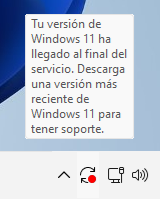
El mensaje de «Fin de servicio» en Windows 11 suele aparecer cuando tu versión de Windows ha llegado al final de su soporte y ya no recibe actualizaciones de seguridad. No es recomendable desactivarlo sin actualizar el sistema operativo, ya que eso puede poner en riesgo la seguridad de tu equipo. Desde luego lo ideal es intentar actualizarlo , aunque no siempre es posible sobre todo si el equipo no cuenta con el chip TPM.
Ciertamente el iconito con el punto rojo podemos olvidarnos pero a veces si no vamos a actualizar no gustaria ocultarlo ¿Por qué NO se puede quitar solo el mensaje? El mensaje está integrado en el sistema y no hay una opción oficial ni segura para eliminarlo. Modificar el registro o archivos del sistema para ocultarlo puede dañar Windows o bloquear futuras actualizaciones.El mensaje volverá a aparecer tras reinicios o futuras comprobaciones del sistema.Sin embargo, si comprendes los riesgos y aún así quieres ocultarlo, aquí tienes algunas opciones:
Opción 1: Usar el Editor del Registro (Regedit)
Presiona Win + R, escribe regedit y presiona Enter.
Navega a la siguiente clave: HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Microsoft\Windows\WindowsUpdate Si no existe, créala.
Dentro de esa clave, crea un nuevo valor DWORD (32 bits) con el nombre: DisableOSUpgrade Y asígnale el valor 1. También puedes probar crear esta otra clave para bloquear notificaciones específicas: HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\WindowsUpdate\UX\Settings En esa clave, crea o modifica el valor: HideMCTLink = 1 (DWORD)
Reinicia tu PC después de hacer estos cambios.
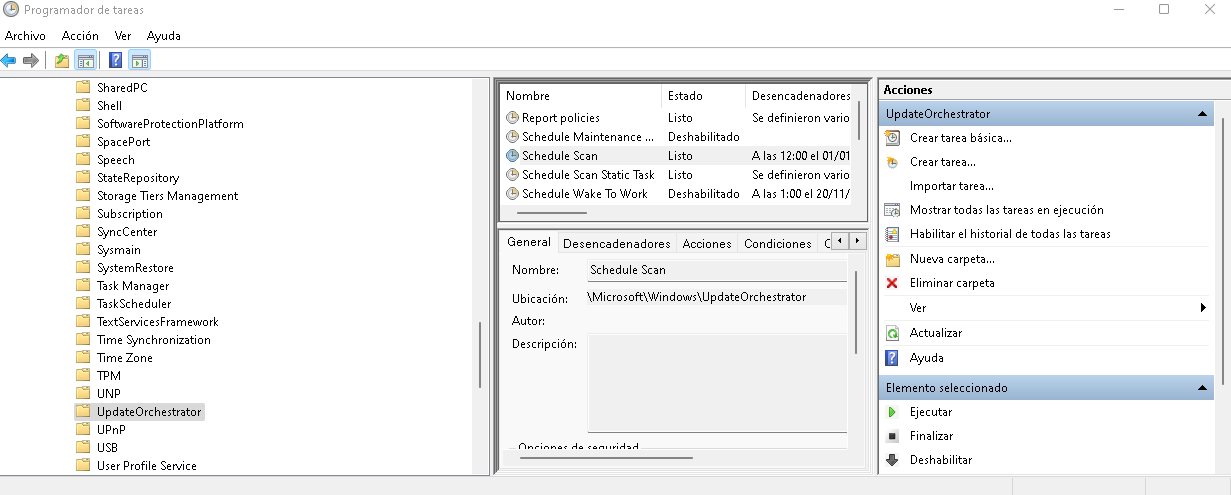
Opción 2: Usar el Programador de tareas
Abre el Programador de tareas (taskschd.msc).
Ve a: Biblioteca del Programador de tareas > Microsoft > Windows > UpdateOrchestrator
Busca tareas como:
Schedule Scan
UpdateModelTask
USO_UxBroker ← Esta puede generar notificaciones
Haz clic derecho en cada una y selecciona «Deshabilitar».
Opción 3: Desactivar notificaciones en Configuración
Esto no elimina el mensaje, pero puede ocultar su aparición:
Ve a Configuración > Sistema > Notificaciones.
Desactiva «Notificaciones de Windows Update» o «Sugerencias y trucos».
Recomendación: Si estás recibiendo este mensaje, es señal de que tu versión de Windows 11 está obsoleta. Considera actualizar a una versión más reciente (como 23H2) para mantener la seguridad y soporte.
Lo ideal, es repito actualizar por lo que veamos las alternativas para Actualizar Windows 11 Sin Formatear:
1. Actualización con el Asistente de Instalación de Windows 11
En realidad podemos transformar cualquier tableta o smartphone que no usemos en un monitor secundario y darle así una segunda vida, por ejemplo para no tener que comprar un monitor pequeño autoalimentado.
Lo mas fácil ante este tesitura y ! lo mas sencillo!, es pensar en Apps inalámbricas (WiFi/LAN, cero cables). Algunas de las mas famosas apps son las siguientes:
Spacedesk: Instala servidor en PC (Windows/Linux/Mac) y app viewer en tableta (Play Store). Conecta misma red WiFi; extiende/duplica pantalla con toque. Bajo lag (~50ms), soporta Full HD.
AirDroid Cast: Casting remoto vía WiFi/QR; duplica PC a tableta, control táctil. Gratuita básica, premium sin lag ni límites.
Splashtop Wired XDisplay (híbrida): USB para baja latencia/Full HD@60fps, sin WiFi; app gratuita en tableta y PC.
Otra opción mas elegante, ante usar una app, es el método HDMI plug-and-play (sin soldadura), es decir mediante un conector OTG conectarle una capturadora de video por hdmi. Es decir por tanto usando una capturadora HDMI USB genérica(UVC, ~10€ AliExpress/Amazon) + adaptador OTG (microUSB/USB-C). Conecta HDMI de PC → capturadora → USB tableta. Luego necesiatamos alguna app : USB Camera, nExt Camera o Next Camera (gratuita): detecta UVC auto, muestra vídeo/audio en fullscreen. Latencia <100ms, offline.
Por ultimo para evitar descargar la bateria necesitamos un Hub OTG con power passthrough para cargar simultáneo, o lo que es lo mismo un cable OTG con dos «bocas», pero ojo porque debemos entender que si es telefono o tableta ciertamente antiguo necesitaremos un adaptador OTG para mini o micro usb, o si es mas moderno un adaptador OTG para conexion USB-C , el cual por cierto no solo servirá para conectar una capturadora de video por hdmi , sino también para conectar otros periféricos como un teclado , un raton, un disco duro , etc
Existe otra tercera opcion usando con funciones nativas del propio smartphone o tableta pero estan reservadas para ciertos tipos de Samsung o DeX:
Second Screen (Galaxy Tabs): Activa en Quick Settings > «Second Screen» (Video/Gaming mode). PC presiona Win+K, selecciona tableta en WiFi directo/Miracast. Extiende sin apps extra.
Deskreen (multiplataforma): Navegador web en tableta (sin app), servidor en PC; WiFi simple para viejo Android.
Así pues, a grandes rasgos, una comparación rápida de los sistemas comentados podemos resumirlos en la siguiente tabla:
Método
Latencia
Resolución
Requisitos
Spacedesk
Baja
Full HD
Misma WiFi
HDMI UVC
Muy baja
1080p/4K
Capturadora + OTG
Second Screen
Media
Nativa
Solo Samsung
AirDroid Cast
Media
1080p
Cuenta gratuita
METODO DIRECTO: Capturadora externa
En este blog de soloelectronicos.com, exploramos las opciones más prácticas para alimentar una tableta Android reciclada que hemos convertido en monitor portátil usando una capturadora HDMI a USB, como las genéricas tipo MS2130. La forma más simple y sin modificaciones consiste en conectar directamente un cargador USB de al menos 2A, idealmente uno de 5V/2A capaz de manejar tanto la tableta como la capturadora conectada vía OTG, al puerto de carga dedicado si lo tiene. De esta manera, compensas el consumo total aproximado de 1 a 1.5 amperios que genera la capturadora procesando la señal de vídeo HDMI de tu PC, Raspberry Pi o consola, manteniendo la batería de la tableta estable sin drenaje rápido o incluso permitiendo una carga lenta continua durante el uso. Esto es perfecto para sesiones temporales o portátiles, donde no quieres complicarte con herramientas de soldadura ni riesgos innecesarios.
Si tu tableta solo tiene un puerto USB único, la solución ideal es emplear un hub OTG con carga passthrough, también conocido como Y-cable OTG más power, donde un ramal se dedica exclusivamente a la capturadora HDMI-USB y el otro ramal recibe el cargador de 5V/2A o superior, como un cargador original Samsung o un power bank confiable.
Antes de empezar, verifica en los ajustes de Android la opción específica de «Carga mientras usa accesorios USB», ubicada generalmente en Ajustes > Batería aunque varía según el modelo y versión del sistema; activarla es clave porque sin ella, aplicaciones como USB Camera o USB Camera Pro, que muestran el vídeo UVC en pantalla completa con audio, pueden consumir entre un 10% y 20% de batería por hora solo con la capturadora activa. Con esta configuración plug-and-play, la tableta detecta automáticamente la señal HDMI entrante una vez conectado el cable desde la fuente de vídeo, y en el PC o consola seleccionas modo «Extender» o «Duplicar» para usarla como monitor secundario, logrando una latencia baja inferior a 100 ms ideal para productividad o juegos casuales, todo mientras cargas la batería al 100% previamente para maximizar autonomía en sesiones largas de hasta 4-6 horas
Para usos más intensivos como 24/7 en kioscos o monitores fijos, pasamos a la modificación de bypass de batería, que requiere algo de destreza electrónica pero vale la pena si notas hinchazón o desgaste prematuro. Primero, desarma la tableta apagada y desconectada, retirando el conector de batería de 2 a 5 cables (rojo positivo, negro negativo, blanco datos posibles), luego localiza los pads de +5V en la placa base cerca del puerto USB o el regulador PMIC midiendo con multímetro para confirmar 5V estables. Suelda una fuente externa 5V directamente desde un cargador de pared o power bank a esos pads de +5V y GND, incorporando un diodo como el 1N4007 en la línea positiva para prevenir retroalimentación y un drop de voltaje de unos 0.7V; añade en paralelo un condensador electrolítico de 10-100uF a 400V junto a uno cerámico de 0.1uF para estabilizar picos de corriente y evitar reinicios inesperados. La tableta ignora por completo la batería ausente, arranca simulando un 100% fijo y opera indefinidamente enchufada, transformándola en un dispositivo robusto sin ciclos de carga que acorten su vida útil.
Como opciones avanzadas, un power bank de 10000mAh+ con PD 5V/3A ofrece 6-10 horas portátiles, o usa comandos ADB desde PC como «adb shell dumpsys battery set ac 1» para forzar modo cargando y minimizar drenaje en sleep. Siempre toma precauciones: monitorea calor extra alrededor de 40-50°C con buena ventilación, nunca excedas 5.5V en mediciones, prueba todo sin batería sobre la mesa primero y prioriza el bypass si hay signos de hinchazón para seguridad.
METODO 2 : Integrando la capturadora
El metodo anterior sin duda es interesante, pero aun es posible ir mas allá integrado la propia capturadora en el interior de la propia tableta, para lo cual una vez probado el funcionamiento de la capturadora correcto con la tableta , lo primero es busca una Ubicación física de la capturadora HDMI
Identifica un hueco libre en el interior, normalmente cerca del altavoz, que se puede reubicar si estorba.
Presenta la placa de la capturadora HDMI (la que iba en el pequeño monitor roto) para decidir la orientación que permita cerrar la carcasa y dejar el conector HDMI accesible al exterior.
Con una Dremel u otra herramienta, rebaja el plástico interno para crear un alojamiento a medida para la capturadora.
Fija la placa con pegamento termofusible (hot glue) y marca en la tapa trasera la posición exacta del conector HDMI.
Recorta en la tapa un rectángulo/ventana para el conector; ajusta hasta que el puerto HDMI quede bien accesible y la tablet pueda cerrarse casi por completo (solo sobresale un pequeño borde de PCB que luego se puede tapar con cinta o embellecedor).
Lo siguiente es preparar el esquema eléctrico y puntos de soldadura:
Extrae la placa base de la tablet y dale la vuelta para acceder a las pistas y pines del conector USB.
Toma como referencia un condensador cercano (punto de +5 V) y los pads de datos del USB (D+ y D−), además de masa (GND) desde cualquier plano o blindaje metálico del USB.
Identifica también la entrada de control del USB host switch: al llevar esa línea a masa, la tablet entra en modo host y alimenta el dispositivo USB (la capturadora).
El esquema queda así:
+5 V desde el positivo del condensador → VBUS de la capturadora.
D+ y D− de la tablet → D+ y D− de la capturadora.
GND común desde chasis/pad de masa → GND de la capturadora.
Línea “host” (control OTG) → interruptor que la conecta o no a masa.
Pasamos ahora a la soldadura y cableado:
Suelda primero el cable de +5 V en el punto del condensador y llévalo a la entrada de alimentación de la capturadora.
Suelda los dos cables de datos (D+ y D−) a sus pads correspondientes en la placa de la tablet y a la capturadora, manteniéndolos lo más cortos y paralelos posible.
Coloca el cable del pin “host” desde la pista identificada hasta un pequeño interruptor deslizante exterior; el otro terminal del interruptor va a masa, de manera que al activarlo fuerza el modo host USB.
Añade el cable de masa desde un punto de GND accesible (por ejemplo el blindaje del conector USB) hasta la capturadora.
Asegura las soldaduras con una gota de cola termofusible para evitar que se rompan por esfuerzo mecánico.
Ya solo cabe hacer el montaje final y probar el montaje:
Vuelve a colocar la placa base en su sitio, enruta los cables para que no queden pellizcados y fija el interruptor de host en un hueco del lateral o de la tapa.
Cierra la tablet con la nueva ventana HDMI ya recortada, asegurándote de que el conector queda bien accesible.
Enciende la tablet, activa el interruptor de modo host y conecta un portátil u otra fuente HDMI a la capturadora mediante un cable HDMI.
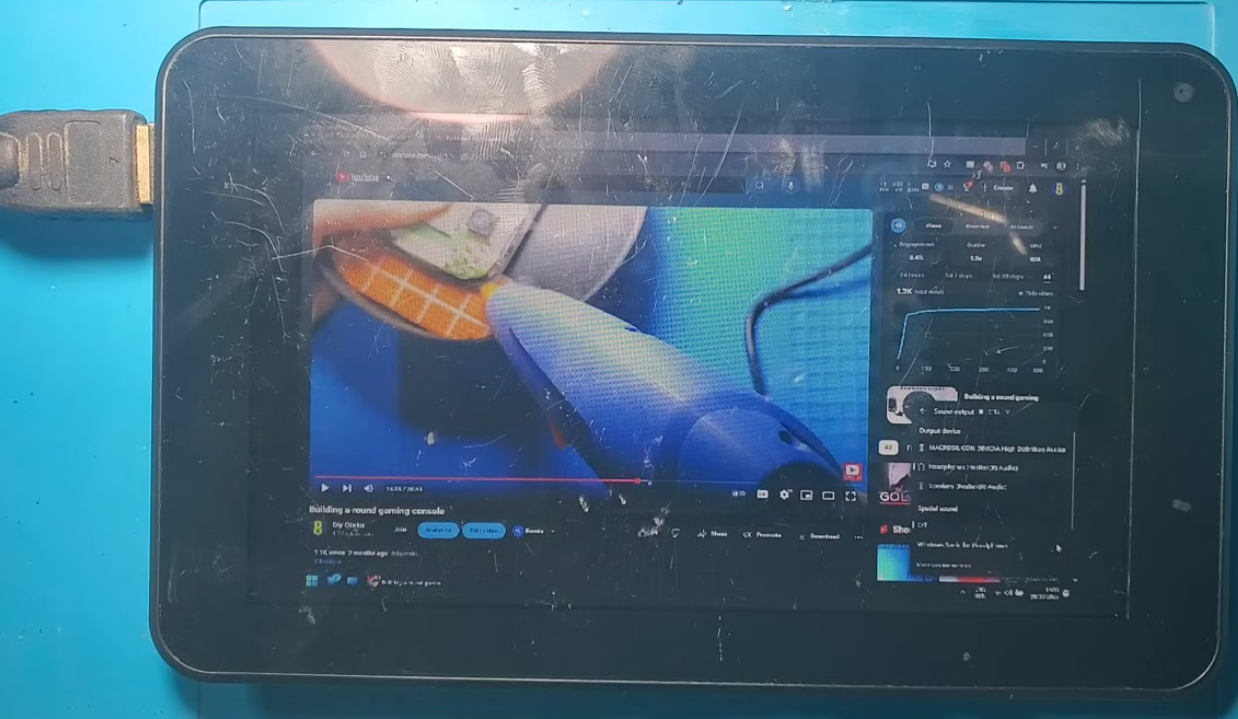
La tablet mostrará la señal de vídeo entrante y el audio saldrá por el altavoz original, obteniendo así un monitor HDMI portátil de 7″ con altavoces integrados.
Por cierto, este proceso también se puede realizar en cualquier smartphone, !eso si con un poco de paciencia por lo limitado del espacio disponible!. Amigo lector las posibilidades de dar una segunda vida a nuestros gadget que no usemos son cada vez mas amplias !aprovechémoslos!.





Debe estar conectado para enviar un comentario.