Node.js lleva ya unos cuantos años muy de moda aunque, ciertamente no es algo nuevo puesto que existen librerías como Twisted que hacen exactamente lo mismo, pero si es cierto que es la primera basada en JavaScript y que tiene un gran rendimiento.
Node.js es similar en su propósito a Twisted o Tornado de Python, Perl Object Environment de Perl, libevent o libev de C, EventMachine de Ruby, vibe.d de D y JEE de Java existe Apache MINA, Netty, Akka, Vert.x, Grizzly o Xsocket pero ,al contrario que la mayoría del código JavaScript, no se ejecuta en un navegador, sino en el servidor.
Quizas su éxito se deba a que Node.js puede ser combinado con una base de datos documental (por ejemplo, MongoDB o CouchDB) y JSON lo que permite desarrollar en un entorno de desarrollo JavaScript unificado. Con la adaptación de los patrones para desarrollo del lado del servidor tales como MVC y sus variantes MVP, MVVM, etc. Node.js facilita la reutilización de código del mismo modelo de interfaz entre el lado del cliente y el lado del servidor.
Node.js implementa algunas especificaciones de CommonJS.5 Node.js incluye un entorno REPL para depuración interactiva.
Node.js es una librería y entorno de ejecución de E/S dirigida por eventos y por lo tanto asíncrona que se ejecuta sobre el intérprete de JavaScript creado por Google V8.
Node.js es un entorno en tiempo de ejecución multiplataforma, de código abierto, para la capa del servidor (pero no limitándose a ello) basado en el lenguaje de programación ECMAScript, asíncrono, con I/O de datos en una arquitectura orientada a eventos y basado en el motor V8 de Google.
Fue creado con el enfoque de ser útil en la creación de programas de red altamente escalables, como por ejemplo, servidores web.
Fue creado por Ryan Dahl en 2009 y su evolución está apadrinada por la empresa Joyent, que además tiene contratado a Dahl en plantilla.3 4
Node.js funciona con un modelo de evaluación de un único hilo de ejecución, usando entradas y salidas asíncronas las cuales pueden ejecutarse concurrentemente en un número de hasta cientos de miles sin incurrir en costos asociados al cambio de contexto.6 Este diseño de compartir un único hilo de ejecución entre todas las solicitudes atiende a necesidades de aplicaciones altamente concurrentes, en el que toda operación que realice entradas y salidas debe tener una función callback. Un inconveniente de este enfoque de único hilo de ejecución es que Node.js requiere de módulos adicionales como cluster7 para escalar la aplicación con el número de núcleos de procesamiento de la máquina en la que se ejecuta.
V8
V8 es el entorno de ejecución para JavaScript creado para Google Chrome. Es software libre desde 2008, está escrito en C++ y compila el código fuente JavaScript en código de máquina en lugar de interpretarlo en tiempo real.
Node.js contiene libuv para manejar eventos asíncronos. Libuv es una capa de abstracción de funcionalidades de redes y sistemas de archivo en sistemas Windows y sistemas basados en POSIX como Linux, Mac OS X y Unix.
El cuerpo de operaciones de base de Node.js está escrito en JavaScript con métodos de soporte escritos en C++.
Módulos
Node.js incorpora varios «módulos básicos» compilados en el propio binario, como por ejemplo el módulo de red, que proporciona una capa para programación de red asíncrona y otros módulos fundamentales, como por ejemplo Path, FileSystem, Buffer, Timers y el de propósito más general Stream. Es posible utilizar módulos desarrollados por terceros, ya sea como archivos «.node» precompilados, o como archivos en javascript plano. Los módulos Javascript se implementan siguiendo la especificación CommonJS para módulos,8 utilizando una variable de exportación para dar a estos scripts acceso a funciones y variables implementadas por los módulos.9
Los módulos de terceros pueden extender node.js o añadir un nivel de abstracción, implementando varias utilidades middleware para utilizar en aplicaciones web, como por ejemplo los frameworks connect y express. Pese a que los módulos pueden instalarse como archivos simples, normalmente se instalan utilizando el Node Package Manager (npm) que nos facilitará la compilación, instalación y actualización de módulos así como la gestión de las dependencias. Además, los módulos que no se instalen el directorio por defecto de módulos de Node necesitarán la utilización de una ruta relativa para poder encontrarlos. El wiki Node.js proporciona una lista de varios de los módulos de terceros disponibles.
Pero ¿por qué javascript del lado del servidor?
Aunque Javascript tradicionalmente ha sido relegado a realizar tareas menores en el navegador, es actualmente un lenguaje de programación totalmente, tan capaz como cualquier otro lenguaje tradicional como C++, Ruby o Java. Ademas Javascript tiene la ventaja de poseer un excelente modelo de eventos, ideal para la programación asíncrona. Javascript también es un lenguaje omnipresente, conocido por millones de desarrolladores. Esto reduce la curva de aprendizaje de Node,js, ya que la mayoría de los desarrolladores no tendrán que aprender un nuevo lenguaje para empezar a construir aplicaciones usando Node.js.
Bucle de Eventos (Event Loop).
Además de la alta velocidad de ejecución de Javascript, la verdadera magia detrás de Node.js es el Bucle de Eventos (Event Loop). Para escalar grandes volúmenes de clientes, todas las operaciones intensivas I/O en Node.js se llevan a cabo de forma asíncrona. El enfoque tradicional para generar código asíncrono es engorroso y crea un espacio en memoria no trivial para un gran número de clientes(cada cliente genera un hilo, y el uso de memoria de cada uno se suma). Para evitar esta ineficiencia,así como la dificultad conocida de las aplicaciones basadas en hilos, (programming threaded applications), Node.js mantiene un event loop que gestiona todas las operaciones asíncronas.
Cuando una aplicación Node.js necesita realizar una operación de bloqueo (operaciones I/O como trabajo con archivos …etc) envía una tarea asíncrona al event loop, junto con un callback, y luego continúa.
Node.js se registra con el sistema operativo y cada vez que un cliente establece una conexión se ejecuta un callback. Dentro del entorno de ejecución de Node.js, cada conexión recibe una pequeña asignación de espacio de memoria dinámico, sin tener que generar un hilo de trabajo.10 A diferencia de otros servidores dirigidos por eventos, el lazo de manejo de eventos de Node.js no es llamado explícitamente sino que se activa al final de cada ejecución de una función de callback. El lazo de manejo de eventos se termina cuando ya no quedan eventos por atender.
¿Qué usos reales se le da a nodejs?
Es una herramienta genial para todo tipo de cosas. Aplicaciones web, aplicaciones en línea de comandos, scripts para administración de sistemas, todo tipo de aplicaciones de red, etc.
Es rápido, muy rápido. Esto es importante por varias razones:
- El desarrollo es más rápido.
- La ejecución de tests de unidad se puede hacer más rápido.
- Las aplicaciones son más rápidas y por tanto la experiencia de usuario es mejor.
- Menor coste de infraestrucutra (Linkedin pasó de tener 15 servidores a 4).
También destaca su flexibilidad. En otros entornos hay un servidor “monolítico” (apache, tomcat, etc.) y tu aplicación se “despliega” en él, y tienes unas estructuras de directorios y ficheros de configuración muy concretos. En nodejs tú lanzas el servidor web, y si quieres puedes lanzar varios, y si quieres puedes lanzar a la vez un servidor ftp, y los lanzas desde el directorio que quieras…
Node.js es un ambiente de ejecución para JavaScript construido sobre el motor JavaScript V8 de Chrome. Lo anterior significa que el uso de JavaScript ya no queda restringido solamente al navegador web, sino que tambien es posible usar este popular lenguage de programación para desarrollar aplicaciones de todo tipo, desde servidores web hasta aplicaciones de escritorio.
Por otra parte, npm es el administrador de paquetes de Node.js y funciona de manera similar a pip en el entorno Python. Con él podemos instalar cualquier paquete Node.jsque lleguemos a necesitar para nuestros proyectos.
Métodos de instalación de Node.js
Para instalar Node.js podemos seguir dos caminos:
- Instalar Node.js usando el instalador o los binarios oficiales. Este método es el más universal y funciona para usuarios de diferentes sistemas operativos y arquitecturas, entre ellos Windows, Mac y Linux.
- Instalar Node.js por medio de un gestor de paquetes. Este método es mas limitado y solamente funciona para usuarios de sistemas operativos tipo UNIX.
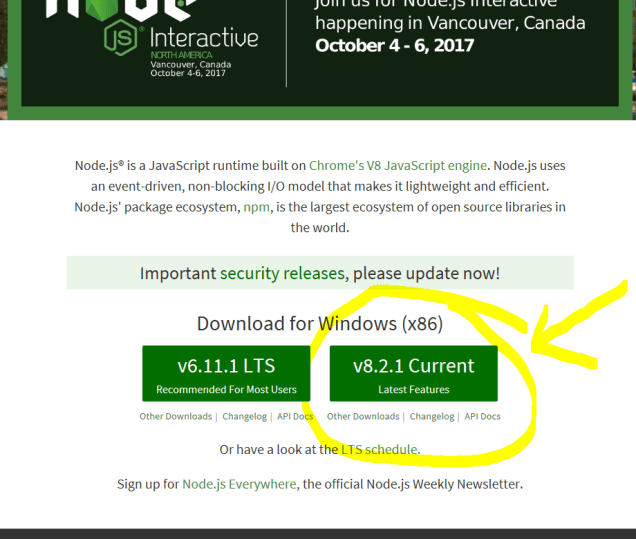




Puede que al intentar instalar algún paquete usando el instalador npm .
Por ejemplo, intentando reinstalar el paquete de firebase con npm install firebase angularfire2 –save le de un error parecido al siguiente:
PS C:\windows\system32> npm -v
2.5.1
PS C:\windows\system32> npm install bower -g
npm ERR! Windows_NT 6.3.9600
npm ERR! argv "C:\\Program Files\\nodejs\\\\node.exe" "C:\\Program Files\\nodejs\\node_modules\\npm\\bin\\npm-cli.js" "i
nstall" "bower" "-g"
npm ERR! node v0.12.0
npm ERR! npm v2.5.1
npm ERR! code ETIMEDOUT
npm ERR! errno ETIMEDOUT
npm ERR! syscall connect
npm ERR! network connect ETIMEDOUT
npm ERR! network This is most likely not a problem with npm itself
npm ERR! network and is related to network connectivity.
npm ERR! network In most cases you are behind a proxy or have bad network settings.
npm ERR! network
npm ERR! network If you are behind a proxy, please make sure that the
npm ERR! network 'proxy' config is set properly. See: 'npm help config'
npm ERR! Please include the following file with any support request:
npm ERR! C:\windows\system32\npm-debug.logEstos errores normalmente tienen su procedencia en el Proxy , por lo que deberemos configurar este para que interaccione con node,.js
Una vía para configurar el proxy y solucionar el problema es con el comando siguiente:
npm config set proxy “http://servidorproxy%5xxxxx:yyyyyyy@tesa:8080/”
xxxxxx: usuario que usamos para validarnos
yyyyy: pwd que usamos para validarnos








Debe estar conectado para enviar un comentario.