En este post intentamos abordar la construcción de una pinza amperimétrica para corriente continua basada en un sensor Hall y un circuito de amplificación activo. A diferencia de las pinzas convencionales para corriente alterna, que funcionan mediante inducción electromagnética, la medición de corriente continua requiere detectar el flujo magnético estático generado por el conductor por el que circula la corriente.
El principio de funcionamiento se basa en un núcleo de ferrita con entrehierro en el que se inserta un sensor de efecto Hall. Cuando por el conductor medido (que actúa como devanado primario) circula una corriente, genera un campo magnético que magnetiza el núcleo. El sensor Hall, ubicado en el entrehierro, mide la densidad de flujo magnético, proporcionando una tensión proporcional a dicha magnitud. De esa forma se obtiene una señal eléctrica directamente proporcional a la corriente que atraviesa el conductor.
Existen dos métodos para este tipo de medición:
- El método directo, que veremos a continuación, donde se mide de forma lineal el flujo con el sensor Hall.
- El método con bobina de compensación, más preciso pero también más complejo, en el que una corriente inducida en la bobina secundaria cancela el flujo magnético, permitiendo mediciones de alta linealidad.
Para la construcción usando el método directo, se puede partir de una pinza tipo caimán sobre la que se monta el núcleo de ferrita, obtenido de una fuente de alimentación en desuso. El núcleo se corta cuidadosamente en dos mitades (debido a su fragilidad) y se adhiere mecánicamente a las mordazas para asegurar un cierre preciso. Posteriormente se inserta el sensor Hall en el entrehierro, cuidando su alineación.
El sensor se alimenta a 5 V y su salida se amplifica mediante un amplificador operacional LM324 configurado en modo inversor con una ganancia de 100, utilizando resistencias de 100 kΩ y 1 kΩ respectivamente. Se incluye un potenciómetro de ajuste fino para calibrar el nivel de salida, de modo que la tensión en el osciloscopio corresponda a la corriente real medida. Tanto el amplificador como el sensor pueden alimentarse sin regulador desde una batería de 9 V.
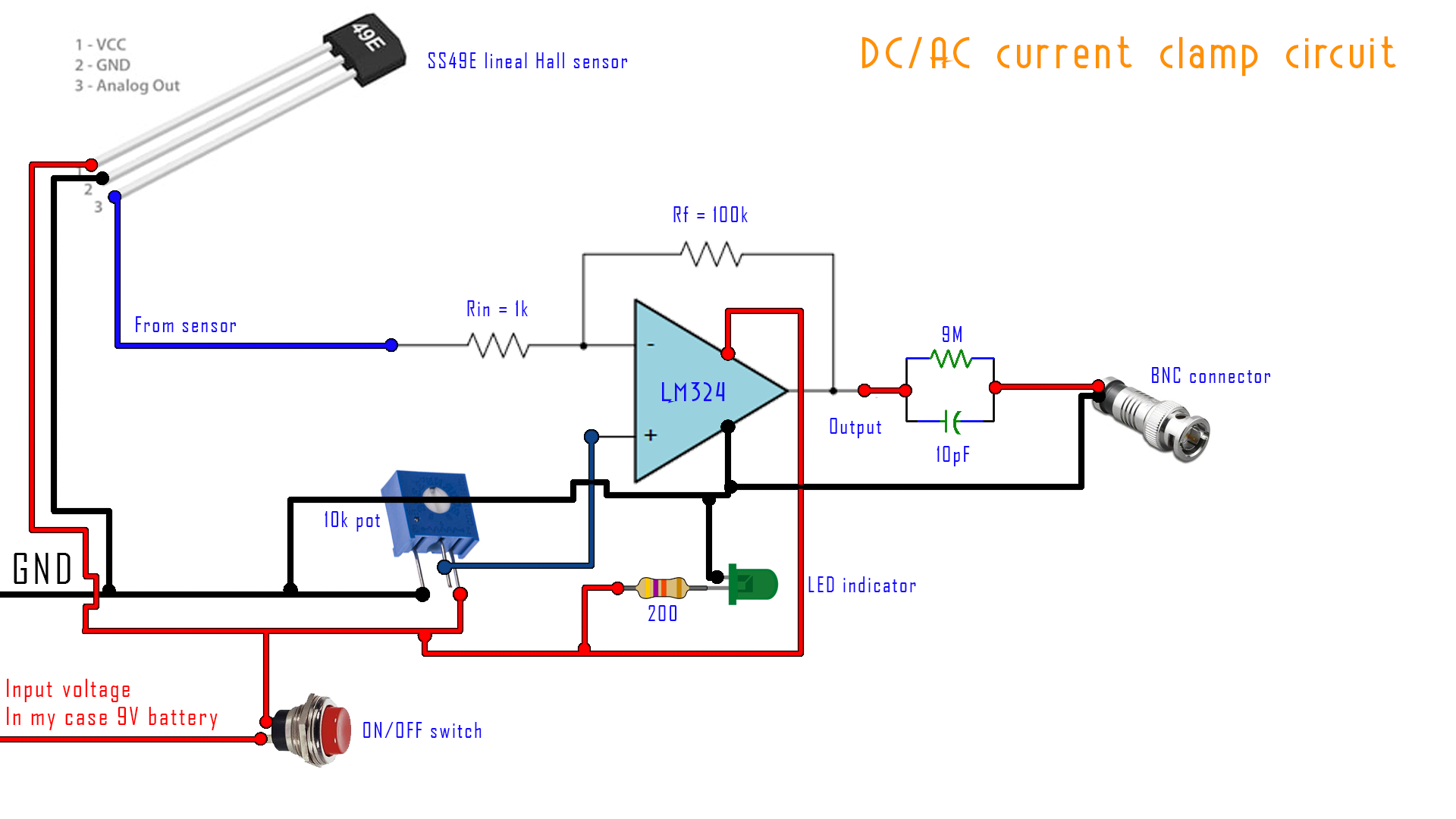
El circuito se ensambla sobre una placa perforada y se conecta a una salida tipo sonda con un filtro RC en serie, similar al de las pinzas comerciales. Todos los componentes se pueden alojar en una carcasa impresa en 3D con espacios previstos para el interruptor principal, un LED indicador y los conectores. Los archivos STL y el esquema eléctrico completo están disponibles en la web del autor original (ELECTRONOOBS).

La calibración se realiza aplicando una corriente conocida a través de un conductor (por ejemplo, 2,8 A) y ajustando el potenciómetro hasta obtener una lectura proporcional (2,8 V de salida). De este modo, se establece una relación lineal directa entre corriente y tensión. En las pruebas reportadas, la pinza mantiene una respuesta lineal hasta unos 9 A, punto a partir del cual el circuito entra en saturación debido al límite de salida del amplificador. Si se requiere aumentar la sensibilidad, se puede pasar el conductor varias veces por el núcleo, lo que incrementa la señal proporcionalmente al número de vueltas.
Una de las ventajas de este diseño es que, aunque está optimizado para corriente continua, también puede medir corriente alterna gracias al comportamiento lineal del sensor Hall ante campos magnéticos variables. Esto la convierte en una herramienta versátil para proyectos de instrumentación, caracterización de cargas electrónicas o mantenimiento de sistemas eléctricos.
Esta pinza DC de bajo costo demuestra que con un sensor Hall lineal, un amplificador operacional adecuado y un montaje mecánico preciso, es posible construir un instrumento funcional capaz de ofrecer mediciones estables y reproducibles tanto en corriente continua como alterna. Aunque la versión básica del circuito propuesto puede proporcionar un rendimiento notable, pueden aplicarse algunas mejoras para optimizar su exactitud y robustez:
- Sustituir el LM324 por amplificadores de precisión de bajo offset, como el OPA2333 o INA122.
- Incluir compensación térmica activa para estabilizar la ganancia y la sensibilidad del sensor Hall.
- Implementar realimentación magnética activa para lograr un funcionamiento de flujo nulo, como en el diseño con bobina de compensación.
- Diseñar una PCB dedicada con plano de masa continuo y filtros de desacoplo adecuados, reduciendo interferencias.
- Incorporar pantalla o blindaje electromagnético sobre el núcleo y la carcasa.
- Integrar la salida con un microcontrolador o data logger para registro continuo de corriente y visualización digital.
Con estas mejoras, el proyecto puede evolucionar desde una herramienta experimental hacia un instrumento calibrado de laboratorio, útil para la caracterización de fuentes de alimentación, medición de consumo en dispositivos electrónicos y análisis de eficiencia energética.
Pinza DC con bobina de compensación
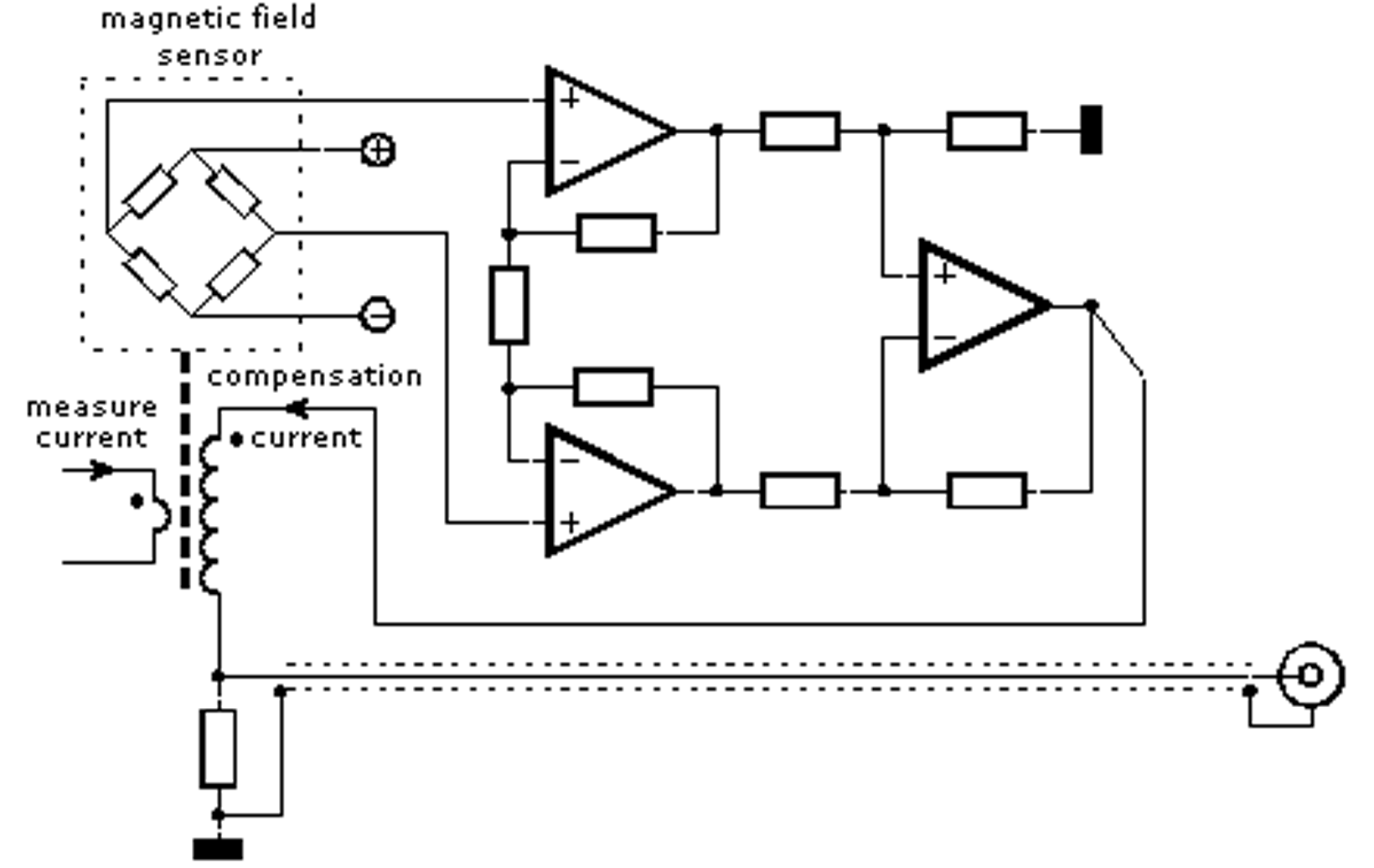
Una alternativa más avanzada para medir corriente continua consiste en el uso de una bobina de compensación (compensation winding). Este método, aunque más complejo en su construcción y calibración, ofrece mayor precisión y estabilidad frente a las limitaciones del sensor Hall en modo directo.
En esta técnica, el conductor medido actúa como devanado primario y atraviesa el núcleo de ferrita, el cual posee nuevamente un entrehierro con un sensor Hall encargado de medir el flujo magnético. Cuando la corriente circula por el conductor principal, genera un campo magnético que magnetiza el núcleo. El sensor detecta dicho flujo y, a partir de esta información, un circuito de control activa una corriente compensadora en el devanado secundario.
Esta corriente de compensación fluye en sentido opuesto al campo magnético generado por la corriente medida, de modo que el flujo total en el núcleo se mantiene en cero. En consecuencia, el núcleo no se magnetiza, eliminando la influencia de fenómenos no lineales y de histéresis del material magnético y del propio sensor Hall.
La ventaja fundamental de este sistema es su excelente linealidad y estabilidad térmica, permitiendo mediciones más exactas en un rango amplio de corriente. Aunque su implementación requiere una mayor precisión en el bobinado, diseño del circuito de realimentación y calibración, representa una evolución natural hacia una pinza de nivel profesional o de laboratorio.




Debe estar conectado para enviar un comentario.