Home Assistant es una plataforma de automatización del hogar de código abierto que te permite controlar y monitorear dispositivos y servicios en tu hogar. Esta diseñado para funcionar como un concentrador central para la gestión de la domótica, lo que permite integrar una variedad de dispositivos y sistemas en una única interfaz.
Algunas de las características clave de Home Assistant incluyen:
- Integración de Dispositivos: Home Assistant es compatible con una amplia gama de dispositivos y tecnologías de automatización del hogar, como luces inteligentes, termostatos, cerraduras, cámaras de seguridad, sensores, entre otros. Puede integrar dispositivos de diferentes fabricantes y protocolos.
- Automatización y Escenas: Puede crear automatizaciones personalizadas para que los dispositivos interactúen entre sí en respuesta a ciertos eventos o condiciones. También puede configurar escenas para controlar varios dispositivos con un solo comando.
- Control Remoto: Puede acceder a Home Assistant de forma remota a través de una interfaz web o utilizando aplicaciones móviles, lo que permite controlar y monitorear su hogar desde cualquier lugar.
- Soporte para Plataformas de Voz: Home Assistant es compatible con plataformas de voz como Amazon Alexa y Google Assistant, lo que permite controlar tus dispositivos usando comandos de voz.
- Personalización y Extensibilidad: La plataforma es altamente personalizable y extensible. Puede crear paneles de control personalizados, utilizar temas y agregar componentes adicionales según sus necesidades.
- Seguridad: Home Assistant ofrece características de seguridad, como la posibilidad de habilitar la autenticación de dos factores y utilizar conexiones seguras a través de HTTPS.
Home Assistant se ejecuta en una variedad de plataformas, incluyendo Raspberry Pi, servidores Linux, contenedores Docker y más siendo una opción popular para aquellos que desean tener un control centralizado sobre sus dispositivos domésticos inteligentes y desean evitar depender de plataformas propietarias. Además, al ser de código abierto, la comunidad de usuarios contribuye al desarrollo y mejora continua de la plataforma.
Instalar Home Assistant en una Raspberry Pi es una de las opciones mas populares y viablse para muchos usuarios, especialmente aquellos que están buscando una solución de automatización del hogar de bajo costo y energéticamente eficiente. Aquí hay algunas consideraciones:
- Bajo Costo: Las Raspberry Pi son dispositivos de bajo costo, lo que hace que sea accesible para una amplia gama de usuarios.
- Consumo de Energía: Las Raspberry Pi tienen un bajo consumo de energía en comparación con computadoras más grandes. Esto las hace ideales para estar siempre encendidas y actuar como un concentrador de automatización del hogar.
- Soporte Oficial: Home Assistant ofrece soporte oficial para instalar la plataforma en una Raspberry Pi, lo que facilita la configuración.
- Comunidad Activa: Dada la popularidad de las Raspberry Pi y Home Assistant, encontrarás una comunidad activa que puede proporcionar soporte y compartir experiencias.
Sin embargo, hay algunas consideraciones que debe tener en cuenta:
- Recursos Limitados: Las Raspberry Pi tienen recursos limitados en términos de potencia de procesamiento, RAM y almacenamiento. Si planea integrar muchos dispositivos o usar complejas automatizaciones, podría alcanzar los límites de rendimiento de la Raspberry Pi.
- Almacenamiento SD: Las Raspberry Pi generalmente utilizan tarjetas SD para almacenamiento. Las tarjetas SD pueden desgastarse con el tiempo debido a la escritura constante de datos, por lo que es posible que desees considerar opciones para mitigar este desgaste, como utilizar tarjetas de alta calidad o configurar la plataforma para minimizar la escritura en la tarjeta.
- Evaluación de Requisitos: Antes de decidirse por una Raspberry Pi, evalúe sus necesidades específicas. Si tiene una gran cantidad de dispositivos o si planea ejecutar aplicaciones adicionales junto con Home Assistant, podría necesitar una plataforma más potente ( por ejemplo un minipc).
En general, instalar Home Assistant en una Raspberry Pi es una excelente opción para muchos usuarios, especialmente aquellos que están comenzando con la automatización del hogar y desean una solución asequible y fácil de configurar. Sin embargo, tenga en cuenta las limitaciones de recursos y asegúrese de que se adapte a sus necesidades específicas.
Esta guía muestra cómo instalar el sistema operativo Home Assistant en su Raspberry Pi usando Raspberry Pi Imager , por línea de comando o mediante un contenedor. Si su plataforma no admite Raspberry Pi Imager también es posible porque puede utilizar Balena Etcher en su lugar (es el ultimo método que describimos al final de este post).

METODO 1:ESCRIBIR LA IMAGEN EN SU TARJETA SD.
Sin duda es el método mas sencillo de realizar porque básicamente vamos a instalar una imagen de Raspbian con todo instalado y solo tendremos que personalizar los aspectos mas generales. Estos son los pasos a seguir:
- Descargue e instale Raspberry Pi Imager en su ordenador como se describe en https://www.raspberrypi.com/software/ .
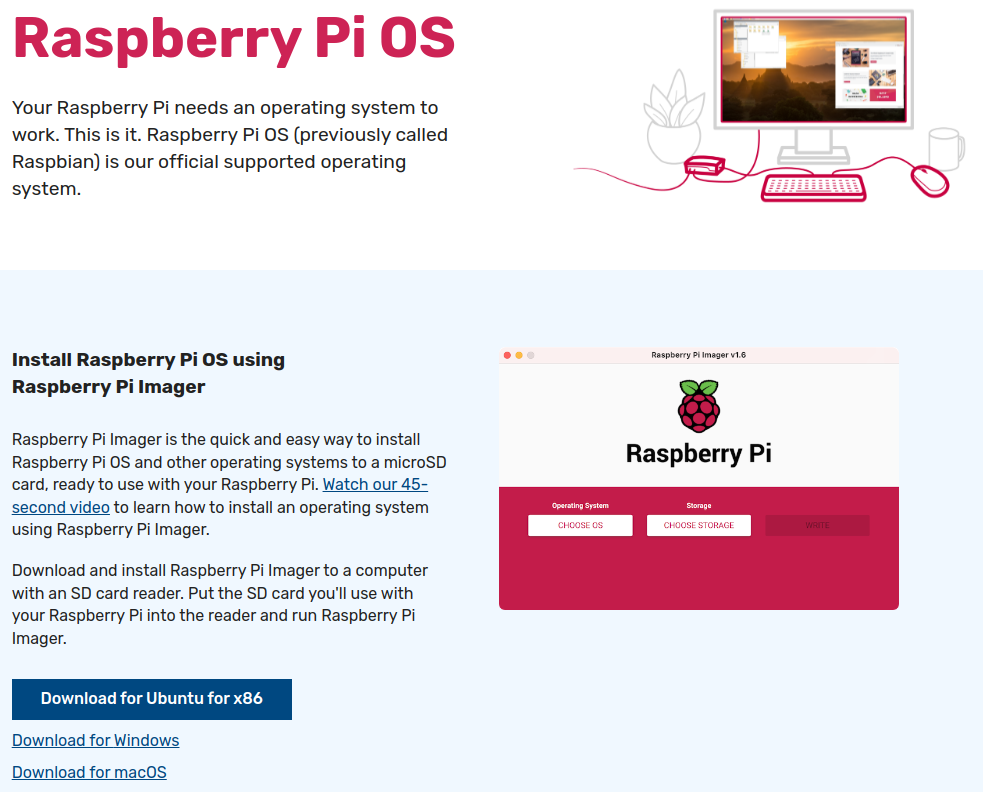
- Abra Raspberry Pi Imager y seleccione su dispositivo Raspberry Pi.
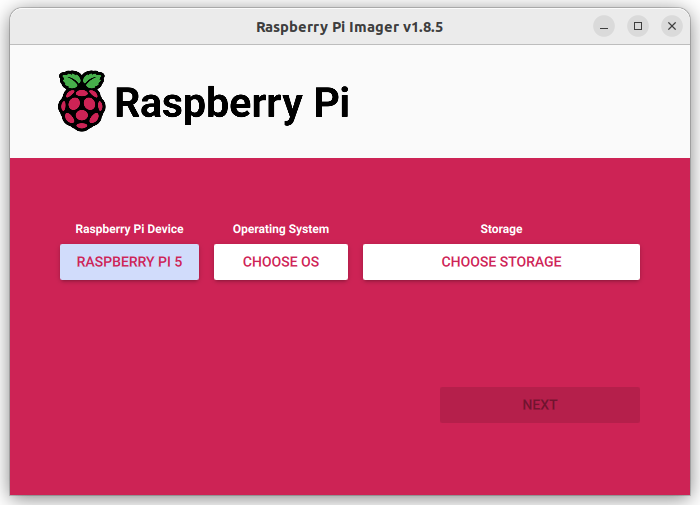
- Elija el sistema operativo:
- Seleccione Elegir sistema operativo .
- Seleccione Otro SO específico > Asistentes del hogar y domótica > Home Assistant .
- Elija el sistema operativo Home Assistant que coincida con su hardware (RPi 3 o RPi 4).
- Elija el almacenamiento:
- Inserte la tarjeta SD en la computadora. Nota: se sobrescribirá el contenido de la tarjeta.
- Selecciona tu tarjeta SD.
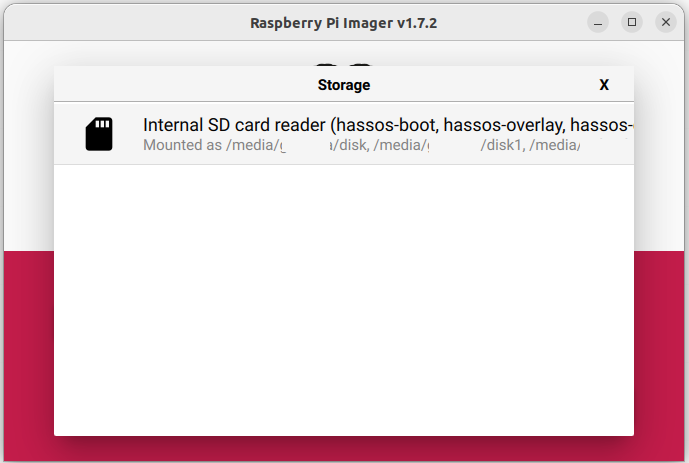
- Escriba el instalador en la tarjeta SD:
- Para iniciar el proceso, seleccione Siguiente .
- Espere a que el sistema operativo Home Assistant se escriba en la tarjeta SD.
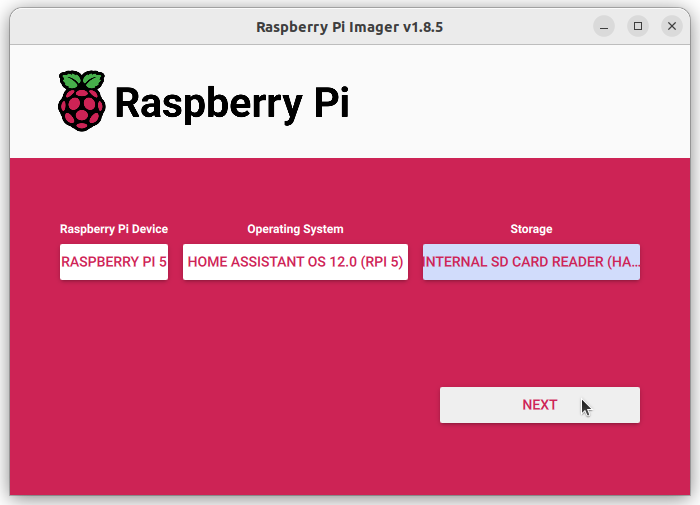
- Expulse la tarjeta SD.
INICIE SU RASPBERRY PI
- Inserte la tarjeta SD en tu Raspberry Pi.
- Conecte un cable Ethernet y asegúrese de que la Raspberry Pi esté conectada a la misma red que su computadora.
- Conecte la fuente de alimentación para iniciar el dispositivo.
ACCEDER AL ASISTENTE DE INICIO
Unos minutos después de conectar la Raspberry Pi, podrá comunicarse con su nuevo Home Assistant.
- En el navegador de su sistema de escritorio, ingrese homeassistant.local:8123 .Si está ejecutando una versión anterior de Windows o tiene una configuración de red más estricta, es posible que necesite acceder a Home Assistant en homeassistant:8123 o `http://XXXX:8123` (reemplace XXXX con la dirección IP de su Raspberry Pi).
- El tiempo que tarda esta página en estar disponible depende de su hardware. En una Raspberry Pi 4, esta página debería estar disponible en un minuto.
- Si no aparece después de 5 minutos en un Pi 4, tal vez la imagen no se escribió correctamente.
- Intente actualizar la tarjeta SD nuevamente, posiblemente incluso pruebe con una tarjeta SD diferente.
- Si esto no ayuda, vea la salida de la consola en Raspberry Pi.
- Para hacer esto, conecte un monitor a través de HDMI.
- Si no aparece después de 5 minutos en un Pi 4, tal vez la imagen no se escribió correctamente.
¡Felicidades! ¡Terminaste la configuración de Raspberry Pi!
METODO 2:Instalar el núcleo de Home Assistant con linea de comandos
Este es un proceso de instalación avanzado y algunos pasos pueden diferir en su sistema. Teniendo en cuenta la naturaleza de este tipo de instalación, asumimos que puede manejar diferencias sutiles entre este documento y la configuración del sistema que está utilizando. En caso de duda, considere uno de los otros métodos de instalación , ya que podrían ser más adecuados.
Requisitos previos
Esta guía asume que ya tiene un sistema operativo configurado y ha instalado Python 3.11 (incluido el paquete python3-dev) o una versión más reciente.
Para instalar Python 3.11 en su Raspberry Pi, hay varias formas de hacerlo. Aquí hay una forma de hacerlo:
- Abra la terminal en su Raspberry Pi.
- Escriba el siguiente comando en la terminal:
sudo apt-get update - Escriba el siguiente comando en la terminal:
sudo apt-get install software-properties-common - Escriba el siguiente comando en la terminal:
sudo add-apt-repository ppa:deadsnakes/ppa - Escriba el siguiente comando en la terminal:
sudo apt-get update - Escriba el siguiente comando en la terminal:
sudo apt-get install python3.11
Esto debería instalar Python 3.11 en su Raspberry Pi. Si tiene algún problema, asegúrese de que su Raspberry Pi esté conectada a Internet y que los comandos se hayan escrito correctamente.
También puede descargar Python 3.11 desde el sitio web oficial de Python y compilarlo desde la fuente. Sin embargo, esta es una opción más avanzada y no se recomienda para principiantes.
INSTALAR DEPENDENCIAS
Antes de comenzar, asegúrese de que su sistema esté completamente actualizado, todos los paquetes de esta guía están instalados con apt, si su sistema operativo no lo tiene, busque alternativas.
sudo apt-get update
sudo apt-get upgrade -yInstale las dependencias:
sudo apt-get install -y python3 python3-dev python3-venv python3-pip bluez libffi-dev libssl-dev libjpeg-dev zlib1g-dev autoconf build-essential libopenjp2-7 libtiff6 libturbojpeg0-dev tzdata ffmpeg liblapack3 liblapack-dev libatlas-base-devLas dependencias mencionadas anteriormente pueden diferir o faltar, según su sistema o el uso personal de Home Assistant.
CREAR UNA CUENTA
Agregue una cuenta para Home Assistant Core llamada homeassistant. Dado que esta cuenta es solo para ejecutar Home Assistant Core, se agregan argumentos adicionales -rm para crear una cuenta del sistema y crear un directorio de inicio. Los argumentos -G dialout,gpio,i2cagregan al usuario al dialouty gpioal i2cgrupo. El primero es necesario para utilizar controladores Z-Wave y Zigbee, mientras que el segundo es necesario para comunicarse con GPIO.
sudo useradd -rm homeassistant -G dialout,gpio,i2cCREAR EL ENTORNO VIRTUAL
Primero crearemos un directorio para la instalación de Home Assistant Core y cambiaremos el propietario de la homeassistantcuenta.
sudo mkdir /srv/homeassistant
sudo chown homeassistant:homeassistant /srv/homeassistantEl siguiente paso es crear y cambiar a un entorno virtual para Home Assistant Core. Esto se hará con la cuenta homeassistant.
sudo -u homeassistant -H -s
cd /srv/homeassistant
python3 -m venv .
source bin/activateUna vez que haya activado el entorno virtual (observe que el mensaje cambia a (homeassistant) homeassistant@raspberrypi:/srv/homeassistant $), deberá ejecutar el siguiente comando para instalar un paquete de Python requerido.
python3 -m pip install wheelUna vez que haya instalado el paquete Python requerido, ¡es el momento de instalar Home Assistant Core!
pip3 install homeassistant==2023.11.3Inicie Home Assistant Core por primera vez. Esto completará la instalación por usted, creará automáticamente el .homeassistantdirectorio de configuración en el /home/homeassistantdirectorio e instalará las dependencias básicas.
hassAhora puede acceder a su instalación a través de la interfaz web en http://homeassistant.local:8123.
Si esta dirección no funciona, también puede probar http://localhost:8123o http://X.X.X.X:8123(reemplace XXXX con la dirección IP de su máquina).
Cuando ejecute el comando hass por primera vez, descargará, instalará y almacenará en caché las bibliotecas/dependencias necesarias. Este procedimiento puede tardar entre 5 y 10 minutos. Durante ese tiempo, es posible que reciba un error de «no se puede acceder al sitio» al acceder a la interfaz web. Esto sólo sucederá la primera vez. Los reinicios posteriores serán mucho más rápidos.
SSH remoto
Ciertamente todos los comandos comentados lo podemos ejecutar r desde la consola de Raspberry pi con un teclado, monitor y ratón , pero seguramente desde un ordenador convencional será mucho mas fácil, para ello desde W11, puede usar SSH. Hay varias formas de hacerlo, pero aquí hay una forma de hacerlo:
- Asegúrese de que su Raspberry Pi esté conectada a la misma red que su computadora.
- Abra PowerShell en su computadora presionando
Ctrl + Shift + P. - Escriba el siguiente comando en PowerShell:
ssh [nombre de usuario]@[dirección IP de Raspberry Pi]. - Reemplace
[nombre de usuario]con el nombre de usuario de su Raspberry Pi y[dirección IP de Raspberry Pi]con la dirección IP de su Raspberry Pi. - Presione Enter y escriba la contraseña de su Raspberry Pi cuando se le solicite.
Si no ha habilitado SSH en su Raspberry Pi, deberá hacerlo primero.
Recuerde por cierto que para obtener la dirección IP de su Raspberry puede usar el comando ifconfig.
METODO 3:INSTALACIÓN CON DOCKER
Este método rivaliza con el método inicial pues la instalación con Docker es sencilla. Estos son los pasos a realizar:
En primer lugar ajuste el siguiente comando para que:
/PATH_TO_YOUR_CONFIGapunta a la carpeta donde desea almacenar su configuración y ejecutarla. Asegúrate de conservar la:/configpieza.MY_TIME_ZONEes un nombre de base de datos tz , comoTZ=America/Los_Angeles.- D-Bus es opcional pero necesario si planea utilizar la integración Bluetooth
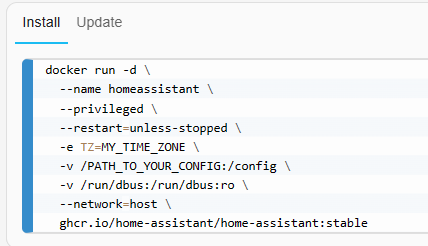
Una vez que el contenedor de Home Assistant se esté ejecutando, se debería poder acceder a Home Assistant usando http://<host>:8123(reemplazar con el nombre de host o IP del sistema). Puede continuar con la incorporación.
REINICIAR EL ASISTENTE DE INICIO
Si cambia la configuración, debe reiniciar el servidor. Para hacerlo tienes 3 opciones.
- En la interfaz de usuario de Home Assistant, vaya a Configuración > Sistema y haga clic en el botón Reiniciar .
- Puede ir a Herramientas de desarrollador > Servicios , seleccionar el servicio
homeassistant.restarty seleccionar Llamar al servicio . - Reinícielo desde una terminal.
DOCKER COMPOSER
docker composeya debería estar instalado en su sistema. De lo contrario, puede instalarlo manualmente .
A medida que el comando Docker se vuelve más complejo, docker composepuede ser preferible cambiar a y admitir el reinicio automático en caso de falla o reinicio del sistema. Cree un archivo compose.yml:
version: '3'
services:
homeassistant:
container_name: homeassistant
image: "ghcr.io/home-assistant/home-assistant:stable"
volumes:
- /PATH_TO_YOUR_CONFIG:/config
- /etc/localtime:/etc/localtime:ro
- /run/dbus:/run/dbus:ro
restart: unless-stopped
privileged: true
network_mode: hostInícielo ejecutando:
docker compose up -dUna vez que el contenedor Home Assistant se esté ejecutando, se debería poder acceder a Home Assistant usando http://<host>:8123(reemplazar con el nombre de host o IP del sistema). Puede continuar con la incorporación.
DISPOSITIVOS DE EXPOSICIÓN
Para utilizar Zigbee u otras integraciones que requieran acceso a dispositivos, debe asignar el dispositivo apropiado al contenedor. Asegúrese de que el usuario que ejecuta el contenedor tenga los privilegios correctos para acceder al /dev/tty*archivo, luego agregue la asignación del dispositivo a las instrucciones de su contenedor:CLI de ventana acoplableComposición acoplable
docker run ... --device /dev/ttyUSB0:/dev/ttyUSB0 ...OPTIMIZACIONES
Home Assistant Container utiliza una biblioteca de asignación de memoria alternativa, jemalloc, para una mejor administración de la memoria y acelerar el tiempo de ejecución de Python.
Como jemalloc puede causar problemas en cierto hardware, se puede desactivar pasando la variable de entorno DISABLE_JEMALLOCcon cualquier valor, por ejemplo:
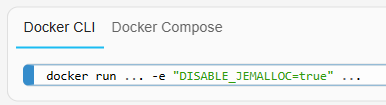
El mensaje de error <jemalloc>: Unsupported system page sizees un indicador conocido.
METODO 4:Escribiendo la imagen con Balena Etcher
Por ultimo ,utilice este procedimiento si su plataforma no admite Raspberry Pi Imager.
- Inserte la tarjeta SD en la computadora. Nota: se sobrescribirá el contenido de la tarjeta.
- Descargue e inicie Balena Etcher . Es posible que necesite ejecutarlo con privilegios de administrador en Windows.
- Descargue la imagen a su ordenador.
- Copie la URL correcta para Raspberry Pi 3 o 4 (Nota: ¡hay 2 enlaces diferentes a continuación!):
https://github.com/home-assistant/operating-system/releases/download/11.1/haos_rpi4-64-11.1.img.xz
Seleccione y copie la URL o use el botón «copiar» que aparece cuando pasa el cursor sobre ella.
- Pegue la URL en tu navegador para iniciar la descarga.
- Seleccione Flash del archivo y seleccione la imagen que acaba de descargar.
- Flash desde URL no funciona en algunos sistemas.
6. Seleccione el objetivo
7. Seleccione la tarjeta SD que desea utilizar para su instalación. 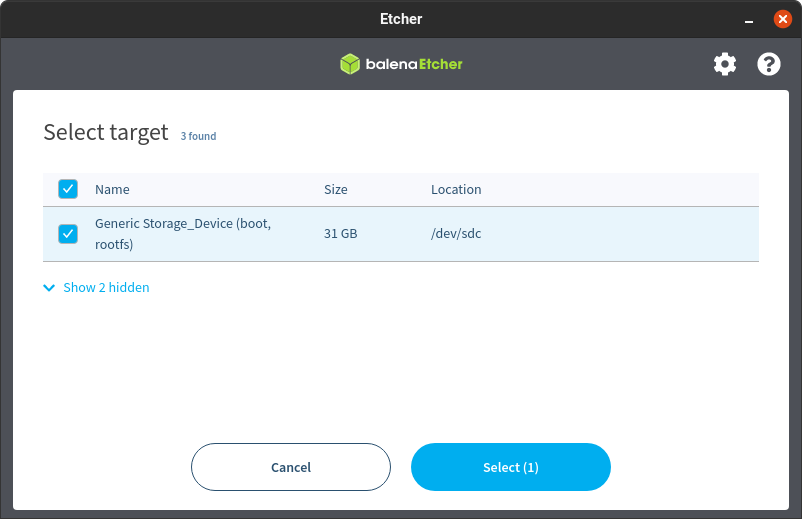
8. Seleccione ¡Flash! para empezar a escribir la imagen. 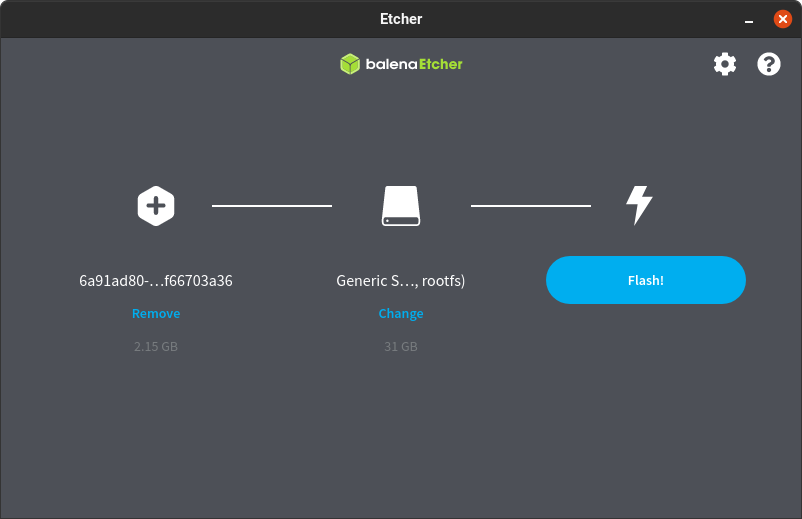
9. Una vez que Balena Etcher haya terminado de escribir la imagen, verá una confirmación.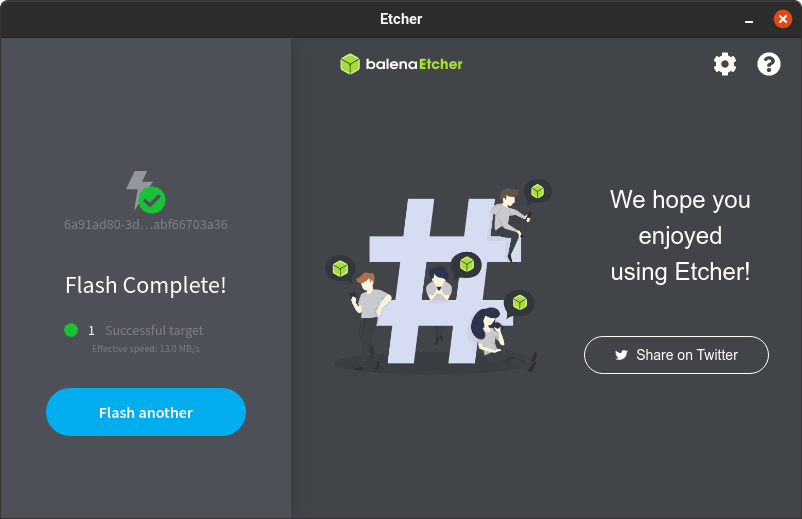
Mas información en https://www.home-assistant.io/installation/raspberrypi/





Debe estar conectado para enviar un comentario.