilidad del código y su enfoque en la simplicidad y la elegancia.
Python cuenta con una amplia biblioteca estándar que proporciona módulos y funciones predefinidas que facilitan tareas comunes, como manejo de archivos, redes, acceso a bases de datos, procesamiento de texto, entre otros. Además, existe una gran cantidad de paquetes y bibliotecas de terceros disponibles que extienden la funcionalidad de Python y permiten a los desarrolladores aprovechar una amplia variedad de herramientas ( en este post por ejemplo vamos a usar las librerias Pandas, matplotlib y numpy).
Una de las razones de la popularidad de Python es su comunidad activa y su enfoque en el código abierto. Esto ha llevado a la creación de numerosos recursos educativos, tutoriales y documentación que facilitan el aprendizaje y la resolución de problemas en Python.
Python es compatible con múltiples plataformas, lo que significa que puede ejecutarse en sistemas operativos como Windows, macOS, Linux, así como en entornos en la nube. Existen diferentes versiones de Python, siendo Python 3 la versión más reciente y recomendada para nuevos proyectos, aunque Python 2 también se utilizó ampliamente en el pasado. Actualmente la mayoría de la comunidad no usa el IDE por defecto, usando en su lugar el entorno de cuadernos de Jupyter Notebook.Jupyter Notebook es un entorno de desarrollo interactivo que permite la creación y ejecución de código en diferentes lenguajes de programación, incluyendo Python. Proporciona una interfaz basada en web que combina celdas de código, texto enriquecido y elementos multimedia en un único documento.
Para utilizar Jupyter Notebook con Python, necesitará tener Python instalado en tu sistema. Puede descargar Python desde el sitio web oficial (https://www.python.org/) y seguir las instrucciones de instalación adecuadas para su sistema operativo.
Una vez que tenga Python instalado, puede instalar Jupyter Notebook utilizando el gestor de paquetes de Python, pip, ejecutando el siguiente comando en tu terminal o símbolo del sistema:
pip install jupyter
Una vez que haya instalado Jupyter Notebook, puedes abrirlo ejecutando el siguiente comando en su terminal o símbolo del sistema:
jupyter notebook
Esto abrirá una nueva pestaña o ventana en tu navegador web predeterminado, mostrando el panel de control de Jupyter Notebook. Desde allí, puedes crear un nuevo notebook haciendo clic en «New» y seleccionando «Python 3» (o cualquier versión de Python que hayas instalado). A continuación, se abrirá un nuevo notebook con una celda de código vacía. Puedes escribir tu código en la celda y ejecutarlo presionando Shift + Enter. El resultado de la ejecución se mostrará debajo de la celda.
Además de las celdas de código, Jupyter Notebook también admite celdas de texto enriquecido (en formato Markdown), lo que permite agregar explicaciones, documentación, etc. Puede cambiar el tipo de una celda haciendo clic en el menú desplegable en la barra de herramientas superior.
Jupyter Notebook también proporciona una serie de funcionalidades adicionales, como la capacidad de importar bibliotecas, visualizar datos en gráficos interactivos y compartir tus notebooks con otros usuarios.
En resumen, Jupyter Notebook es una herramienta poderosa y versátil para trabajar con Python, permitiendo la creación de documentos interactivos que combinan código, texto y elementos multimedia. Es ampliamente utilizado en la comunidad de científicos de datos y desarrolladores para el análisis de datos, la experimentación y la presentación de resultados como los que vamos a ver a continuación.
Conjunto de datos de consumo de energía del hogar
El consumo de energía del hogar es un conjunto de datos de series de tiempo multivariado que describe el consumo de electricidad de un solo hogar durante cuatro años.
En el ejemplo que vamos a ver, los datos se recopilaron entre diciembre de 2006 y noviembre de 2010 y cada minuto se recopilaron observaciones del consumo de energía dentro del hogar.
Es una serie multivariada compuesta por siete variables (además de la fecha y la hora); ellos son:
- global_active_power : la potencia activa total consumida por el hogar (kilovatios).
- global_reactive_power : La potencia reactiva total consumida por el hogar (kilovatios).
- voltaje : Voltaje promedio (voltios).
- global_intensity : Intensidad de corriente promedio (amperios).
- sub_metering_1 : Energía activa para cocina (vatios-hora de energía activa).
- sub_metering_2 : Energía activa para lavandería (vatios-hora de energía activa).
- sub_metering_3 : Energía activa para sistemas de control climático (vatios-hora de energía activa).
En términos generales, la energía activa es la potencia real consumida por el hogar, mientras que la energía reactiva es la potencia no utilizada en las líneas.
Podemos ver que el conjunto de datos proporciona la potencia activa, así como alguna división de la potencia activa por el circuito principal de la casa, específicamente la cocina, la lavadora y la climatización pero ya sabemos que estos no son todos los circuitos en el hogar (aunque suponga gran parte del consumo global).
Los vatios-hora restantes se pueden calcular a partir de la energía activa convirtiendo primero la energía activa en vatios-hora y luego restando la otra energía activa submedida en vatios-hora, de la siguiente manera:
sub_metering_remainder = (global_active_power * 1000 / 60) - (sub_metering_1 + sub_metering_2 + sub_metering_3) El conjunto de datos parece haber sido proporcionado sin un documento de referencia fundamental.
Sin embargo, este conjunto de datos se ha convertido en un estándar para evaluar la predicción de series temporales y los métodos de aprendizaje automático para la predicción de varios pasos, específicamente para la predicción de la potencia activa. Además, no está claro si las otras características del conjunto de datos pueden beneficiar a un modelo para pronosticar la potencia activa.
Cargar conjunto de datos
El conjunto de datos se puede descargar desde el repositorio de UCI Machine Learning como un solo archivo .zip de 20 megabytes: consumo_electricidad_hogar.zip
Descargue el conjunto de datos y descomprímalo en su directorio de trabajo actual. Ahora tendrá el archivo “ home_power_consumption.txt » que tiene un tamaño de aproximadamente 127 megabytes y contiene todas las observaciones.
Inspección del archivo de datos.
A continuación se muestran las primeras cinco filas de datos (y el encabezado) del archivo de datos sin procesar.

Podemos ver que las columnas de datos están separadas por punto y coma (‘ ; ‘). Se informa que los datos tienen una fila para cada día en el período de tiempo. Los datos tienen valores faltantes; por ejemplo, podemos ver 2-3 días de datos faltantes alrededor del 28/4/2007.

Podemos comenzar cargando el archivo de datos como Pandas DataFrame y resumir los datos cargados. Para ello podemos usar la función read_csv() para cargar los datos. Es fácil cargar los datos con esta función, pero es un poco complicado cargarlos correctamente.
Específicamente, necesitamos hacer algunas cosas personalizadas:
- Especifique la separación entre columnas como un punto y coma (sep=’;’)
- Especifique que la línea 0 tiene los nombres de las columnas (encabezado = 0)
- Especifique que tenemos mucha RAM para evitar una advertencia de que estamos cargando los datos como una matriz de objetos en lugar de una matriz de números, debido al ‘?’ valores para datos faltantes (low_memory=False).
- Especifique que está bien que Pandas intente inferir el formato de fecha y hora al analizar las fechas, lo cual es mucho más rápido (infer_datetime_format=True)
- Especifique que nos gustaría analizar las columnas de fecha y hora juntas como una nueva columna llamada ‘datetime’ (parse_dates={‘datetime’:[0,1]})
- Especifique que nos gustaría que nuestra nueva columna ‘datetime’ sea el índice del DataFrame (index_col=[‘datetime’]).
Juntando todo esto, ahora podemos cargar los datos y resumir la forma cargada y las primeras filas.
# load all data
dataset = read_csv(‘household_power_consumption.txt’, sep=’;’, header=0, low_memory=False, infer_datetime_format=True, parse_dates={‘datetime’:[0,1]}, index_col=[‘datetime’])
# summarize
print(dataset.shape)
print(dataset.head())
A continuación, podemos marcar todos los valores faltantes indicados con un ‘?’ carácter con un valor NaN, que es un flotante. Esto nos permitirá trabajar con los datos como una matriz de valores de coma flotante en lugar de tipos mixtos, lo que es menos eficiente.
# mark all missing values
dataset.replace('?', nan, inplace=True)Ahora podemos crear una nueva columna que contenga el resto de la submedición, utilizando el cálculo de la sección anterior.
# add a column for for the remainder of sub metering
values = dataset.values.astype('float32')
dataset['sub_metering_4'] = (values[:,0] * 1000 / 60) - (values[:,4] + values[:,5] + values[:,6])Ahora podemos guardar la versión limpia del conjunto de datos en un nuevo archivo; en este caso, simplemente cambiaremos la extensión del archivo a .csv y guardaremos el conjunto de datos como ‘ home_power_consumption.csv ‘.
# save updated dataset
dataset.to_csv('household_power_consumption.csv')Para confirmar que no nos hemos equivocado, podemos volver a cargar el conjunto de datos y resumir las primeras cinco filas.
# load the new file
dataset = read_csv('household_power_consumption.csv', header=None)
print(dataset.head())Uniendo todo esto, el ejemplo completo de cargar, limpiar y guardar el conjunto de datos se enumera a continuación.
# load and clean-up data
from numpy import nan
from pandas import read_csv
# load all data
dataset = read_csv('household_power_consumption.txt', sep=';', header=0, low_memory=False, infer_datetime_format=True, parse_dates={'datetime':[0,1]}, index_col=['datetime'])
# summarize
print(dataset.shape)
print(dataset.head())
# mark all missing values
dataset.replace('?', nan, inplace=True)
# add a column for for the remainder of sub metering
values = dataset.values.astype('float32')
dataset['sub_metering_4'] = (values[:,0] * 1000 / 60) - (values[:,4] + values[:,5] + values[:,6])
# save updated dataset
dataset.to_csv('household_power_consumption.csv')
# load the new dataset and summarize
dataset = read_csv('household_power_consumption.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime'])
print(dataset.head())Al ejecutar el ejemplo, primero se cargan los datos sin procesar y se resume la forma y las primeras cinco filas de los datos cargados.
(2075259, 7)
Global_active_power ... Sub_metering_3
datetime ...
2006-12-16 17:24:00 4.216 ... 17.0
2006-12-16 17:25:00 5.360 ... 16.0
2006-12-16 17:26:00 5.374 ... 17.0
2006-12-16 17:27:00 5.388 ... 17.0
2006-12-16 17:28:00 3.666 ... 17.0Luego, el conjunto de datos se limpia y se guarda en un archivo nuevo.
Cargamos este nuevo archivo y nuevamente imprimimos las primeras cinco filas, mostrando la eliminación de las columnas de fecha y hora y la adición de la nueva columna submedida.
Global_active_power ... sub_metering_4
datetime ...
2006-12-16 17:24:00 4.216 ... 52.266670
2006-12-16 17:25:00 5.360 ... 72.333336
2006-12-16 17:26:00 5.374 ... 70.566666
2006-12-16 17:27:00 5.388 ... 71.800000
2006-12-16 17:28:00 3.666 ... 43.100000Podemos echar un vistazo dentro del nuevo archivo ‘ home_power_consumption.csv ‘ y comprobar que las observaciones que faltan están marcadas con una columna vacía, que los pandas leerán correctamente como NaN, por ejemplo, alrededor de la fila 190.499:
...
2007-04-28 00:20:00,0.492,0.208,236.240,2.200,0.000,0.000,0.0,8.2
2007-04-28 00:21:00,,,,,,,,
2007-04-28 00:22:00,,,,,,,,
2007-04-28 00:23:00,,,,,,,,
2007-04-28 00:24:00,,,,,,,,
2007-04-28 00:25:00,,,,,,,,Ahora que tenemos una versión limpia del conjunto de datos, podemos investigarlo más a fondo mediante visualizaciones.
Patrones en las observaciones a lo largo del tiempo
Los datos son una serie de tiempo multivariable y la mejor manera de entender una serie de tiempo es crear diagramas de líneas. Podemos comenzar creando un gráfico de líneas separado para cada una de las ocho variables.
El ejemplo completo se muestra a continuación.
# line plots
from pandas import read_csv
from matplotlib import pyplot
# load the new file
dataset = read_csv('household_power_consumption.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime'])
# line plot for each variable
pyplot.figure()
for i in range(len(dataset.columns)):
pyplot.subplot(len(dataset.columns), 1, i+1)
name = dataset.columns[i]
pyplot.plot(dataset[name])
pyplot.title(name, y=0)
pyplot.show()Ejecutar el ejemplo crea una sola imagen con ocho subparcelas, una para cada variable. Esto nos da un nivel realmente alto de los cuatro años de observaciones de un minuto. Podemos ver que algo interesante estaba sucediendo en ‘ Sub_metering_3 ‘ (control ambiental) que puede no estar directamente relacionado con años cálidos o fríos. Tal vez se instalaron nuevos sistemas.
Curiosamente, la contribución de ‘ sub_metering_4 ‘ parece disminuir con el tiempo, o mostrar una tendencia a la baja, tal vez coincidiendo con el sólido aumento observado hacia el final de la serie para ‘ Sub_metering_3 ‘.
Estas observaciones refuerzan la necesidad de respetar el orden temporal de las subsecuencias de estos datos al ajustar y evaluar cualquier modelo.
Es posible que podamos ver la ola de un efecto estacional en el ‘ Global_active_power ‘ y algunas otras variantes.
Hay algunos picos de uso que pueden coincidir con un período específico, como los fines de semana. Estos son los gráficos de líneas de cada variable en el conjunto de datos de consumo de energía:
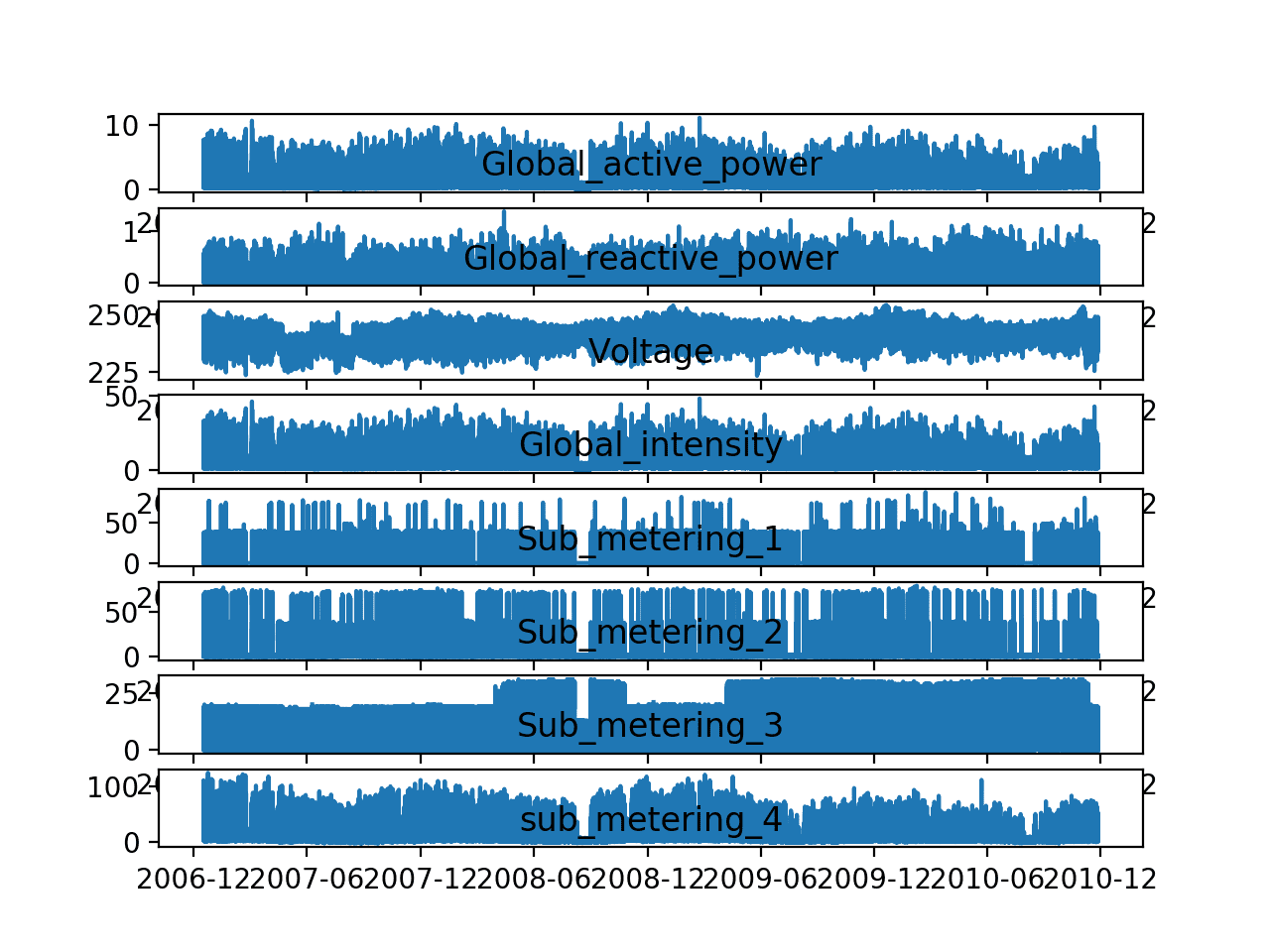
Acerquémonos y centrémonos en el ‘ Global_active_power ‘ o ‘ poder activo ‘ para abreviar. Podemos crear una nueva gráfica de la potencia activa para cada año para ver si hay patrones comunes a lo largo de los años. El primer año, 2006, tiene menos de un mes de datos, por lo que se eliminará de la gráfica.
El ejemplo completo se muestra a continuación.
# yearly line plots
from pandas import read_csv
from matplotlib import pyplot
# load the new file
dataset = read_csv('household_power_consumption.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime'])
# plot active power for each year
years = ['2007', '2008', '2009', '2010']
pyplot.figure()
for i in range(len(years)):
# prepare subplot
ax = pyplot.subplot(len(years), 1, i+1)
# determine the year to plot
year = years[i]
# get all observations for the year
result = dataset[str(year)]
# plot the active power for the year
pyplot.plot(result['Global_active_power'])
# add a title to the subplot
pyplot.title(str(year), y=0, loc='left')
pyplot.show()Ejecutar el ejemplo crea una sola imagen con cuatro diagramas de líneas, uno para cada año completo (o en su mayoría años completos) de datos en el conjunto de datos.
Estos son los gráficos lineales de potencia activa para la mayoría de los años:
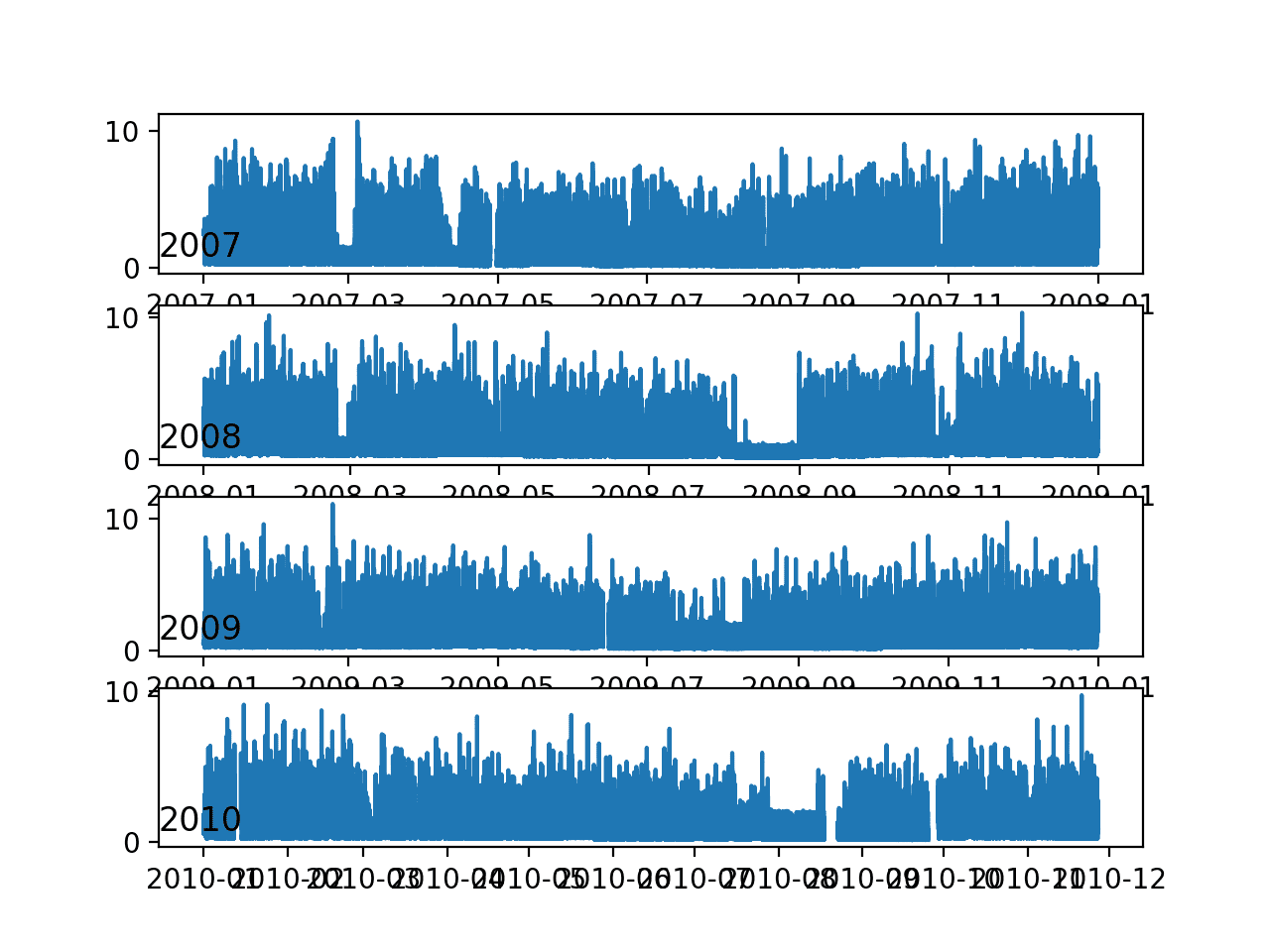
Podemos ver algunos patrones brutos comunes a lo largo de los años, como alrededor de febrero-marzo y alrededor de agosto-septiembre, donde vemos una marcada disminución en el consumo. También parece que vemos una tendencia a la baja durante los meses de verano (mediados de año en el hemisferio norte) y quizás más consumo en los meses de invierno hacia los bordes de las parcelas. Estos pueden mostrar un patrón estacional anual en el consumo. Asimismo podemos ver algunos parches de datos faltantes en al menos el primer, tercer y cuarto gráfico.
Podemos seguir ampliando el consumo y observar la potencia activa para cada uno de los 12 meses de 2007. Esto podría ayudar a desentrañar las estructuras brutas a lo largo de los meses, como los patrones diarios y semanales.
El ejemplo completo se muestra a continuación.
# monthly line plots
from pandas import read_csv
from matplotlib import pyplot
# load the new file
dataset = read_csv('household_power_consumption.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime'])
# plot active power for each year
months = [x for x in range(1, 13)]
pyplot.figure()
for i in range(len(months)):
# prepare subplot
ax = pyplot.subplot(len(months), 1, i+1)
# determine the month to plot
month = '2007-' + str(months[i])
# get all observations for the month
result = dataset[month]
# plot the active power for the month
pyplot.plot(result['Global_active_power'])
# add a title to the subplot
pyplot.title(month, y=0, loc='left')
pyplot.show()Ejecutar el ejemplo crea una sola imagen con 12 gráficos de líneas, uno para cada mes en 2007.
Estos son lo gráficos de líneas para potencia activa para todos los meses en un año: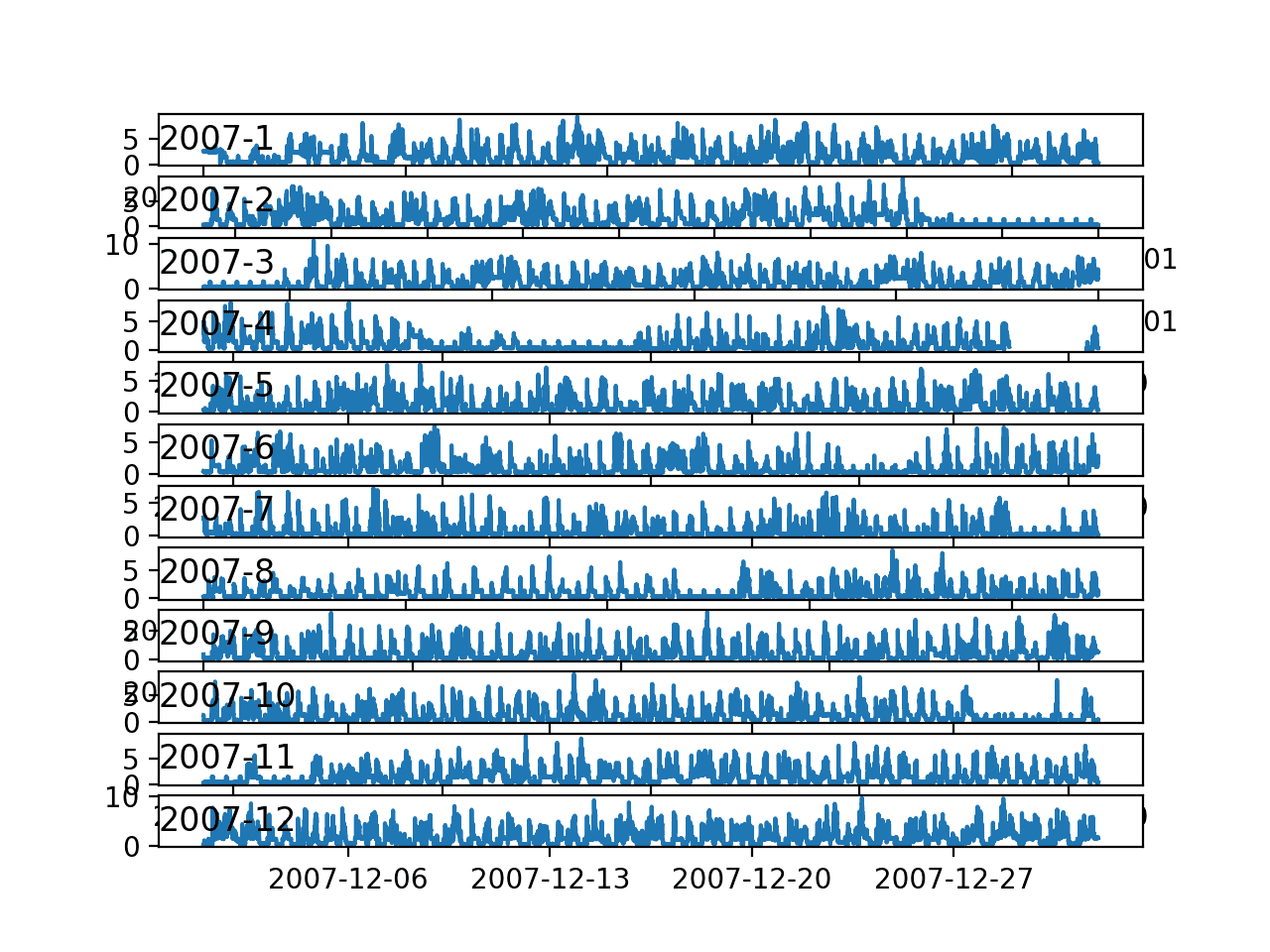
Podemos ver la señal de onda del consumo de energía de los días dentro de cada mes. Esto es bueno, ya que esperaríamos algún tipo de patrón diario en el consumo de energía. Vemos que hay tramos de días con un consumo muy mínimo, como en agosto y en abril. Estos pueden representar períodos de vacaciones en los que la casa estuvo desocupada y en los que el consumo de energía fue mínimo.
Finalmente, podemos ampliar un nivel más y observar más de cerca el consumo de energía a nivel diario. Esperaríamos que hubiera algún patrón de consumo cada día, y tal vez diferencias en días durante una semana.
El ejemplo completo se muestra a continuación.
# daily line plots
from pandas import read_csv
from matplotlib import pyplot
# load the new file
dataset = read_csv('household_power_consumption.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime'])
# plot active power for each year
days = [x for x in range(1, 20)]
pyplot.figure()
for i in range(len(days)):
# prepare subplot
ax = pyplot.subplot(len(days), 1, i+1)
# determine the day to plot
day = '2007-01-' + str(days[i])
# get all observations for the day
result = dataset[day]
# plot the active power for the day
pyplot.plot(result['Global_active_power'])
# add a title to the subplot
pyplot.title(day, y=0, loc='left')
pyplot.show()Al ejecutar el ejemplo, se crea una sola imagen con 20 gráficos de líneas, uno para los primeros 20 días de enero de 2007.
Este son los gráficos de líneas para potencia activa durante 20 días en un mes: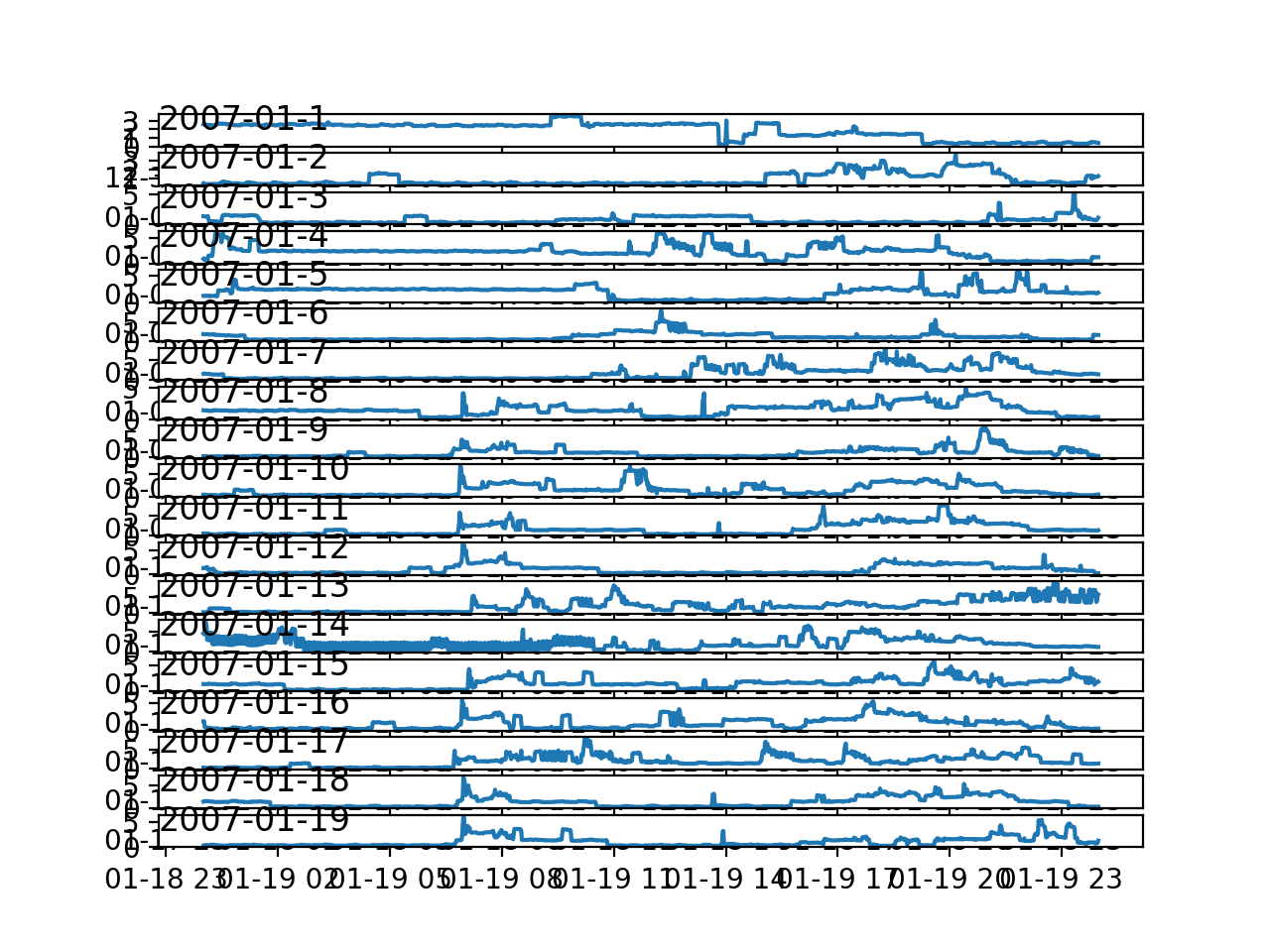
Hay puntos en común a lo largo de los días; por ejemplo, muchos días el consumo comienza temprano en la mañana, alrededor de las 6-7 AM.
Algunos días muestran una caída en el consumo a la mitad del día, lo que podría tener sentido si la mayoría de los ocupantes están fuera de casa.
Vemos un fuerte consumo durante la noche en algunos días, que en enero del hemisferio norte puede coincidir con el uso de un sistema de calefacción.
La época del año, específicamente la estación y el clima que trae, será un factor importante en el modelado de estos datos, como era de esperar.
Distribuciones de datos de series temporales
Otra área importante a considerar es la distribución de las variables. Por ejemplo, puede ser interesante saber si las distribuciones de las observaciones son gaussianas o alguna otra distribución.
Podemos investigar las distribuciones de los datos revisando histogramas. Asimismo podemos comenzar creando un histograma para cada variable en la serie temporal.
El ejemplo completo se muestra a continuación.
# daily line plots
from pandas import read_csv
from matplotlib import pyplot
# load the new file
dataset = read_csv('household_power_consumption.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime'])
# plot active power for each year
days = [x for x in range(1, 20)]
pyplot.figure()
for i in range(len(days)):
# prepare subplot
ax = pyplot.subplot(len(days), 1, i+1)
# determine the day to plot
day = '2007-01-' + str(days[i])
# get all observations for the day
result = dataset[day]
# plot the active power for the day
pyplot.plot(result['Global_active_power'])
# add a title to the subplot
pyplot.title(day, y=0, loc='left')
pyplot.show()Ejecutar el ejemplo crea una sola figura con un histograma separado para cada una de las 8 variables. El resultado son los gráficos de histograma para cada variable en el conjunto de datos de consumo de energía:
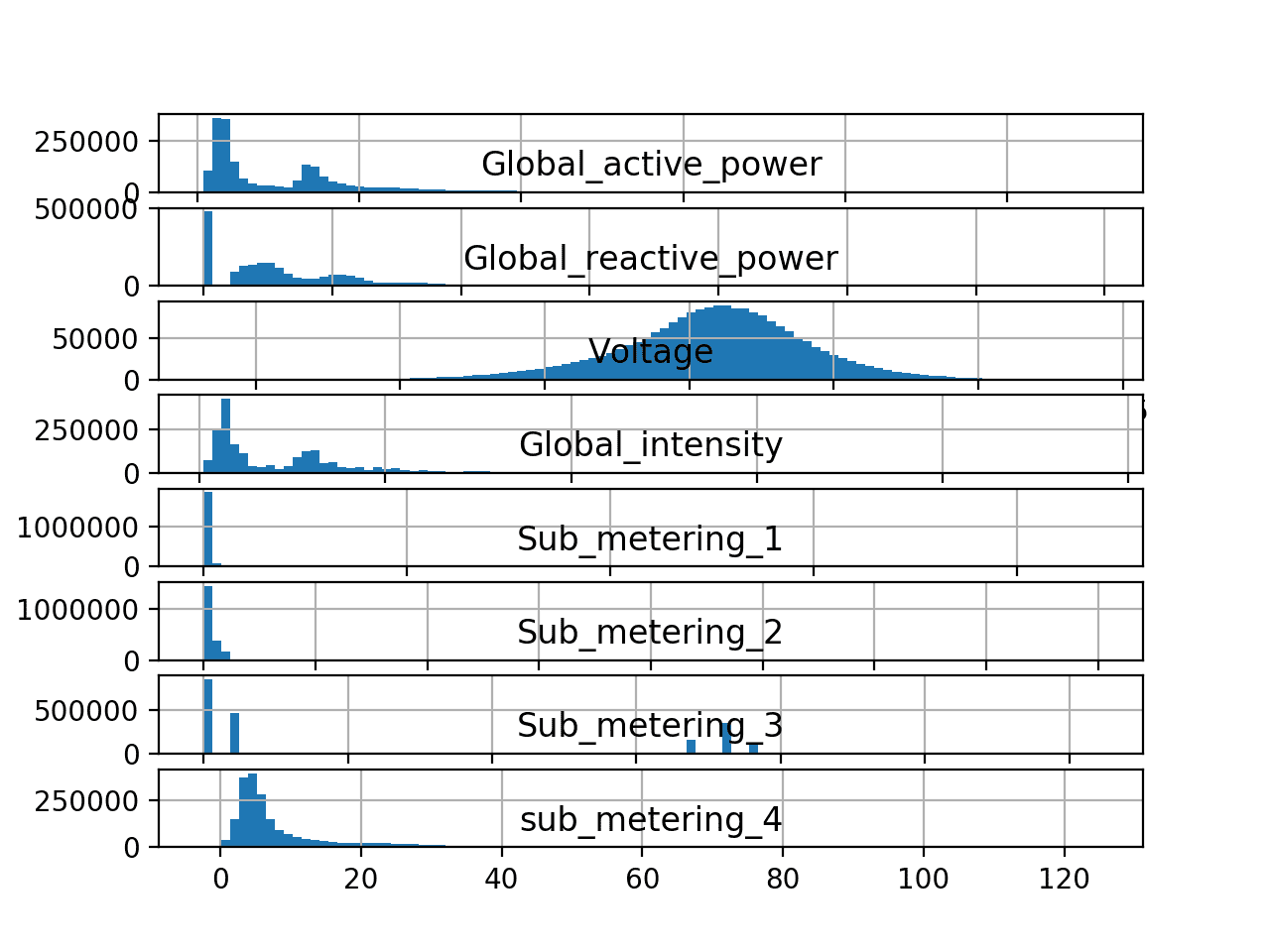
Podemos ver que la potencia activa y reactiva, la intensidad, así como la potencia submedida son distribuciones sesgadas hacia valores pequeños de vatios-hora o kilovatios. También podemos ver que la distribución de los datos de voltaje es fuertemente gaussiana.
La distribución de la potencia activa parece ser bimodal, lo que significa que parece tener dos grupos medios de observaciones. Se puede investigar esto más a fondo observando la distribución del consumo de energía activa para los cuatro años completos de datos.
El ejemplo completo se muestra a continuación.
# yearly histogram plots
from pandas import read_csv
from matplotlib import pyplot
# load the new file
dataset = read_csv('household_power_consumption.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime'])
# plot active power for each year
years = ['2007', '2008', '2009', '2010']
pyplot.figure()
for i in range(len(years)):
# prepare subplot
ax = pyplot.subplot(len(years), 1, i+1)
# determine the year to plot
year = years[i]
# get all observations for the year
result = dataset[str(year)]
# plot the active power for the year
result['Global_active_power'].hist(bins=100)
# zoom in on the distribution
ax.set_xlim(0, 5)
# add a title to the subplot
pyplot.title(str(year), y=0, loc='right')
pyplot.show()Ejecutar el ejemplo crea una sola gráfica con cuatro cifras, una para cada uno de los años entre 2007 y 2010. Obtenemos las siguientes Gráficas de histograma de potencia activa para la mayoría de los años:
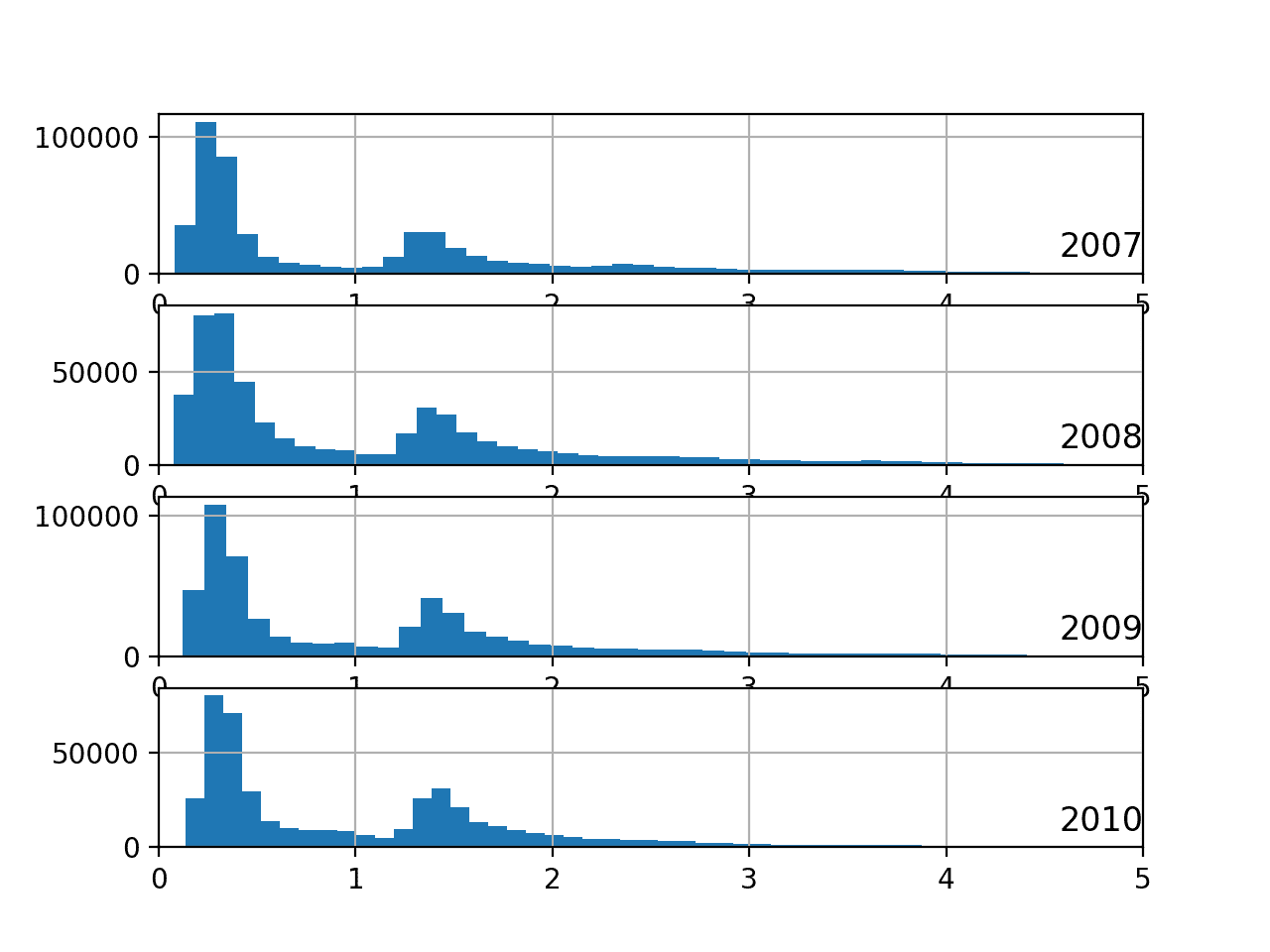
Podemos ver que la distribución del consumo de energía activa a lo largo de esos años es muy similar. De hecho, la distribución es bimodal con un pico alrededor de 0,3 KW y quizás otro alrededor de 1,3 KW.
Hay una cola larga en la distribución a valores de kilovatios más altos. Podría abrir la puerta a las nociones de discretizar los datos y separarlos en pico 1, pico 2 o cola larga. Estos grupos o conglomerados para uso en un día o una hora pueden ser útiles para desarrollar un modelo predictivo.
Es posible que los grupos identificados varíen a lo largo de las estaciones del año. Podemos investigar esto observando la distribución de potencia activa para cada mes en un año.
El ejemplo completo se muestra a continuación.
# monthly histogram plots
from pandas import read_csv
from matplotlib import pyplot
# load the new file
dataset = read_csv('household_power_consumption.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime'])
# plot active power for each year
months = [x for x in range(1, 13)]
pyplot.figure()
for i in range(len(months)):
# prepare subplot
ax = pyplot.subplot(len(months), 1, i+1)
# determine the month to plot
month = '2007-' + str(months[i])
# get all observations for the month
result = dataset[month]
# plot the active power for the month
result['Global_active_power'].hist(bins=100)
# zoom in on the distribution
ax.set_xlim(0, 5)
# add a title to the subplot
pyplot.title(month, y=0, loc='right')
pyplot.show()Ejecutar el ejemplo crea una imagen con 12 parcelas, una para cada mes en 2007. Obtenemos así los gráficos de histograma para potencia activa para todos los meses en un año:
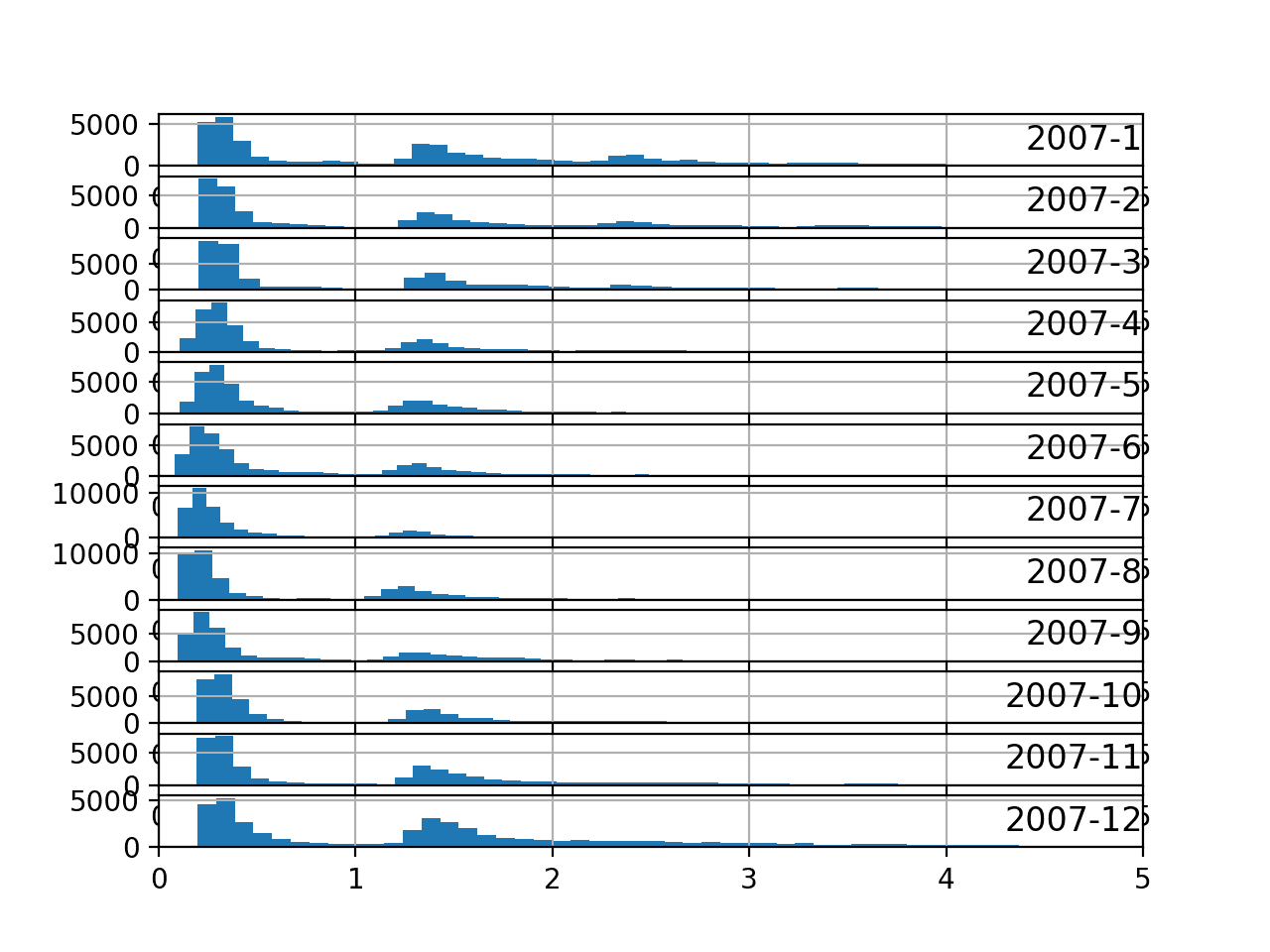
Podemos ver generalmente la misma distribución de datos cada mes. Los ejes de los gráficos parecen alinearse (dadas las escalas similares), y podemos ver que los picos se desplazan hacia abajo en los meses más cálidos del hemisferio norte y hacia arriba en los meses más fríos.
También podemos ver una cola más gruesa o más prominente hacia valores de kilovatios más grandes para los meses más fríos de diciembre a marzo.
Ideas sobre Modelado
Ahora que sabemos cómo cargar y explorar el conjunto de datos, podemos plantear algunas ideas sobre cómo modelar el conjunto de datos de modo que ya podemos analizar más de cerca tres áreas principales al trabajar con los datos; ellos son:
- Encuadre del problema.
- Preparación de datos.
- Métodos de modelado.
Encuadre del problema
No parece haber una publicación fundamental para el conjunto de datos que demuestre la forma prevista de enmarcar los datos en un problema de modelado predictivo. Por lo tanto, nos queda adivinar las formas posiblemente útiles en que se pueden usar estos datos.
Los datos son solo para un solo hogar, pero quizás los enfoques de modelado efectivos podrían generalizarse a hogares similares. Quizás el encuadre más útil del conjunto de datos es pronosticar un intervalo de consumo futuro de energía activa.
Cuatro ejemplos incluyen:
- Previsión de consumo horario para el día siguiente.
- Pronóstico de consumo diario para la próxima semana.
- Pronóstico de consumo diario para el próximo mes.
- Previsión de consumo mensual para el próximo año.
En general, estos tipos de problemas de pronóstico se denominan pronósticos de varios pasos. Los modelos que hacen uso de todas las variables pueden denominarse modelos de pronóstico multivariante de varios pasos.
Cada uno de estos modelos no se limita a pronosticar los datos por minuto, sino que podría modelar el problema en o por debajo de la resolución de pronóstico elegida.
Pronosticar el consumo a su vez, a escala, podría ayudar a una empresa de servicios públicos a pronosticar la demanda, que es un problema importante y ampliamente estudiado.
Preparación de datos
Hay mucha flexibilidad en la preparación de estos datos para el modelado.
Los métodos específicos de preparación de datos y su beneficio realmente dependen del encuadre elegido del problema y los métodos de modelado. No obstante, a continuación se incluye una lista de métodos generales de preparación de datos que pueden resultar útiles:
- La diferenciación diaria puede ser útil para ajustar el ciclo diario en los datos.
- La diferenciación anual puede ser útil para ajustar cualquier ciclo anual en los datos.
- La normalización puede ayudar a reducir las variables con diferentes unidades a la misma escala.
Hay muchos factores humanos simples que pueden ser útiles en la ingeniería de características a partir de los datos, que a su vez pueden hacer que días específicos sean más fáciles de pronosticar.
Algunos ejemplos incluyen:
- Indicar la hora del día, para tener en cuenta la probabilidad de que las personas estén en casa o no.
- Indicando si un día es entre semana o fin de semana.
- Indica si un día es feriado público norteamericano o no.
Estos factores pueden ser significativamente menos importantes para pronosticar datos mensuales y quizás hasta cierto punto para datos semanales.
Las características más generales pueden incluir:
- Indicando la temporada, lo que puede dar lugar al tipo oa la cantidad de sistemas de control ambiental que se utilicen.
Métodos de modelado
Hay quizás cuatro clases de métodos que podrían ser interesantes para explorar en este problema; ellos son:
- Métodos ingenuos (Naive Methods).
- Métodos lineales clásicos.
- Métodos de aprendizaje automático.
- Métodos de aprendizaje profundo.
Métodos ingenuos (Naive Methods)
Los métodos ingenuos incluirían métodos que hacen suposiciones muy simples, pero a menudo muy efectivas.
Algunos ejemplos incluyen:
- Mañana será igual que hoy.
- Mañana será igual que este día el año pasado.
- Mañana será un promedio de los últimos días.
Métodos lineales clásicos
Los métodos lineales clásicos incluyen técnicas que son muy efectivas para el pronóstico de series temporales univariadas.
Dos ejemplos importantes incluyen:
- SARIMA
- ETS (suavización exponencial triple)
Requerirían que las variables adicionales se descarten y que los parámetros del modelo se configuren o ajusten al marco específico del conjunto de datos. Las preocupaciones relacionadas con el ajuste de los datos para las estructuras diarias y estacionales también se pueden atender directamente.
Métodos de aprendizaje automático
Los métodos de aprendizaje automático requieren que el problema se enmarque como un problema de aprendizaje supervisado.
Esto requeriría que las observaciones de retraso para una serie se enmarquen como características de entrada, descartando la relación temporal en los datos.
Se podría explorar un conjunto de métodos no lineales y de conjuntos, que incluyen:
- k-vecinos más cercanos.
- Máquinas de vectores de soporte
- Árboles de decisión
- Bosque aleatorio
- Máquinas de aumento de gradiente
Se requiere atención cuidadosa para garantizar que el ajuste y la evaluación de estos modelos conserven la estructura temporal de los datos. Esto es importante para que el método no pueda «hacer trampa» aprovechando las observaciones del futuro.
Estos métodos suelen ser independientes de un gran número de variables y pueden ayudar a determinar si las variables adicionales se pueden aprovechar y agregar valor a los modelos predictivos.
Métodos de aprendizaje profundo
Generalmente, las redes neuronales no han demostrado ser muy efectivas en problemas de tipo autorregresión.
Sin embargo, técnicas como las redes neuronales convolucionales pueden aprender automáticamente características complejas a partir de datos sin procesar, incluidos los datos de señales unidimensionales. Y las redes neuronales recurrentes, como la red de memoria a corto plazo, son capaces de aprender directamente a través de múltiples secuencias paralelas de datos de entrada.
Además, las combinaciones de estos métodos, como CNN LSTM y ConvLSTM, han demostrado su eficacia en las tareas de clasificación de series temporales.
Es posible que estos métodos puedan aprovechar el gran volumen de datos basados en minutos y múltiples variables de entrada.
Fuente https://machinelearningmastery.com/how-to-load-and-explore-household-electricity-usage-data/

Deja un comentario