» Publicar o perecer » es un aforismo que describe la presión de publicar trabajos académicos para tener éxito en una carrera académica . Tal presión institucional es generalmente más fuerte en las universidades de investigación . Algunos investigadores han identificado el entorno de publicar o perecer como un factor que contribuye a la crisis de replicación .Las publicaciones exitosas llaman la atención sobre los académicos y sus instituciones patrocinadoras, lo que puede ayudar a continuar con la financiación y sus carreras. En la percepción académica popular, los académicos que publican con poca frecuencia o que se enfocan en actividades que no resultan en publicaciones, como instruir a estudiantes universitarios , pueden perder terreno en la competencia por los puestos de tenencia disponibles. La presión para publicar se ha citado como una de las causas de los trabajos deficientes que se envían a las revistas académicas . El valor del trabajo publicado a menudo está determinado por el prestigio de la revista académica en la que se publica. Las revistas se pueden medir por su factor de impacto (FI) , que es el es el número promedio de citas de los artículos publicados en una revista en particular. Veremos en este post una interesante aplicación gratuita que nos puede ayudar a tener una visión mas clara sobre el mundo de las citas bibliográficas.
Publish or Perish es un programa de software que recupera y analiza citas académicas. Utiliza una variedad de fuentes de datos para obtener las citas sin procesar, luego las analiza y presenta una variedad de métricas de citas , incluida la cantidad de artículos, el total de citas y el índice h.
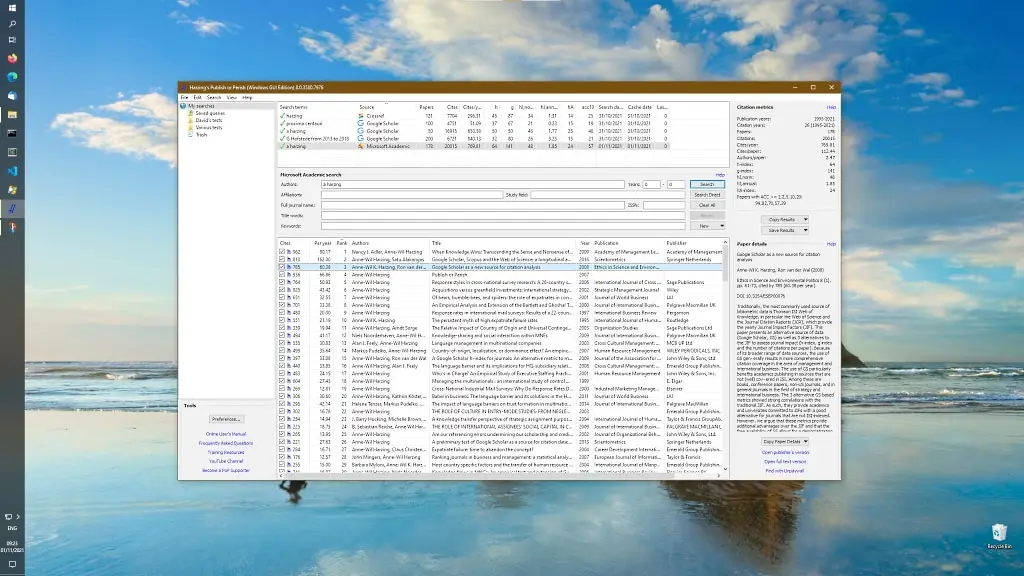
Las fuentes de datos disponibles actualmente son:
| Fuente de datos | notas |
|---|---|
| referencia cruzada | Disponible de forma gratuita |
| Google Académico | Disponible de forma gratuita |
| Perfil de Google Académico | Disponible de forma gratuita |
| Microsoft académico | Requiere una suscripción gratuita de Microsoft Nota: Microsoft ha anunciado que su fuente de datos se suspenderá después del 31 de diciembre de 2021 |
| AbrirAlex | Disponible de forma gratuita. Actualmente (febrero de 2022) en las primeras etapas de desarrollo con opciones de búsqueda limitadas. Realizaremos un seguimiento de los desarrollos futuros. |
| PubMed | Disponible de forma gratuita |
| Scopus | Requiere una clave API gratuita de Elsevier |
| Académico semántico | Requiere una clave API gratuita de Semantic Scholar |
| Web de la Ciencia | Requiere una suscripción de Clarivate (normalmente proporcionada por su organización) |
| Importación de datos externos | Permite importar datos obtenidos externamente de Web of Science, RefMan, EndNote y muchos otros. |
Los resultados están disponibles en pantalla y también pueden copiarse en el portapapeles de Windows o macOS (para pegarlos en otras aplicaciones) o guardarse en una variedad de formatos de salida (para referencia futura o análisis adicional). Publish or Perish incluye un archivo de ayuda detallado con sugerencias de búsqueda e información adicional sobre las métricas de citas.
Para qué sirve Publish or Perish
¿Está solicitando una titularidad, un ascenso o un nuevo trabajo ? ¿Necesita prepararse para su evaluación de desempeño? Publish or Perish está diseñado para ayudar a académicos individuales a presentar su caso para el impacto de la investigación de la mejor manera posible, incluso si tiene muy pocas citas .
También puede usarlo para decidir a qué revistas enviar , prepararse para una entrevista de trabajo , hacer una revisión de la literatura , hacer una investigación bibliométrica , escribir elogios u obituarios , o hacer algunos deberes antes de conocer a su héroe académico .! Publish or Perish es una auténtica navaja suiza! .
Descargar e instalar Publish or Perish
El software Publish or Perish está disponible gratuita como aplicaciones de Microsoft Windows y Apple macOS; la versión de Windows también se puede instalar y utilizar en ordenadores GNU/Linux con la ayuda de un emulador adecuado como CrossOver Linux o Wine.
La versión de Windows de Publish or Perish está disponible para descargar siguiendo las instrucciones a continuación. El paquete de descarga contiene un instalador para Microsoft Windows y está firmado digitalmente por Tarma Software Research Ltd.
Nota: El instalador del software Publish or Perish NO requiere derechos de administrador. Puede instalar el software Publish or Perish en su computadora incluso como un usuario sin privilegios.
Acuerdo de licencia
Publish or Perish se proporciona por cortesía de Harzing.com. Es gratis para uso personal sin fines de lucro; consulte el Acuerdo de licencia de usuario final para conocer los términos y condiciones completos de la licencia.
Requisitos del sistema
Verifique que su ordenador cumple con los siguientes requisitos mínimos del sistema:
- Windows 7, 8, 8.1, 10 y 11, incluidas las ediciones x64 y Server.
- Algo de memoria (suficiente para ejecutar el sistema operativo, no mucho más).
- Algo de espacio en el disco duro (ídem).
- Una conexión a Internet.
Descargar información
Descargue el instalador del software Publish or Perish del sitio web Harzing.com:
![]() Instalador de Publish or Perish para Windows (1.8 MB)
Instalador de Publish or Perish para Windows (1.8 MB)
Versión: 8.2.3944 (23 de marzo de 2022)
Instrucciones de instalación
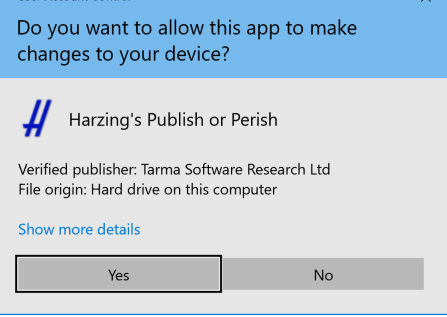
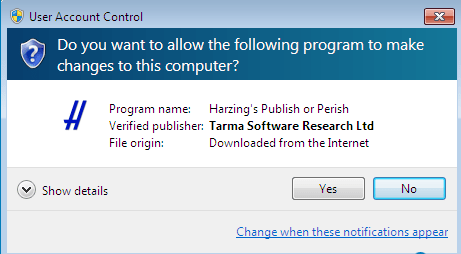
Inicie el instalador de PoP8Setup.exe haciendo doble clic en el archivo que acaba de descargar. En la mayoría de los sistemas, ahora aparecerá un cuadro de diálogo de advertencia de seguridad similar a uno de los siguientes.
Windows 10 (actualización 1607 y posterior):

Windows 10 (original) y Windows 8.x:

Windows 7:

Haga clic en Ejecutar , Continuar o Sí después de haber verificado que el nombre del editor es Tarma Software Research Ltd.
(Nota: antes del 15 de agosto de 2014, nuestros instaladores estaban firmados por Tarma Software Research Pty Ltd ; estos también están bien).
Ahora se iniciará el instalador. Siga las instrucciones en pantalla para confirmar su aceptación del acuerdo de licencia e instalar el software Publish or Perish en su computadora.
Nota: si tiene una versión anterior de Publish or Perish en su computadora, se eliminará automáticamente antes de que se instale la nueva versión. Sus consultas se conservan durante el proceso de actualización.
Una vez completada la instalación, puede iniciar Publish or Perish a través del menú Inicio de Windows: haga clic en el botón del menú Inicio , luego en Todos los programas y luego en Publish or Perish 7 .
Si alguna vez necesita eliminar el software Publish or Perish de su sistema, use el panel de control Agregar o quitar programas.
Cómo citar el software Publish or Perish
Si está utilizando el software Publish or Perish en uno de sus artículos de investigación o desea hacer referencia a él, utilice el siguiente formato:
Harzing, AW (2007) Publish or Perish , disponible en https://harzing.com/resources/publish-or-perish
Cronología de las versiones principales de Publish or Perish
- 1 de noviembre de 2021: lanzamiento de Publish or Perish 8 , 15 años después del Publish or Perish original.
- 2 de septiembre de 2019: lanzamiento de Publish or Perish 7 , incluidas las ediciones de Windows y macOS por primera vez.
- 20 de octubre de 2017: lanzamiento de Publish or Perish 6 , con cuatro fuentes de datos nuevas y un informe de consulta completo
- 28 de octubre de 2016: lanzamiento de Publish or Perish 5 , 10 años después del Publish or Perish original.
- 28 de febrero de 2013: lanzamiento de Publish or Perish 4
- 1 de junio de 2010: lanzamiento de Publish or Perish 3
- 5 de abril de 2007: lanzamiento de Publish or Perish 2
- 17 de octubre de 2006: primer lanzamiento público del software Publish or Perish



Debe estar conectado para enviar un comentario.