La función de extender la pantalla generalmente implica conectar dos o más monitores al mismo ordenador y utilizar la tarjeta de gráficos y los puertos de video de ésta para extender el escritorio. Si desea extender la pantalla en Windows 11, necesitará conectar monitores adicionales directamente a la computadora que ejecuta el sistema operativo. Puede hacerlo a través de puertos como HDMI, DisplayPort o VGA, dependiendo de los puertos disponibles en su PC y en los monitores que desee utilizar. Luego, puede configurar la extensión de la pantalla en la configuración de Windows 11.Obviamente esta es la solución ideal , !y la mejor! para poder contar con dos pantallas de un modo muy sencillo, pues por ejemplo con Windows 11 bastará conectar estos monitores ( o en el caso de un portatil un monitor externo) y con la tecla windows+T alternar con las 4 combinaciones ( los dos individuales, el extendido o duplicado)
Bueno ¿ y sin en vez de contar con otro monitor disponemos de otro ordenador? Pues incluso sin desmontarlo y montarle un adaptador LVDS ,es posible mediante software, siempre que ambos estén conectados a la misma red. Usar otro ordenador con conexión Wi-Fi como segundo monitor requiere de un software especializado que permita extender o duplicar la pantalla de tu computadora principal. Existen varias aplicaciones y herramientas disponibles para lograr esto que vamos a explorar en este post.
Caso de usar otro ordenador tradicional como segunda pantalla
Vemos en primer lugar el caso de querer usar otro ordenador ( idealmente por ejemplo un portátil en desuso) con Windows o Linux como segunda pantalla pera lo cual veremos primero un método general utilizando la aplicación gratuita «Spacedesk«.
A continuación, veremos los pasos a seguir:
Asegúrese de que ambos ordenadores estén conectados a la misma red Wi-Fi.
En tu ordenador principal (el que deseas extender o duplicar la pantalla), abra un navegador web y dirígete al sitio web de Spacedesk (https://www.spacedesk.net/).
Descargue e instale la versión adecuada de Spacedesk según el sistema operativo del ordenador que utilizará como segundo monitor.
Una vez instalado, ejecute Spacedesk en ambos ordenadores.
En el ordenador principal, haga clic en el ícono de Spacedesk en la bandeja del sistema (junto al reloj) y selecciona «Server».
En el ordenador secundario (el que utilizará como segundo monitor), haga clic en el ícono de Spacedesk en la bandeja del sistema y seleccione «Viewer».
El ordenador secundario buscará automáticamente la conexión con el ordenador principal a través de la red Wi-Fi. Debería ver el nombre del servidor en la lista de dispositivos disponibles. Haga clic en él para establecer la conexión.
Una vez establecida la conexión, la pantalla del ordenador secundario se convertirá en una extensión o duplicación de la pantalla principal.
Tenga en cuenta que también existen otras aplicaciones y soluciones disponibles, por lo que puede investigar y probar diferentes opciones según sus necesidades y preferencias.
Caso de segunda pantalla de un ordenador con Chromium
Lamentablemente, no es posible extender la pantalla de Windows 11 utilizando otro ordenador con Chromium. Chromium es un proyecto de código abierto en el que se basan varios navegadores web, como Google Chrome. No es una solución diseñada para extender la pantalla de Windows. Chromium y los navegadores basados en él están destinados principalmente para la navegación web y no tienen la capacidad de extender el escritorio de Windows.
Sí, puede utilizar la extensión «Chrome Remote Desktop» para acceder de forma remota a su PC a desde una tableta , samrtphon con Android o como decimos desde un pc con cromium y ver su escritorio en la tableta, smartphone o pc con cromium. Sin embargo, es importante tener en cuenta que esto no es lo mismo que extender la pantalla de Windows 11 en otro dispositivo.
Con «Chrome Remote Desktop», puede controlar su pc de forma remota desde otro terminal y ver su escritorio en la pantalla de la tableta. Puede abrir y cerrar aplicaciones, acceder a archivos y realizar otras tareas en el pc, pero el terminal actuará como una ventana a su pc en lugar de una extensión de pantalla independiente. Es de destacar que el proceso de cromiun a pc también puede funcionar de forma inversa usando cromium como sever y conectándonos a este desde windows.
Para utilizar «Chrome Remote Desktop», sigue estos pasos:
Instale la extensión «Chrome Remote Desktop» en el navegador Google Chrome de su ordenador desde la Chrome Web Store. También en Windows es posible usar una aplicacion Eescritorio Remoto que es independiente
Configure la extensión ( o la aplicacion de escritorio remoto) y siga los pasos para permitir el acceso remoto a su pc
Descargue e instale la aplicación «Chrome Remote Desktop» desde Google crome ( en caso de cromium) o Google Play ( en caso de tableta o smartphone con Android).
Abra la aplicación en el caso de tableta o smartphone o en la extensión en caso de cromium y acceda con su cuenta de Google.
Conexión hacia un ordenador
Seleccione el ordenador la que desea conectarte desde la lista de dispositivos disponibles.
Siga las instrucciones para establecer la conexión remota.
Una vez conectado, podrás ver y controlar el escritorio de tu computadora desde la tableta con Android. Sin embargo, tenga en cuenta que esta configuración no extenderá la pantalla de Windows 11 en la tableta, sino que solo te permitirá acceder y controlar tu computadora de forma remota.
Conexión desde un ordenadorWindows hacia Cromium o Android
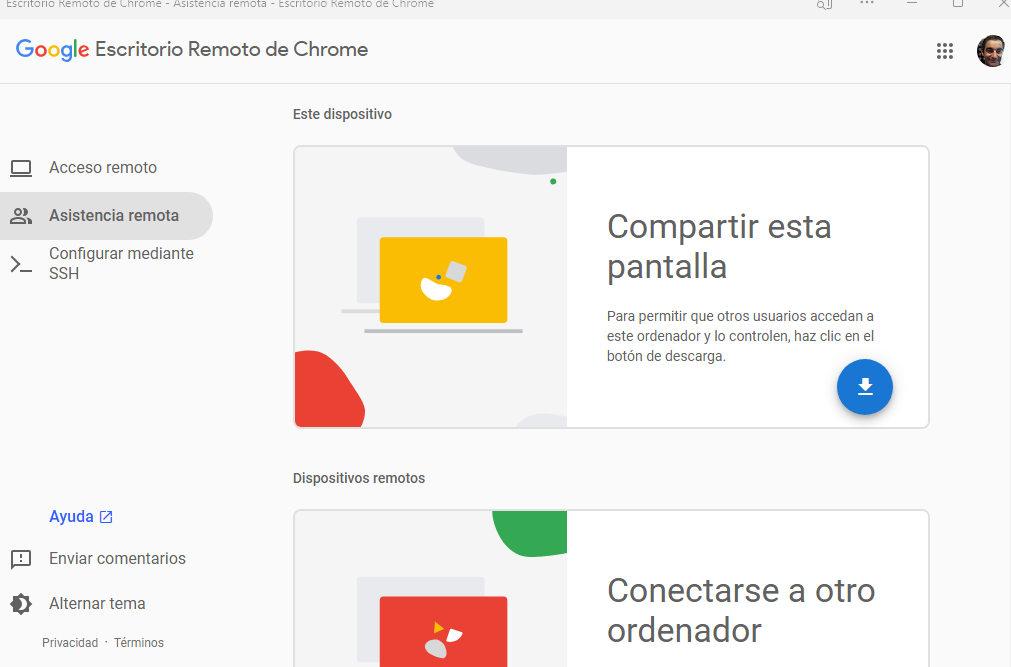
Desde el ordenador con cromium, desde una pestaña de Chrome accederemos a la extensión Remote desktop. Pulsaremos en Compartir esta pantalla y automáticamente se genera un token temporal. Si es un terminal android el proceso es similar pero usando la app.
Nos iremos a a la aplicación Remote Desktop en nuestro PC host si la hemos instalado o en su defecto a al extension remote desktop desde google Chrome
En esta pantalla nos iremos a la opción «conectarse a otro ordenador» e introduciremos el token que nos dio el ordenador Cromium en la opcion de compartir esta pantalla.
Enseguida se intentara conectar al pc remoto.
Ahora en el Pc remoto con cromium, aparecerá una ventana con las opciones cancelar o compartir que deberemos confirmar. Si la conexión es correcta, volverá a aparecer una nueva ventana informativa y justo desde este momento podremos interactuar con el ordenador con cromium como si estuviéramos delante accediendo a todos sus recursos ( y no solo en el navegador).
Es importante destacar que si cerramos la ventana de Chrome donde activamos Remote Desktop ( o pulsamos dejar de compartir ) desde el ordenador con cromium cerraremos también la conexión compartida.
Tenga en cuenta que el uso de una extensión de escritorio remoto como «Chrome Remote Desktop» implica que la pantalla secundaria será una representación en tiempo real del escritorio del ordenador principal y requerirá una conexión estable a Internet.
Caso de querer usar una tableta o incluso un smartphone con Android como segunda pantalla
Si desea utilizar una tableta con Android como segundo monitor para su ordenador principal con Windows 11, afortunadamente mejor de los que sucede con cromium SI es posible. Para ello puede utilizar una aplicación de terceros llamada «Duet Display»., una aplicación que permite convertir su tableta Android en un segundo monitor de manera inalámbrica. A continuación, veremos cómo hacerlo:
Asegúrese de que tanto tu ordenador principal con Windows 11 como su tableta Android estén conectados a la misma red Wi-Fi.
En su ordenador principal, abra un navegador web y vaya al sitio web de Duet Display (https://www.duetdisplay.com/).
Descargue e instale la versión de Duet Display para Windows 11 en su ordenador.
Una vez instalada, ejecute Duet Display en su ordenador y asegúrese de que la opción «Wireless» esté activada.
En su tableta Android, abra la tienda de aplicaciones (Google Play Store) y busque la aplicación «Duet Display». Descárguela e instálala en tu tableta.
Abra la aplicación Duet Display en su tableta Android y toque el botón «Conectar» o «Emparejar».
La aplicación buscará automáticamente su ordenador principal en la misma red Wi-Fi. Seleccione su ordenador en la lista para establecer la conexión.
Una vez establecida la conexión, su tableta Android se convertirá en un segundo monitor inalámbrico para su ordenador principal. Puede mover ventanas y arrastrar elementos de un monitor a otro.
Duet Display también permite ajustar la configuración de la pantalla, como la resolución y la orientación, desde la aplicación en su ordenador principal. Es importante tener en cuenta que Duet Display es una aplicación de pago, pero ofrece una versión de prueba gratuita que le permite evaluar su funcionamiento antes de comprarla. Otras opción es la aplicación gratuita llamada «SpaceDesk» que puede utilizar para convertir su tableta Android en un segundo monitor de forma inalámbrica. A continuación, explicamos cómo hacerlo:
Asegúrese de que tanto su ordenador principal con Windows 11 como su tableta Android estén conectados a la misma red Wi-Fi.
En su ordenador principal, abra un navegador web y vaya al sitio web de SpaceDesk (https://www.spacedesk.net/).
Descargue e instala la versión de SpaceDesk para Windows 11 en su ordenador.
Una vez instalada, ejecute SpaceDesk en su ordenador y asegúrese de que la opción «Enable WiFi» esté activada.
En su tableta Android, abra la tienda de aplicaciones (Google Play Store) y busque la aplicación «SpaceDesk (remote display)». Descárguela e instálala en su tableta Android.
Abra la aplicación SpaceDesk en tu tableta Android y toque el botón «Connect to a Spacedesk Viewer» (Conectar a un visualizador de SpaceDesk).
La aplicación buscará automáticamente su ordenador principal en la misma red Wi-Fi. Seleccione su ordenador en la lista para establecer la conexión.
Una vez establecida la conexión, su tableta Android se convertirá en un segundo monitor inalámbrico para su ordenador principal. Puede mover ventanas y arrastrar elementos de un monitor a otro.
SpaceDesk también permite ajustar la configuración de la pantalla, como la resolución y la orientación, desde la aplicación en tu ordenador principal.A diferencia de Duet Display, SpaceDesk es una aplicación gratuita que ofrece funcionalidad similar para convertir su tableta Android en un segundo monitor.
Dado el auge de los medidores de electricidad inteligentes y la amplia adopción de tecnología de generación de electricidad como los paneles solares, hay una gran cantidad de datos disponibles sobre el uso de electricidad.
Estos datos representan una serie temporal multivariante de variables relacionadas con la energía que, a su vez, podrían usarse para modelar e incluso pronosticar el consumo futuro de electricidad.
Los modelos de autocorrelación son muy simples y pueden proporcionar una forma rápida y efectiva de hacer pronósticos hábiles de uno o varios pasos para el consumo de electricidad.
Descripción del problema
El conjunto de datos de ‘ Consumo de energía del hogar ‘ es un conjunto de datos de series de tiempo multivariable que describe el consumo de electricidad de un solo hogar durante cuatro años.
Los datos se recopilaron entre diciembre de 2006 y noviembre de 2010 y cada minuto se recopilaron observaciones del consumo de energía dentro del hogar.
Es una serie multivariada compuesta por siete variables (además de la fecha y la hora); ellos son:
global_active_power : la potencia activa total consumida por el hogar (kilovatios).
global_reactive_power : La potencia reactiva total consumida por el hogar (kilovatios).
voltaje : Voltaje promedio (voltios).
global_intensity : Intensidad de corriente promedio (amperios).
sub_metering_1 : Energía activa para cocina (vatios-hora de energía activa).
sub_metering_2 : Energía activa para lavandería (vatios-hora de energía activa).
sub_metering_3 : Energía activa para sistemas de control climático (vatios-hora de energía activa).
Las energías activa y reactiva se refieren a los dos componentes de la potencia. La potencia activa se refiere a la parte de la potencia que realiza trabajo útil, como la alimentación de dispositivos eléctricos, la generación de calor, la iluminación, etc. Se mide en watts y es la potencia que se contabiliza en la facturación eléctrica.
Por otro lado, la potencia reactiva se refiere a la parte de la potencia que no realiza trabajo útil, sino que está asociada al almacenamiento y liberación de energía en los componentes inductivos y capacitivos de un sistema eléctrico. Se mide en voltiamperios reactivos (VAR) y no contribuye directamente al trabajo útil, pero es necesario para mantener la tensión y el flujo de energía en el sistema.
El factor de potencia, representado por el coseno de fi (θ), es una medida de la eficiencia con la que la energía eléctrica se utiliza en un sistema. Es el coseno del ángulo de desfase entre la corriente y la tensión en un circuito de corriente alterna. Un factor de potencia cercano a 1 indica un uso eficiente de la energía, donde la potencia activa es alta en comparación con la potencia reactiva. Un factor de potencia bajo indica que hay una cantidad significativa de potencia reactiva en relación con la potencia activa
Se puede crear una cuarta variable de submedición restando la suma de tres variables de submedición definidas de la energía activa total de la siguiente manera:
El conjunto de datos se puede descargar desde el repositorio de UCI Machine Learning como un solo archivo .zip de 20 megabytes: consumo_electricidad_hogar.zip
Descargue el conjunto de datos y descomprímalo en su directorio de trabajo actual. Ahora tendrá el archivo “ home_power_consumption.txt ” que tiene un tamaño de aproximadamente 127 megabytes y contiene todas las observaciones.
Podemos usar la función read_csv() para cargar los datos y combinar las dos primeras columnas en una única columna de fecha y hora que podemos usar como índice.
A continuación, podemos marcar todos los valores faltantes indicados con un ‘ ? ‘ carácter con un valor NaN , que es un flotante.
Esto nos permitirá trabajar con los datos como una matriz de valores de punto flotante en lugar de tipos mixtos (menos eficientes).
# mark all missing values
dataset.replace('?', nan, inplace=True)
# make dataset numeric
dataset = dataset.astype('float32')
También necesitamos completar los valores faltantes ahora que han sido marcados.
Un enfoque muy simple sería copiar la observación a la misma hora del día anterior. Podemos implementar esto en una función llamada fill_missing() que tomará la matriz NumPy de los datos y copiará los valores de hace exactamente 24 horas.
def fill_missing(values):
one_day = 60 * 24
for row in range(values.shape[0]):
for col in range(values.shape[1]):
if isnan(values[row, col]):
values[row, col] = values[row - one_day, col]
Podemos aplicar esta función directamente a los datos dentro del DataFrame.
# fill missing
fill_missing(dataset.values)
Ahora podemos crear una nueva columna que contenga el resto de la submedición, utilizando el cálculo de la sección anterior.
Ahora podemos guardar la versión limpia del conjunto de datos en un nuevo archivo; en este caso, simplemente cambiaremos la extensión del archivo a .csv y guardaremos el conjunto de datos como ‘ home_power_consumption.csv ‘.
# save updated dataset dataset.to_csv(‘household_power_consumption.csv’)
Uniendo todo esto, el ejemplo completo de cargar, limpiar y guardar el conjunto de datos se enumera a continuación.
# load and clean-up data
from numpy import nan
from numpy import isnan
from pandas import read_csv
from pandas import to_numeric
# fill missing values with a value at the same time one day ago
def fill_missing(values):
one_day = 60 * 24
for row in range(values.shape[0]):
for col in range(values.shape[1]):
if isnan(values[row, col]):
values[row, col] = values[row - one_day, col]
# load all data
dataset = read_csv('household_power_consumption.txt', sep=';', header=0, low_memory=False, infer_datetime_format=True, parse_dates={'datetime':[0,1]}, index_col=['datetime'])
# mark all missing values
dataset.replace('?', nan, inplace=True)
# make dataset numeric
dataset = dataset.astype('float32')
# fill missing
fill_missing(dataset.values)
# add a column for for the remainder of sub metering
values = dataset.values
dataset['sub_metering_4'] = (values[:,0] * 1000 / 60) - (values[:,4] + values[:,5] + values[:,6])
# save updated dataset
dataset.to_csv('household_power_consumption.csv')
Al ejecutar el ejemplo, se crea el nuevo archivo » home_power_consumption.csv » que podemos usar como punto de partida para nuestro proyecto de modelado.
Evaluación del modelo
Encuadre del problema
Hay muchas maneras de aprovechar y explorar el conjunto de datos de consumo de energía del hogar.En este enfoque, usaremos los datos para explorar una pregunta muy específica; eso es: Dado el consumo de energía reciente, ¿cuál es el consumo de energía esperado para la próxima semana? Esto requiere que un modelo predictivo pronostique la potencia activa total para cada día durante los próximos siete días.
Técnicamente, este encuadre del problema se conoce como un problema de pronóstico de serie de tiempo de múltiples pasos, dados los múltiples pasos de pronóstico. Un modelo que hace uso de múltiples variables de entrada puede denominarse modelo de pronóstico de serie de tiempo multivariante de múltiples pasos.
Un modelo de este tipo podría ser útil dentro del hogar en la planificación de gastos. También podría ser útil desde el punto de vista de la oferta para planificar la demanda de electricidad de un hogar específico.
Este marco del conjunto de datos también sugiere que sería útil reducir la muestra de las observaciones por minuto del consumo de energía a los totales diarios. Esto no es obligatorio, pero tiene sentido, dado que estamos interesados en la potencia total por día.
Podemos lograr esto fácilmente usando la función resample() en pandas DataFrame. Llamar a esta función con el argumento ‘ D ‘ permite que los datos cargados indexados por fecha y hora se agrupen por día ( ver todos los alias de compensación ). Luego podemos calcular la suma de todas las observaciones para cada día y crear un nuevo conjunto de datos de consumo de energía diario para cada una de las ocho variables.
El ejemplo completo se muestra a continuación.
from pandas import read_csv
# load the new file
dataset = read_csv('household_power_consumption.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime'])
# resample data to daily
daily_groups = dataset.resample('D')
daily_data = daily_groups.sum()
# summarize
print(daily_data.shape)
print(daily_data.head())
# save
daily_data.to_csv('household_power_consumption_days.csv')
Al ejecutar el ejemplo, se crea un nuevo conjunto de datos de consumo de energía total diario y se guarda el resultado en un archivo separado llamado » home_power_conquisition_days.csv «.
Podemos usar esto como el conjunto de datos para ajustar y evaluar modelos predictivos para el marco elegido del problema.
Métrica de evaluación
Un pronóstico estará compuesto por siete valores, uno para cada día de la semana siguiente. Es común con los problemas de pronóstico de varios pasos evaluar cada paso de tiempo pronosticado por separado. Esto es útil por varias razones:
Para comentar sobre la aptitud en un plazo de entrega específico (p. ej., +1 día frente a +3 días).
Para contrastar modelos en función de sus habilidades en diferentes plazos de entrega (por ejemplo, modelos buenos en +1 día frente a modelos buenos en días +5).
Las unidades de la potencia total son los kilovatios y sería útil tener una métrica de error que también estuviera en las mismas unidades. Tanto el error cuadrático medio (RMSE) como el error absoluto medio (MAE) se ajustan a esta factura, aunque RMSE se usa más comúnmente y se adoptará en este tutorial. A diferencia de MAE, RMSE castiga más los errores de pronóstico.
La métrica de rendimiento para este problema será el RMSE para cada tiempo de entrega desde el día 1 hasta el día 7.
Como atajo, puede ser útil resumir el rendimiento de un modelo utilizando una puntuación única para ayudar en la selección del modelo.
Una puntuación posible que podría usarse sería el RMSE en todos los días de pronóstico.
La función Evaluation_forecasts() a continuación implementará este comportamiento y devolverá el rendimiento de un modelo basado en múltiples pronósticos de siete días.
def evaluate_forecasts(actual, predicted):
scores = list()
# calculate an RMSE score for each day
for i in range(actual.shape[1]):
# calculate mse
mse = mean_squared_error(actual[:, i], predicted[:, i])
# calculate rmse
rmse = sqrt(mse)
# store
scores.append(rmse)
# calculate overall RMSE
s = 0
for row in range(actual.shape[0]):
for col in range(actual.shape[1]):
s += (actual[row, col] - predicted[row, col])**2
score = sqrt(s / (actual.shape[0] * actual.shape[1]))
return score, scores
Ejecutar la función primero devolverá el RMSE general independientemente del día, luego una matriz de puntajes de RMSE para cada día.
Conjuntos de entrenamiento y prueba
Usaremos los primeros tres años de datos para entrenar modelos predictivos y el último año para evaluar modelos.
Los datos de un conjunto de datos determinado se dividirán en semanas estándar. Son semanas que comienzan en domingo y terminan en sábado.
Esta es una forma realista y útil de usar el encuadre elegido del modelo, donde se puede predecir el consumo de energía para la próxima semana. También es útil con el modelado, donde los modelos se pueden usar para predecir un día específico (por ejemplo, el miércoles) o la secuencia completa.
Dividiremos los datos en semanas estándar, trabajando hacia atrás desde el conjunto de datos de prueba.
El último año de los datos es 2010 y el primer domingo de 2010 fue el 3 de enero. Los datos terminan a mediados de noviembre de 2010 y el último sábado más cercano en los datos es el 20 de noviembre. Esto da 46 semanas de datos de prueba.
La primera y la última fila de datos diarios para el conjunto de datos de prueba se proporcionan a continuación para su confirmación
El primer domingo en el conjunto de datos es el 17 de diciembre, que es la segunda fila de datos. La organización de los datos en semanas estándar proporciona 159 semanas estándar completas para entrenar un modelo predictivo. La función split_dataset() a continuación divide los datos diarios en conjuntos de entrenamiento y prueba y organiza cada uno en semanas estándar.
Se utilizan compensaciones de fila específicas para dividir los datos utilizando el conocimiento del conjunto de datos. Luego, los conjuntos de datos divididos se organizan en datos semanales mediante la función NumPy split()
# split a univariate dataset into train/test sets
def split_dataset(data):
# split into standard weeks
train, test = data[1:-328], data[-328:-6]
# restructure into windows of weekly data
train = array(split(train, len(train)/7))
test = array(split(test, len(test)/7))
return train, test
Podemos probar esta función cargando el conjunto de datos diario e imprimiendo la primera y la última fila de datos tanto del tren como de los conjuntos de prueba para confirmar que cumplen con las expectativas anteriores
El ejemplo de código completo se muestra a continuación.
# split into standard weeks
from numpy import split
from numpy import array
from pandas import read_csv
# split a univariate dataset into train/test sets
def split_dataset(data):
# split into standard weeks
train, test = data[1:-328], data[-328:-6]
# restructure into windows of weekly data
train = array(split(train, len(train)/7))
test = array(split(test, len(test)/7))
return train, test
# load the new file
dataset = read_csv('household_power_consumption_days.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime'])
train, test = split_dataset(dataset.values)
# validate train data
print(train.shape)
print(train[0, 0, 0], train[-1, -1, 0])
# validate test
print(test.shape)
print(test[0, 0, 0], test[-1, -1, 0])
Ejecutar el ejemplo muestra que, de hecho, el conjunto de datos del tren tiene 159 semanas de datos, mientras que el conjunto de datos de prueba tiene 46 semanas.
Podemos ver que la potencia activa total para el tren y el conjunto de datos de prueba para la primera y la última fila coinciden con los datos de las fechas específicas que definimos como los límites de las semanas estándar para cada conjunto
Los modelos se evaluarán utilizando un esquema llamado validación de avance .
Aquí es donde se requiere que un modelo haga una predicción de una semana, luego los datos reales de esa semana se ponen a disposición del modelo para que pueda usarse como base para hacer una predicción en la semana siguiente. Esto es tanto realista en cuanto a cómo se puede usar el modelo en la práctica como beneficioso para los modelos, permitiéndoles hacer uso de los mejores datos disponibles.
Podemos demostrar esto a continuación con la separación de los datos de entrada y los datos de salida/predichos.
El enfoque de validación de avance para evaluar modelos predictivos en este conjunto de datos se implementa a continuación y se llama evaluar_modelo() .
El nombre de una función se proporciona para el modelo como el argumento » model_func «. Esta función es responsable de definir el modelo, ajustar el modelo a los datos de entrenamiento y hacer un pronóstico de una semana.
Los pronósticos hechos por el modelo luego se evalúan contra el conjunto de datos de prueba utilizando la función de evaluación_previsiones() previamente definida .
# evaluate a single model
def evaluate_model(model_func, train, test):
# history is a list of weekly data
history = [x for x in train]
# walk-forward validation over each week
predictions = list()
for i in range(len(test)):
# predict the week
yhat_sequence = model_func(history)
# store the predictions
predictions.append(yhat_sequence)
# get real observation and add to history for predicting the next week
history.append(test[i, :])
predictions = array(predictions)
# evaluate predictions days for each week
score, scores = evaluate_forecasts(test[:, :, 0], predictions)
return score, scores
Una vez que tenemos la evaluación de un modelo, podemos resumir el rendimiento.
La función a continuación denominada resume_scores() mostrará el rendimiento de un modelo en una sola línea para facilitar la comparación con otros modelos.
# summarize scores
def summarize_scores(name, score, scores):
s_scores = ', '.join(['%.1f' % s for s in scores])
print('%s: [%.3f] %s' % (name, score, s_scores))
Ahora tenemos todos los elementos para comenzar a evaluar modelos predictivos en el conjunto de datos.
Análisis de autocorrelación
La correlación estadística resume la fuerza de la relación entre dos variables.
Podemos suponer que la distribución de cada variable se ajusta a una distribución gaussiana (curva de campana). Si este es el caso, podemos usar el coeficiente de correlación de Pearson para resumir la correlación entre las variables.
El coeficiente de correlación de Pearson es un número entre -1 y 1 que describe una correlación negativa o positiva respectivamente. Un valor de cero indica que no hay correlación.
Podemos calcular la correlación de las observaciones de series de tiempo con observaciones con pasos de tiempo anteriores, llamados retrasos. Debido a que la correlación de las observaciones de la serie temporal se calcula con valores de la misma serie en momentos anteriores, esto se denomina correlación serial o autocorrelación.
Una gráfica de la autocorrelación de una serie de tiempo por retraso se denomina función de autocorrelación , o el acrónimo ACF. Esta gráfica a veces se denomina correlograma o gráfica de autocorrelación.
Una función de autocorrelación parcial o PACF es un resumen de la relación entre una observación en una serie de tiempo con observaciones en pasos de tiempo anteriores con las relaciones de las observaciones intermedias eliminadas.
La autocorrelación para una observación y una observación en un paso de tiempo anterior se compone tanto de la correlación directa como de las correlaciones indirectas. Estas correlaciones indirectas son una función lineal de la correlación de la observación, con observaciones en pasos de tiempo intermedios.
Son estas correlaciones indirectas las que la función de autocorrelación parcial busca eliminar. Sin entrar en matemáticas, esta es la intuición de la autocorrelación parcial.
Podemos calcular gráficos de autocorrelación y autocorrelación parcial utilizando las funciones de modelos estadísticos plot_acf() y plot_pacf() respectivamente.
Para calcular y trazar la autocorrelación, debemos convertir los datos en una serie de tiempo univariante. Específicamente, la energía total diaria observada consumida.
La función to_series() a continuación tomará los datos multivariados divididos en ventanas semanales y devolverá una sola serie temporal univariada.
def to_series(data):
# extract just the total power from each week
series = [week[:, 0] for week in data]
# flatten into a single series
series = array(series).flatten()
return series
Podemos llamar a esta función para el conjunto de datos de entrenamiento preparado.
Primero, se debe cargar el conjunto de datos de consumo de energía diario.
# load the new file
dataset = read_csv('household_power_consumption_days.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime'])
Luego, el conjunto de datos debe dividirse en conjuntos de entrenamiento y prueba con la estructura de ventana de semana estándar.
# split into train and test
train, test = split_dataset(dataset.values)
A continuación, se puede extraer una serie de tiempo univariante del consumo de energía diario del conjunto de datos de entrenamiento.
# convert training data into a series
series = to_series(train)
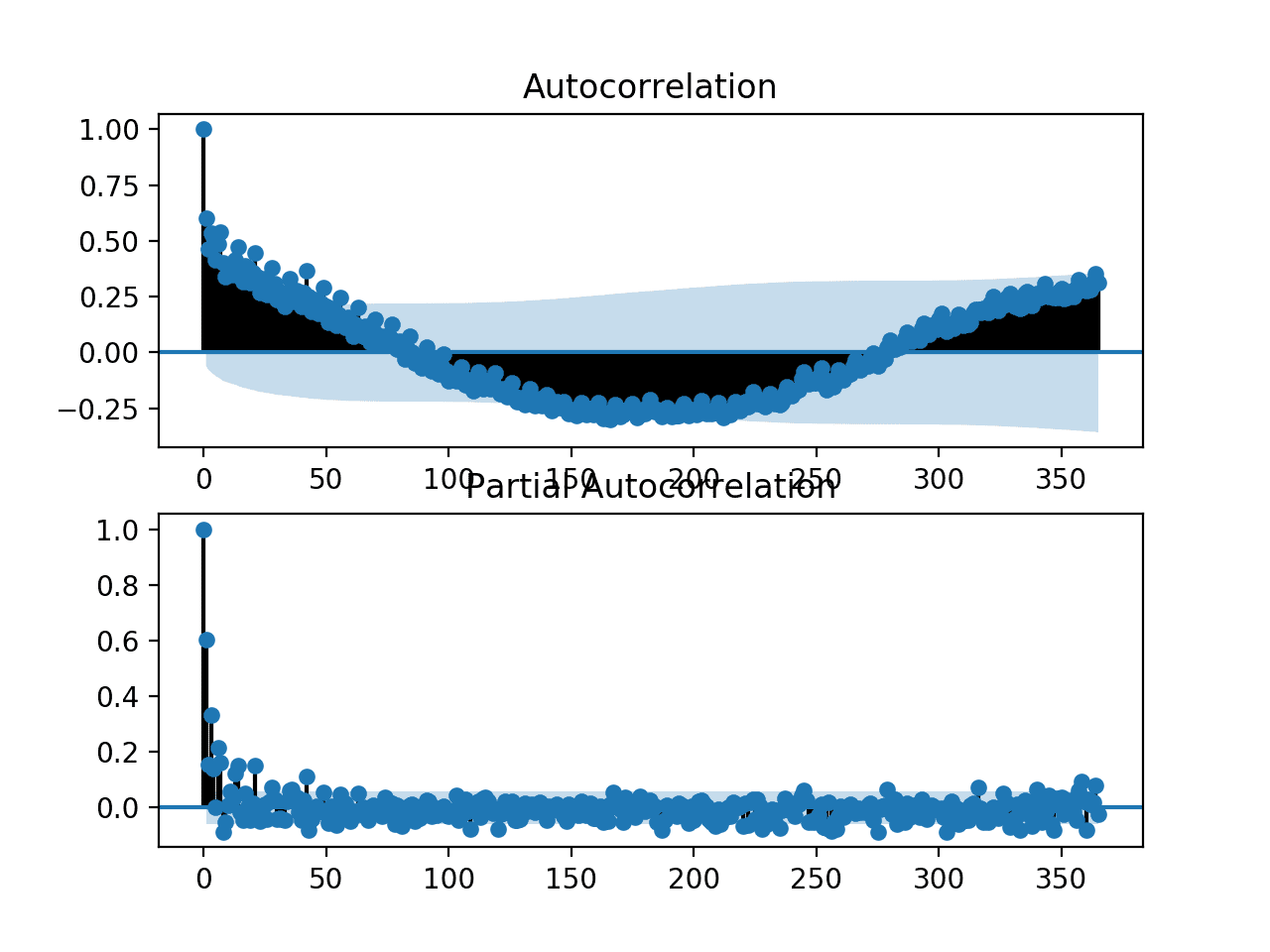
Entonces podemos crear una sola figura que contenga un gráfico ACF y PACF. Se puede especificar el número de pasos de tiempo de retraso. Arreglaremos esto para que sea un año de observaciones diarias, o 365 días.
Esperaríamos que la energía consumida mañana y la próxima semana dependa de la energía consumida en los días anteriores. Como tal, esperaríamos ver una fuerte señal de autocorrelación en los gráficos ACF y PACF.
# acf and pacf plots of total power
from numpy import split
from numpy import array
from pandas import read_csv
from matplotlib import pyplot
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf
# split a univariate dataset into train/test sets
def split_dataset(data):
# split into standard weeks
train, test = data[1:-328], data[-328:-6]
# restructure into windows of weekly data
train = array(split(train, len(train)/7))
test = array(split(test, len(test)/7))
return train, test
# convert windows of weekly multivariate data into a series of total power
def to_series(data):
# extract just the total power from each week
series = [week[:, 0] for week in data]
# flatten into a single series
series = array(series).flatten()
return series
# load the new file
dataset = read_csv('household_power_consumption_days.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime'])
# split into train and test
train, test = split_dataset(dataset.values)
# convert training data into a series
series = to_series(train)
# plots
pyplot.figure()
lags = 365
# acf
axis = pyplot.subplot(2, 1, 1)
plot_acf(series, ax=axis, lags=lags)
# pacf
axis = pyplot.subplot(2, 1, 2)
plot_pacf(series, ax=axis, lags=lags)
# show plot
pyplot.show()
Ejecutar el ejemplo crea una sola figura con gráficos ACF y PACF.
Las tramas son muy densas y difíciles de leer. Sin embargo, es posible que podamos ver un patrón de autorregresión familiar.
También podríamos ver algunas observaciones de retraso significativas dentro de un año. La investigación adicional puede sugerir un componente de autocorrelación estacional, lo que no sería un hallazgo sorprendente.
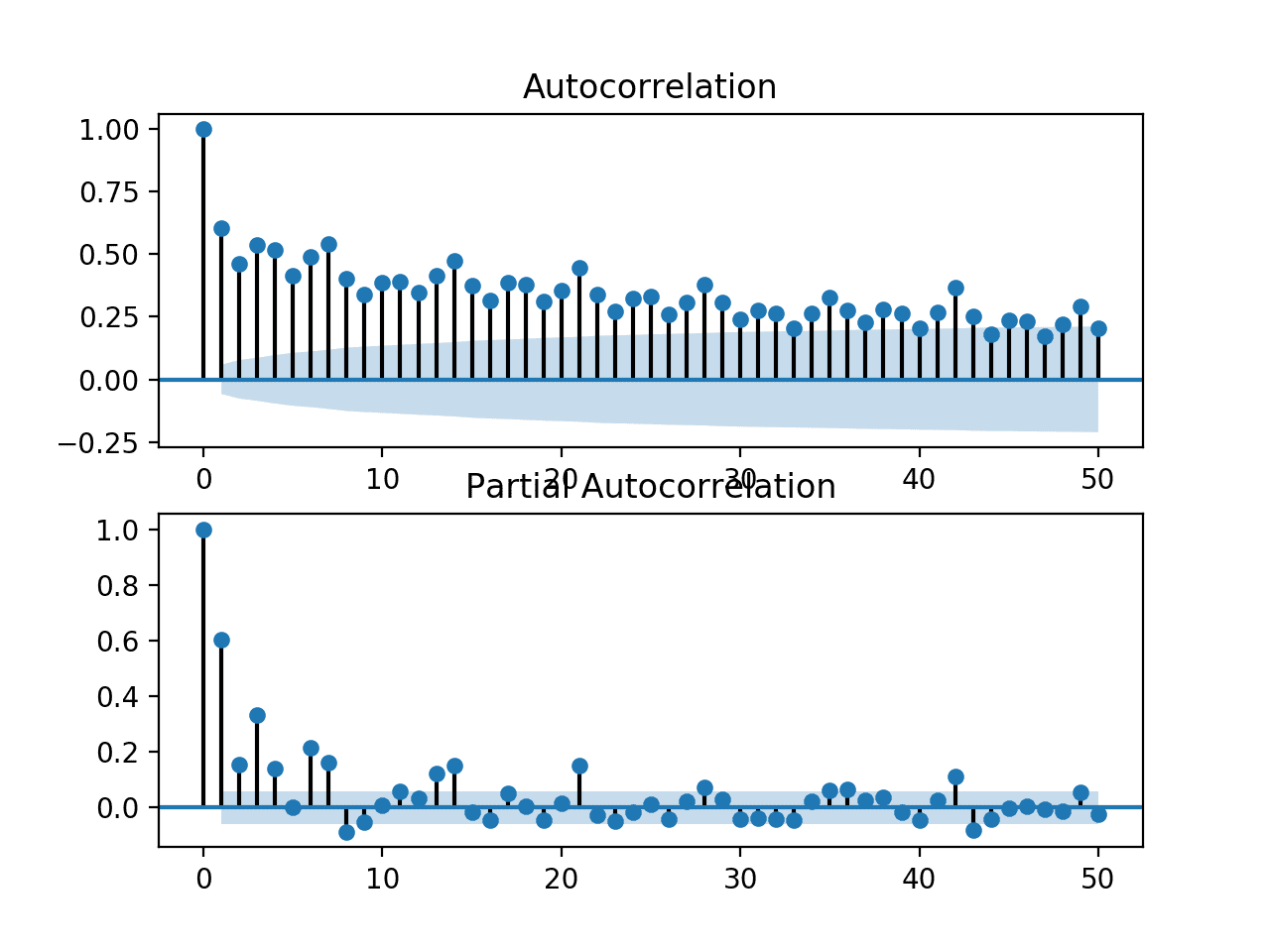
Podemos ampliar la gráfica y cambiar el número de observaciones de retraso de 365 a 50.
lags = 50
Volver a ejecutar el ejemplo de código con los resultados de este cambio es una versión ampliada de los gráficos con mucho menos desorden.
Podemos ver claramente un patrón de autorregresión familiar en las dos gráficas. Este patrón se compone de dos elementos:
ACF : una gran cantidad de observaciones de retraso significativas que se degradan lentamente a medida que aumenta el retraso.
PACF : algunas observaciones de retraso significativas que caen abruptamente a medida que aumenta el retraso.
La gráfica ACF indica que hay un fuerte componente de autocorrelación, mientras que la gráfica PACF indica que este componente es distinto para las primeras aproximadamente siete observaciones de retraso.
Esto sugiere que un buen modelo inicial sería un AR(7); que es un modelo de autorregresión con siete observaciones de retraso utilizadas como entrada.
Podemos desarrollar un modelo de autorregresión para series univariadas de consumo diario de energía.
La biblioteca de Statsmodels proporciona múltiples formas de desarrollar un modelo AR, como usar las clases AR, ARMA, ARIMA y SARIMAX.
Usaremos la implementación ARIMA ya que permite una fácil expansión en diferenciación y promedio móvil.
En primer lugar, los datos históricos compuestos por semanas de observaciones anteriores deben convertirse en una serie de tiempo univariada de consumo de energía diario. Podemos usar la función to_series() desarrollada en la sección anterior.
#convert history into a univariate series
series = to_series(history)
A continuación, se puede definir un modelo ARIMA pasando argumentos al constructor de la clase ARIMA.
Especificaremos un modelo AR(7), que en notación ARIMA es ARIMA(7,0,0).
#define the model
model = ARIMA(series, order=(7,0,0))
A continuación, el modelo se puede ajustar a los datos de entrenamiento.
#fit the model
model_fit = model.fit()
Ahora que el modelo se ha ajustado, podemos hacer una predicción.
Se puede hacer una predicción llamando a la función predict() y pasándole un intervalo de fechas o índices relativos a los datos de entrenamiento. Usaremos índices comenzando con el primer paso de tiempo más allá de los datos de entrenamiento y extendiéndolo seis días más, dando un total de un período de pronóstico de siete días más allá del conjunto de datos de entrenamiento.
Podemos envolver todo esto en una función a continuación llamada arima_forecast() que toma el historial
y devuelve un pronóstico de una semana.
arima forecast
def arima_forecast(history):
# convert history into a univariate series
series = to_series(history)
# define the model
model = ARIMA(series, order=(7,0,0))
# fit the model
model_fit = model.fit()
# make forecast
yhat = model_fit.predict(len(series), len(series)+6)
return yhat
Esta función se puede utilizar directamente en el arnés de prueba descrito anteriormente.
El ejemplo completo se muestra a continuación.
# arima forecast
from math import sqrt
from numpy import split
from numpy import array
from pandas import read_csv
from sklearn.metrics import mean_squared_error
from matplotlib import pyplot
from statsmodels.tsa.arima.model import ARIMA
# split a univariate dataset into train/test sets
def split_dataset(data):
# split into standard weeks
train, test = data[1:-328], data[-328:-6]
# restructure into windows of weekly data
train = array(split(train, len(train)/7))
test = array(split(test, len(test)/7))
return train, test
# evaluate one or more weekly forecasts against expected values
def evaluate_forecasts(actual, predicted):
scores = list()
# calculate an RMSE score for each day
for i in range(actual.shape[1]):
# calculate mse
mse = mean_squared_error(actual[:, i], predicted[:, i])
# calculate rmse
rmse = sqrt(mse)
# store
scores.append(rmse)
# calculate overall RMSE
s = 0
for row in range(actual.shape[0]):
for col in range(actual.shape[1]):
s += (actual[row, col] - predicted[row, col])**2
score = sqrt(s / (actual.shape[0] * actual.shape[1]))
return score, scores
# summarize scores
def summarize_scores(name, score, scores):
s_scores = ', '.join(['%.1f' % s for s in scores])
print('%s: [%.3f] %s' % (name, score, s_scores))
# evaluate a single model
def evaluate_model(model_func, train, test):
# history is a list of weekly data
history = [x for x in train]
# walk-forward validation over each week
predictions = list()
for i in range(len(test)):
# predict the week
yhat_sequence = model_func(history)
# store the predictions
predictions.append(yhat_sequence)
# get real observation and add to history for predicting the next week
history.append(test[i, :])
predictions = array(predictions)
# evaluate predictions days for each week
score, scores = evaluate_forecasts(test[:, :, 0], predictions)
return score, scores
# convert windows of weekly multivariate data into a series of total power
def to_series(data):
# extract just the total power from each week
series = [week[:, 0] for week in data]
# flatten into a single series
series = array(series).flatten()
return series
# arima forecast
def arima_forecast(history):
# convert history into a univariate series
series = to_series(history)
# define the model
model = ARIMA(series, order=(7,0,0))
# fit the model
model_fit = model.fit()
# make forecast
yhat = model_fit.predict(len(series), len(series)+6)
return yhat
# load the new file
dataset = read_csv('household_power_consumption_days.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime'])
# split into train and test
train, test = split_dataset(dataset.values)
# define the names and functions for the models we wish to evaluate
models = dict()
models['arima'] = arima_forecast
# evaluate each model
days = ['sun', 'mon', 'tue', 'wed', 'thr', 'fri', 'sat']
for name, func in models.items():
# evaluate and get scores
score, scores = evaluate_model(func, train, test)
# summarize scores
summarize_scores(name, score, scores)
# plot scores
pyplot.plot(days, scores, marker='o', label=name)
# show plot
pyplot.legend()
pyplot.show()
Ejecutar el ejemplo primero imprime el rendimiento del modelo AR(7) en el conjunto de datos de prueba.
Nota : Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o procedimiento de evaluación, o diferencias en la precisión numérica. Considere ejecutar el ejemplo varias veces y compare el resultado promedio.
Podemos ver que el modelo alcanza el RMSE general de alrededor de 381 kilovatios.
Este modelo tiene habilidad en comparación con los modelos de pronóstico ingenuos, como un modelo que pronostica la semana siguiente utilizando observaciones del mismo período hace un año que logró un RMSE general de aproximadamente 465 kilovatios.
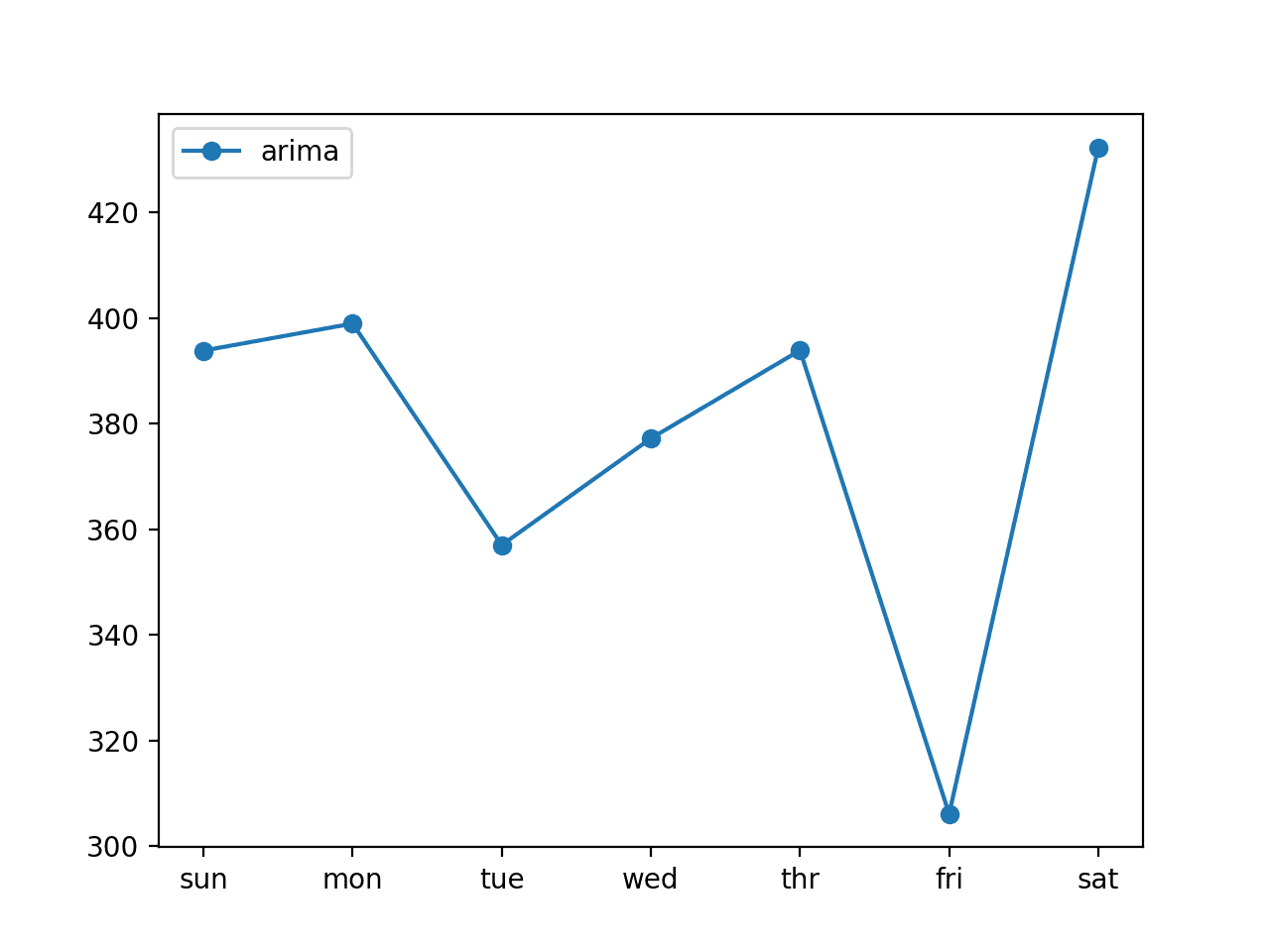
También se crea un diagrama de líneas del pronóstico, que muestra el RMSE en kilovatios para cada uno de los siete tiempos de anticipación del pronóstico.
Podemos ver un patrón interesante.
Podríamos esperar que los plazos de entrega más tempranos sean más fáciles de pronosticar que los plazos de entrega posteriores, ya que el error en cada uno de los plazos de entrega sucesivos se compone.
En cambio, vemos que el viernes (tiempo de entrega +6) es el más fácil de pronosticar y el sábado (tiempo de entrega +7) es el más difícil de pronosticar. También podemos ver que los plazos de entrega restantes tienen un error similar en el rango medio a alto de 300 kilovatios.
Extensiones
En esta sección se enumeran algunas ideas para ampliar este articulo que tal vez desee explorar.
Sintoniza ARIMA . Los parámetros del modelo ARIMA no fueron ajustados. Explore o busque un conjunto de parámetros ARIMA (q, d, p) para ver si el rendimiento se puede mejorar aún más.
Explora AR estacional . Explore si el rendimiento del modelo AR se puede mejorar al incluir elementos de autorregresión estacional. Esto puede requerir el uso de un modelo SARIMA.
Explore la preparación de datos . El modelo se ajustó directamente a los datos sin procesar. Explore si la estandarización o la normalización o incluso las transformaciones de potencia pueden mejorar aún más la habilidad del modelo AR.


Debe estar conectado para enviar un comentario.