Citrix es una famosa empresa fundada en 1989 por el antiguo desarrollador de IBM Ed Iacobucci y que acogio a muchos de los fundadores originales que habían participado en el proyecto OS/2 de IBM
Es ademas una de las empresas pioneras, junto a Vmware, en virtualización de escritorios y aplicaciones . Ademas ha estado muy unida a Microsoft desde sus orígenes.
Dispone de 3 familias de productos:
- Citrix Delivery Center (XenApp, XenDesktop, XenServer y Netscaler)
- Citrix Cloud Center: Permite crear nubes híbridas con soluciones en la nube,
- Citrix Online Services: Que está unido a la aplicación GoToMeeting (herramienta videoconferencias)
Citrix XenDesktop es su producto estrella y en la versión 7 une en una suite XenApp (Aplicaciones) y XenDesktop (VDI). Los componentes básicos de un sistema de este tipo son los siguintes :
- RECEIVER : Citrix Receiver el software cliente necesario para que se puedan entregar aplicaciones o escritorios . Es un elemento multiplataforma y multidispositivo, ya que existen clientes para Windows, Linux, Mac, Android o IOS entre otros.En este post vamos a hablar precisamente de los problemas que puede dar
- STOREFRONT :se comporta, como su propio nombre indica, como una tienda online que pone a disposición de los clientes aplicaciones y escritorios. Básicamente es el frontal web que los usuarios ven y donde introducen sus credenciales. Si surgen modificaciones, se actualiza automáticamente (se puede comprobar pulsando F5 en el navegador)
- DELIVERY CONTROLLER : gestiona los accesos de los usuarios, optimiza las conexiones, hace de intermediario entre el resto de componentes y proporciona los servicios necesarios para la creación de máquinas. Debe existir al menos un DC en la infraestructura, siendo recomendado tener más de uno (redundancia), ya que marcará la capacidad de gestionar más usuarios y aplicaciones. Un DC saturado (normalmente CPU) puede provocar problemas en la plataforma y la base de datos.
- BBDD: Tradicionalmente se monta sobre SQL Server (no todos los componentes admiten SQL Express) . Existen 3 bases de datos en toda instalación XenApp / XenDesktop:
- Site: Configuración Site en ejecución y estado
- Configuration Logging: Registro de la actividad administrativa
- Monitoring: Almacena los datos de Director (inicio sesión y conexión).Sólo los DCs se conectan con la Base de Datos
- STUDIO : es la consola de administración tanto para escritorios como para aplicaciones .En Studio se pueden gestionar otros componentes como las licencias o storefront. .Adicionalmente, desde Studio se gestiona la publicación de aplicaciones y escritorios. También se gestionan las sesiones conectadas en vivo y se pueden lanzar acciones sobre ellas.
- LICENSE SERVER Componente que gestiona las licencias de los productos, al que consulta Citrix Delivery Controller para validar las sesiones . Consola web, que puede gestionarse desde Citrix Studio
- DIRECTOR : Es un componente WEB que permite monitorizar en tiempo real sesiones de Citrix. Es posible extraer informes históricos de tiempos de sesión de un grupo o usuario.
- VIRTUAL DELIVERY AGENT o VDA es el agente necesario en la infraestructura servidora o clientes de escritorio para que exista la comunicación con los Delivery Controller y poder ofrecer esos recursos (aplicaciones o VDI) a los usuarios finales. En un servidor Windows permite que varios usuarios se conecten a la vez. En un escritorio Windows permite la conexión de un solo usuario.
- ACTIVE DIRECTORY:aunque no es un componente directo en la instalación de Citrix, sí se convierte en un requisito. En directorio activo se configuran los usuarios y contraseñas que tendrán acceso. Así como las GPOs necesarias para implementar con seguridad y optimización la plataforma.
- OTROS COMPONENTES
- Netscaler: Cortafuegos, balanceo de carga, entrega de aplicaciones a través de la red y optimización de aplicaciones
- Branch Repeater: Optimiza la entrega de las aplicaciones a los usuarios ubicados en sucursales (Appliance)
- EdgeSight: Monitoriza el rendimiento de las aplicaciones (integrado en Director)
- Sharefile: Herramienta para compartir archivos de forma segura
- Citrix WEM: Gestor de directivas que sustituye ciertas funciones de Active Directory para acelerar el logon.
- Netscaler Insight Center: Dispositivo virtual para el seguimiento, análisis y generación de informes sobre aplicaciones.
- etc
Citrix Virtual Apps es un software de virtualización de aplicaciones producido por la famosa empresa Citrix Systems que permite acceder a las aplicaciones de Windows a través de dispositivos individuales desde un servidor compartido o un sistema en la nube (siendo lo mas típico en un ambiente empresarial que estas estén disponibles a través de un servicio VPN)
Dentro de esta estrategia propietarias del fabricante Citrix , los archivos con con las extensiónes .ica de Independent Computing Architectureson lo que los convierte literalmente en archivos de configuración de siendo exclusivamente utilizados precisamente por esos programas de Citrix para invocarse en remoto ayudándose precisamente de la configuración que se haya hecho en estos archivos que se descargan en local desde el portal empresarial .
Estos ficheros ,de hecho, se pueden abrir con un editor de texto ASCII para ver así su contenido, aunqu, en realidad tiene poco sentido verlos pues sólo se pueden iniciar en el otro extremo del cloud con una de las aplicaciones compatibles de Citrix.
Por tanto , precisamente mediante estos archivos ICA se lanzan las aplicaciones remotamente a utilizando Citrix XenClient , el programa Citrix XenApp o sobre todo el conocido programa Citrix Receiver.
Si tiene problemas a la hora de ejecutar algunos de estos ficheros .ica lanzados desde un ambiente corporativo o empresarial ( como por ejemplo que no se pueden abrir las aplicaciones , solo deja guardar los archivos ica ,aparece una ventana que se cierrra en blanco, etc. ), puede intentar seguir los siguientes pasos para intentar ejecutar estas aplicaciones virtualizadas:
Paso 1: Descargue el nuevo cliente de Citrix
A fecha de agosto de 2018, Citrix Workspace app es la la sustitutade Citrix Receiver. Por lo tanto la aplicación Citrix Workspace App es el nuevo cliente de Citrix que actúa de forma similar a Citrix Receiver y es totalmente retrocompatible (o al menos en eso dice el fabricante) con la infraestructura Citrix de su organización. La aplicación Citrix Workspace App proporciona las capacidades completas de Citrix Receiver, así como nuevas capacidades basadas en la implementación de Citrix de su organización razon por la que el fabricante Citrix recomienda que se descargue la aplicación Citrix Workspace.
La aplicación Citrix Workspace es el software de cliente fácil de instalar que ofrece un acceso seguro y sin inconvenientes a todo lo necesario para hacer todo lo que quiera. Con esta descarga gratuita, puede acceder de forma fácil y segura a todas las aplicaciones, escritorios y datos desde cualquier dispositivo, incluyendo teléfonos inteligentes, tabletas, PCs y Macs
.Descarga para Windows
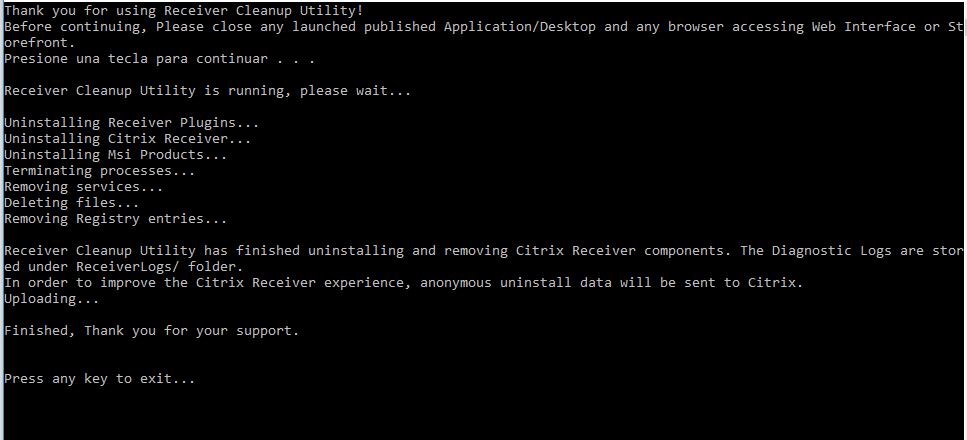
La aplicación Citrix Workspace sustituye de forma automática muchas versiones anteriores de Citrix Receiver y los complementos en línea de Citrix; sin embargo, deben eliminarse manualmente algunas versiones antes de instalar la aplicación Citrix Workspace , siendo lo mejor que se haga con la utilidad especifica. de ReceiverCleanupUtility
Paso 2: Acceso desde el VPN a la url de su organización
En al mayoria de lso casos necesitara abrir una URL adecuada en su navegador para autenticar su espacio de trabajo digital Citrix con todas sus aplicaciones, escritorios y datos. En ocasiones incluso , puede que necesite configurar su cuenta indicando su correo electrónico o una dirección de servidor para autenticar con la aplicación Workspace para usar aplicaciones y escritorios virtuales. Puede preguntar a su administrador de sistemas qué pasos seguir en su situación pues no solo necesitara esa url : tambien necesitara la instalación del cliente Citrix en la justa version que haya decidido su organizacion.
Paso 4-Fuerce la ejecución de los achivos
La aplicación Citrix Workspace App es un nuevo cliente de Citrix que actúa de forma similar a Citrix Receiver y es totalmente retrocompatible con la infraestructura Citrix de su organización proporcionando las capacidades completas de Citrix Receiver, así como nuevas capacidades basadas en la implementación de Citrix de su organización.
Una vez instalado el cliente , cuando acceda desde su portal a la apliacion virualizada , haga clic derecho en el archivo ICA para abrir el menú contextual del archivo.Luego haga clic en la opción «Abrir con» y una lista de programas se abrirá.
Desplázese y haga clic en «Citrix XenApp» o «Citrix XenClient» :el programa Citrix debería abrirse y lanzará la aplicación remota definida en el archivo ICA.
Paso 5; Instale versiones anteriores
Puede que no siempre estén al dia en su organizacion con la ultima version de Citrix en el lado servidor , por lo que deberá encontrar versiones anteriores de Receiver en el sitio web de descargas de Citrix. por lo que debería confirmar con su administrador de sistemas que necesita una versión anterior de Citrix Receiver antes de continuar.
Antes de proceder,primero debería desistalar todo el sw de Citrix con la herramientas especifica : ReceiverCleanupUtility
Una vez desistalado todo si su aplicación Citrix no le funciona con la ultima version del cliente entonces intente descargar alguna version anterior , por ejemplo Receiver 4.9 LTSR for Windows desde https://www.citrix.es/downloads/citrix-receiver/legacy-receiver-for-windows/receiver-for-windows-49LTSR.html
Instalar este cliente es bien sencillo pues basta descargarlo yen seguida ya debería comenzar el asistente de instalación
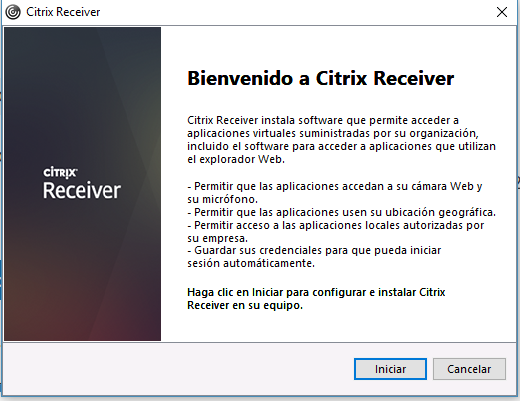
Inmediatamente simplemente le daremos al botón «Iniciar»
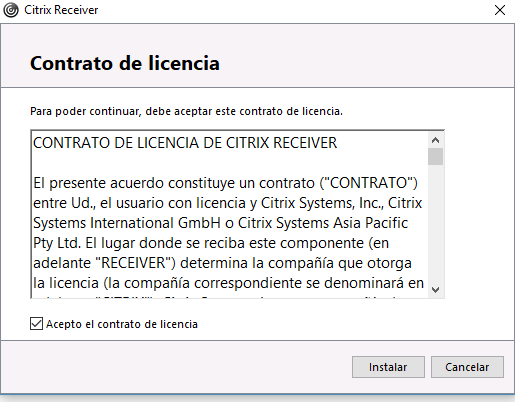
Una vez leída la licencia deberíamos darla a «Siguiente»
Finalmente aparecerá la ventana de instalación completada junto al botón de Agregar cuenta , el cual la mayoría de los casos es completamente innecesario
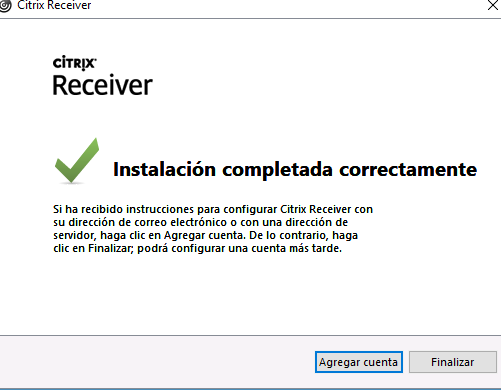
Como ve querido lector ,en el caso de tener el servicio disponible si nos falla probablemente se deba a la version del cliente Citrix que tengamos instalados. Citrix por su parte , si todo lo demas fallo , reconoce ciertos errores a los que da ademas un modo de solucionarlos en la siguiente url https://docs.citrix.com/es-es/citrix-workspace-app-for-linux/troubleshooting.html

Debe estar conectado para enviar un comentario.