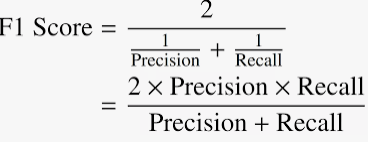
La puntuación F, también llamada puntuación F1, es una medida de la precisión de un modelo en un conjunto de datos. Se utiliza para evaluar los sistemas de clasificación binaria, que clasifican los ejemplos en ‘positivos’ o ‘negativos’.El puntaje F es una forma de combinar la precisión y la recuperación del modelo, y se define como la media armónica de la precisión y la recuperación del modelo usandose comúnmente para evaluar los sistemas de recuperación de información, como los motores de búsqueda, y también para muchos tipos de modelos de aprendizaje automático , en particular en el procesamiento del lenguaje natural .
Es posible ajustar la puntuación F para dar más importancia a la precisión que a la recuperación, o viceversa. Los puntajes F ajustados comunes son el puntaje F0.5 y el puntaje F2, así como el puntaje F1 estándar.
Precisión se refiere a la dispersión del conjunto de valores obtenidos de mediciones repetidas de una magnitud. Cuanto menor es la dispersión mayor la precisión. Una medida común de la variabilidad es la desviación estándar de las mediciones y la precisión se puede estimar como una función de ella. Es importante resaltar que la automatización de diferentes pruebas o técnicas puede producir un aumento de la precisión. Esto se debe a que con dicha automatización, lo que logramos es una disminución de los errores manuales o su corrección inmediata. No hay que confundir resolución con precisión.
Exactitud se refiere a cuán cerca del valor real se encuentra el valor medido. En términos estadísticos, la exactitud está relacionada con el sesgo de una estimación. Cuanto menor es el sesgo más exacta es una estimación. Cuando se expresa la exactitud de un resultado, se expresa mediante el error absoluto que es la diferencia entre el valor experimental y el valor verdadero.
Fórmulas
La exactitud (accuaracy en ingles) se utiliza también como una medida estadística de que tan bien una prueba de clasificación binaria identifica correctamente o excluye una condición.
Esto es, la exactitud es la proporción de resultados verdaderos (tanto verdaderos positivos (VP) como verdaderos negativos (VN)) entre el número total de casos examinados (verdaderos positivos, falsos positivos, verdaderos negativos, falsos negativos).
Para dejar en claro el contexto por la semántica, a menudo se refiere como «exactitud Rand» or «índice Rand».
Es un parámetro de la prueba

Una exactitud del 100% significa que los valores medidos son exactamente los mismos que los dados.
Por otro lado, la precisión o valor predictivo positivo se define como la proporción de verdaderos positivos contra todos los resultados positivos (tanto verdaderos positivos, como falsos positivos)

La fórmula para la puntuación F1 estándar es la media armónica de la precisión y la recuperación. Un modelo perfecto tiene una puntuación F de 1.

Explicación de los símbolos de la fórmula de puntuación F
| precisión | La precisión es la fracción de verdaderos ejemplos positivos entre los ejemplos que el modelo clasificó como positivos. En otras palabras, el número de verdaderos positivos dividido por el número de falsos positivos más los verdaderos positivos. |
| recuerdo | El recuerdo, también conocido como sensibilidad, es la fracción de ejemplos clasificados como positivos, entre el número total de ejemplos positivos. En otras palabras, el número de verdaderos positivos dividido por el número de verdaderos positivos más los falsos negativos. |
 | El número de verdaderos positivos clasificados por el modelo. |
 | El número de falsos negativos clasificados por el modelo. |
 | El número de falsos positivos clasificados por el modelo. |
Fórmula de puntuación F β generalizada
El puntaje F ajustado nos permite ponderar la precisión o recordar más alto si es más importante para nuestro caso de uso. Su fórmula es ligeramente diferente:

Definición matemática de la puntuación F β
Un factor que indica cuánto más importante es recordar que la precisión. Por ejemplo, si consideramos que recordar es dos veces más importante que la precisión, podemos establecer β en 2. La puntuación F estándar es equivalente a establecer β en uno.
Recordamos que el F-score es la media geométrica de precisión y recordación. Al igual que la media aritmética, como media geométrica, la puntuación F se encuentra entre la precisión y la recuperación.
Puntuación F frente a precisión
Hay una serie de métricas que se pueden utilizar para evaluar un modelo de clasificación binaria, y la precisión es una de las más sencillas de entender. La precisión se define simplemente como el número de ejemplos categorizados correctamente dividido por el número total de ejemplos. La precisión puede ser útil, pero no tiene en cuenta las sutilezas de los desequilibrios de clase o los diferentes costos de los falsos negativos y los falsos positivos.
La puntuación F1 es útil:
• donde hay diferentes costos de falsos positivos o falsos negativos, como en el ejemplo de la mamografía
• o donde hay un gran desequilibrio de clases, como si el 10% de las manzanas en los árboles tienden a estar verdes. En este caso, la precisión sería engañosa, ya que un clasificador que clasificara todas las manzanas como maduras obtendría automáticamente un 90 % de precisión, pero sería inútil para las aplicaciones de la vida real.
La precisión tiene la ventaja de que es muy fácil de interpretar, pero la desventaja de que no es sólida cuando los datos están distribuidos de manera desigual o cuando hay un costo más alto asociado con un tipo particular de error.
Esto ilustra cómo la precisión como métrica es, en general, menos robusta e incapaz de capturar los matices de los diferentes tipos de errores.
Cálculo de la puntuación F frente a la precisión con un desequilibrio de clase
Imaginemos un árbol con 100 manzanas, 90 de las cuales están maduras y diez verdes.
Tenemos una IA que es muy fácil de activar y clasifica los 100 como maduros y recoge todo. Claramente, un modelo que clasifica todos los ejemplos como positivos no es muy útil.
En este caso, nuestra matriz de confusión sería la siguiente:
La precisión es la siguiente:

Podemos ver que nuestro modelo ha logrado una precisión del 90% sin tomar ninguna decisión útil.
Calculando la precisión y la recuperación, obtenemos


Poniendo esto en la fórmula para F 1 , obtenemos:
Teniendo en cuenta el desequilibrio de clases, si sospecháramos de antemano que nuestro modelo adolece de baja precisión, podríamos elegir un F-score ajustado con β = 0.5 para priorizar la precisión:
A partir de este ejemplo, podemos ver que la precisión es mucho menos sólida cuando hay un gran desequilibrio de clases, y la puntuación F se puede ajustar para tener en cuenta si consideramos que la precisión o la recuperación son más importantes para una tarea determinada.
Aplicaciones de puntuación F
Hay una serie de campos de la IA en los que la puntuación F es una métrica ampliamente utilizada para el rendimiento del modelo.
F-score en Recuperación de Información
Las aplicaciones de recuperación de información, como los motores de búsqueda, a menudo se evalúan con la puntuación F.
Un motor de búsqueda debe indexar potencialmente miles de millones de documentos y devolver una pequeña cantidad de resultados relevantes a un usuario en muy poco tiempo. Por lo general, la primera página de resultados que se devuelve al usuario solo contiene hasta diez documentos. La mayoría de los usuarios no hacen clic en la segunda página de resultados, por lo que es muy importante que los primeros diez resultados contengan páginas relevantes.
Originalmente, la puntuación F 1 se usaba principalmente para evaluar los motores de búsqueda, pero hoy en día normalmente se prefiere una puntuación F β calibrada, ya que permite un control más preciso y nos permite priorizar la precisión o la recuperación. Idealmente, un motor de búsqueda no debe perder ningún documento relevante para una consulta, pero tampoco debe devolver una gran cantidad de documentos irrelevantes en la primera página.
El puntaje F es una medida basada en conjuntos, lo que significa que si se calcula el puntaje F de los primeros diez resultados, el puntaje F no tiene en cuenta la clasificación relativa de esos documentos. Por este motivo, la puntuación F suele utilizarse junto con otras métricas, como la precisión media media o la precisión media interpolada de 11 puntos , para obtener una buena visión general del rendimiento del motor de búsqueda.
Puntuación F en procesamiento del lenguaje natural
Hay muchas aplicaciones de procesamiento de lenguaje natural que se evalúan más fácilmente con la puntuación F. Por ejemplo, en el reconocimiento de entidades nombradas , un modelo de aprendizaje automático analiza un documento y debe identificar cualquier nombre y dirección personal en el texto.
Historial de puntuación F
Se cree que el puntaje F fue definido por primera vez por el profesor holandés de informática Cornelis Joost van Rijsbergen, considerado uno de los padres fundadores del campo de la recuperación de información. En su libro de 1979 ‘Recuperación de información’, definió una función muy similar a la puntuación F, reconociendo la inadecuación de la precisión como métrica para los sistemas de recuperación de información.
En su libro, llamó a su métrica la función de Efectividad, y le asignó la letra E , porque “mide la efectividad de la recuperación con respecto a un usuario que concede β veces más importancia a la recuperación que a la precisión”. No se sabe por qué al puntaje F se le asigna la letra F hoy.
Referencias
Van Rijsbergen, CJ (1979). Recuperación de información (2ª ed.). Butterworth-Heinemann.
Y. Sasaki, La verdad de la medida F (2007), https://www.cs.odu.edu/~mukka/cs795sum09dm/Lecturenotes/Day3/F-measure-YS-26Oct07.pdf

Deja un comentario