En efecto es posible replicar en Windows 11 un entorno Python de Ubuntu como por ejemplo toda la Instalación de NILMTK o incluso NILMTK_CONTRIB
Para replicar tu instalación de NILMTK de Ubuntu en Windows 11 utilizando el Subsistema de Windows para Linux (WSL), sin Conda pero con Jupyter Notebook, y ya disponiendo del fichero requirements.txt y las carpetas nilmtk, nilm_metadata y nilmtk-contrib, puedes seguir estos pasos:
1. Preparar el Entorno WSL
Asegúrate de que tu distribución de Linux en WSL (por ejemplo, Ubuntu) tenga Python 3.6+ y pip instalados. NILMTK requiere Python 3.6 o superior.
Puedes verificar las versiones con python3 --version y pip3 --version.
Si es necesario, instálalos o actualízalos. Para Ubuntu en WSL, puedes usar:bashsudo apt update sudo apt install python3 python3-pip
2. Instalar Jupyter Notebook en WSL
Instala Jupyter Notebook usando pip en tu terminal WSL:
Ejecuta el comando:bashpip3 install jupyter Esto instalará Jupyter en tu espacio de usuario5.
Es posible que necesites añadir ~/.local/bin a tu variable de entorno PATH si los comandos de Jupyter no se encuentran. Edita tu archivo ~/.bashrc (o ~/.zshrc si usas Zsh) y añade la siguiente línea:bashexport PATH="$HOME/.local/bin:$PATH" Luego, aplica los cambios con source ~/.bashrc (o source ~/.zshrc)4.
3. Configurar las Carpetas y Dependencias de NILMTK
Copiar carpetas: Transfiere tus carpetas nilmtk, nilm_metadata y nilmtk-contrib a un directorio de proyecto adecuado dentro del sistema de archivos de WSL (por ejemplo, ~/mi_proyecto_nilmtk/).
Instalar dependencias desde requirements.txt: Navega en la terminal WSL al directorio donde se encuentra tu archivo requirements.txt (probablemente dentro de ~/mi_proyecto_nilmtk/). Luego, instala las dependencias:
Si encuentras errores relacionados con la compilación de paquetes, es posible que necesites instalar herramientas de compilación. En Ubuntu WSL, esto se puede hacer con: sudo apt install build-essential.
Instalar nilm_metadata y nilmtk en modo desarrollo: Esto permite que Python encuentre los paquetes en las carpetas que has copiado.
Para nilm_metadata (asumiendo que «nilmk-metadata» es un error tipográfico):bashcd ~/mi_proyecto_nilmtk/nilm_metadata # Ajusta la ruta si es diferente python3 setup.py develop
Para nilmtk:bashcd ~/mi_proyecto_nilmtk/nilmtk # Ajusta la ruta si es diferente python3 setup.py develop La instalación en modo desarrollo (develop) es útil para asegurar que los cambios en el código fuente se reflejen inmediatamente sin necesidad de reinstalar2.
Carpeta nilmtk-contrib: El manejo de la carpeta nilmtk-contrib dependerá de su contenido. Si contiene paquetes Python adicionales con sus propios archivos setup.py, podrías necesitar instalarlos de manera similar. Si son datos o scripts, asegúrate de que estén en una ubicación accesible para tu proyecto.
4. Ejecutar Jupyter Notebook desde WSL
Navega en tu terminal WSL al directorio de tu proyecto (donde deseas que Jupyter Notebook acceda a los archivos y donde se guardarán los nuevos notebooks), por ejemplo, ~/mi_proyecto_nilmtk/.
Inicia Jupyter Notebook con el siguiente comando:bashjupyter notebook --no-browser La opción --no-browser evita que WSL intente abrir un navegador en el entorno Linux, lo cual generalmente no es deseado46.
La terminal mostrará un mensaje con una o más URLs, usualmente comenzando con http://localhost:8888/ e incluyendo un token de seguridad46. Copia una de estas URLs completas.
Abre un navegador web en Windows 11 (como Edge, Chrome o Firefox) y pega la URL copiada en la barra de direcciones.
5. Verificar la Instalación de NILMTK
Dentro de la interfaz de Jupyter Notebook en tu navegador:
Crea un nuevo notebook de Python 3.
En una celda de código, ejecuta:pythonimport nilmtk print(nilmtk.__version__)
Si no aparecen errores y se muestra la versión de NILMTK, la instalación se ha replicado correctamente y NILMTK está listo para usarse1.
Siguiendo estos pasos, deberías poder replicar tu entorno NILMTK en WSL en Windows 11, utilizando tus archivos y carpetas existentes y cumpliendo con tus requisitos de no usar Conda y sí Jupyter Notebook.
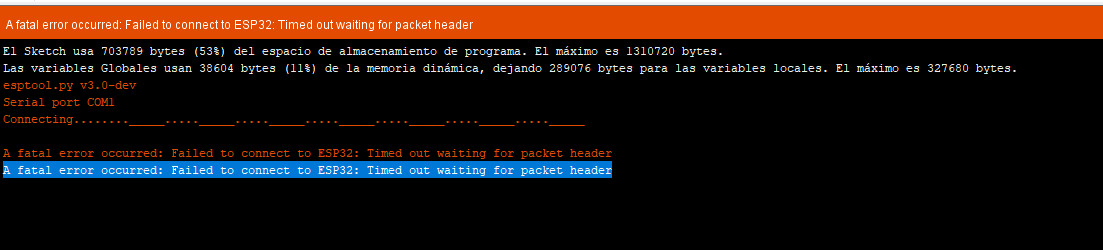
A veces a pesar de todo y seguir al pie de las letra los manuales no salen bien las cosas, A continuación algunos de los errores que podemos tener en la instalación:
Error externally-managed-environment
El error error: externally-managed-environment que estás viendo indica que tu sistema Linux (dentro de WSL) gestiona los paquetes de Python a través de su propio administrador de paquetes (como apt en Ubuntu/Debian) para evitar conflictos y asegurar la estabilidad del sistema 145. Por lo tanto, pip no te permite instalar paquetes globalmente por defecto.
La forma recomendada y más segura de proceder es crear un entorno virtual. Esto aislará tu proyecto de NILMTK y sus dependencias, incluyendo Jupyter, del Python del sistema 45.
Aquí te explico cómo continuar:
METODO 1
1. Crear y Activar un Entorno Virtual en WSL
En tu terminal WSL, antes de intentar instalar Jupyter o cualquier otro paquete con pip, crea un entorno virtual. Es una buena práctica hacerlo dentro de tu directorio de proyecto.
Navega a tu directorio de proyecto (donde tienes las carpetas nilmtk, nilm_metadata, nilmtk-contrib y tu requirements.txt):bashcd ~/mi_proyecto_nilmtk # O la ruta donde hayas puesto tus archivos
Crea el entorno virtual (puedes llamarlo venv_nilmtk o como prefieras):bashpython3 -m venv venv_nilmtk Es posible que necesites instalar primero el paquete python3-venv si no está disponible: sudo apt install python3-venv5.
Activa el entorno virtual:bashsource venv_nilmtk/bin/activate Una vez activado, tu prompt de la terminal debería cambiar para indicar que estás dentro del entorno virtual (por ejemplo, (venv_nilmtk) canjayar@carlosrn:...$).
2. Instalar Jupyter y tus Dependencias Dentro del Entorno Virtual
Ahora que el entorno virtual está activo, pip (o python -m pip) instalará los paquetes dentro de este entorno aislado, sin afectar al sistema global.
Instala Jupyter Notebook:bashpip install jupyter (Dentro de un entorno virtual activado, generalmente pip se refiere al pip del entorno, que corresponde a la versión de Python con la que se creó el entorno).
Instala las dependencias de NILMTK desde tu archivo requirements.txt:bashpip install -r requirements.txt
Instala nilm_metadata y nilmtk en modo desarrollo (como se indicó anteriormente, pero ahora dentro del entorno virtual):bashcd nilm_metadata # Ajusta la ruta si es diferente python setup.py develop cd ../nilmtk # Ajusta la ruta si es diferente python setup.py develop cd .. # Vuelve al directorio raíz de tu proyecto
Copia la URL proporcionada (incluyendo el token) y pégala en tu navegador de Windows 11.
Otras Opciones (Menos Recomendadas)
Usar --break-system-packages: Podrías forzar la instalación global con pip3 install jupyter --break-system-packages24. Sin embargo, esto no es recomendable ya que puede causar problemas con los paquetes gestionados por el sistema operativo y potencialmente romper tu instalación de Python o WSL 15.
Instalar con apt: Podrías intentar sudo apt install python3-notebook (el nombre del paquete puede variar). Esto instalaría la versión de Jupyter de los repositorios de tu distribución, que podría no ser la más reciente o la que necesitas. Generalmente, para desarrollo Python, se prefiere pip dentro de un entorno virtual para tener más control sobre las versiones de los paquetes.
Error de dependencias
El error en la instalación de dependencias, específicamente con nilm-metadata @ file:///home/user/nilm_metadata, se debe a que pip está intentando encontrar el paquete nilm-metadata en la ruta del sistema de archivos WSL (/home/user/nilm_metadata), pero esa ruta no es válida desde la perspectiva de Windows (donde la ruta correcta sería C:\Users\user\mi_proyecto_nilmtk).
Para solucionar esto, tienes que modificar la referencia a nilm-metadata en tu archivo requirements.txt para que pip pueda encontrar el paquete correctamente. Hay dos opciones principales:
Opción 1: Modificar requirements.txt para usar la ruta WSL correcta (recomendado)
Edita requirements.txt dentro de WSL. Abre el archivo requirements.txt con un editor de texto (como nano o vim) dentro de tu entorno WSL.
Encuentra la línea que menciona nilm-metadata. Debería ser algo como:textnilm-metadata @ file:///home/carlos/nilm_metadata
Cambia la ruta a la ruta WSL correcta. Si tu directorio de proyecto mi_proyecto_nilmtk está directamente dentro de tu directorio de inicio en WSL, la ruta podría ser correcta. Sin embargo, si has movido la carpeta nilm_metadata a otro lugar dentro de WSL, asegúrate de que la ruta refleje la ubicación correcta dentro del sistema de archivos de WSL.Por ejemplo, si la estructura de directorios en WSL es:text/home/carlos/mi_proyecto_nilmtk/nilm_metadata Entonces la línea en requirements.txt debería ser:textnilm-metadata @ file:///home/carlos/mi_proyecto_nilmtk/nilm_metadata
Guarda los cambios en requirements.txt.
Reintenta la instalación:bashpip install -r requirements.txt
Opción 2: Eliminar la referencia y usar pip install -e . en la carpeta nilm_metadata
Esta opción es útil si planeas desarrollar activamente nilm_metadata y quieres que los cambios se reflejen inmediatamente.
Elimina la línea de nilm-metadata de requirements.txt.
Instala nilm_metadata en modo editable:bashcd nilm_metadata pip install -e . cd .. # Para volver al directorio principal de tu proyecto
Consideraciones Adicionales
Entornos Virtuales: Asegúrate de que tu entorno virtual esté activado cuando realices estos cambios y reinstales las dependencias.
Permisos: Los permisos de archivo dentro de WSL pueden ser a veces problemáticos, especialmente cuando se interactúa con archivos en el sistema de archivos de Windows. Si encuentras errores de permiso, verifica que tienes los permisos adecuados para leer y escribir en los directorios y archivos relevantes desde dentro de WSL. 3.
Rutas absolutas vs. relativas: En general, es mejor usar rutas relativas dentro de requirements.txt si es posible, para que el archivo sea más portátil. Sin embargo, con instalaciones locales como esta, a veces las rutas absolutas son más directas.
WSL2 file system: WSL2 utiliza un sistema de archivos virtualizado. Asegúrate de que las rutas sean correctas dentro de este sistema.
Al seguir estos pasos y asegurarte de que las rutas en tu requirements.txt son correctas para el sistema de archivos WSL, deberías poder resolver el error y continuar con la instalación de NILMTK.
Después de toda una odisea (el extracto esta mas abajo), creo es necesario una guía clara y concisa para replicar una instalación funcional de nilmtk, nilm_metadata y nilmtk-contrib en una nueva máquina Windows 11, minimizando los problemas.
Basándonos en toda la experiencia previa y las guías de los resultados de búsqueda, en este post he intentado ofrecer un enfoque consolidado y robusto sobre como instalar estos tres paquetes de python de software libre especializados en la disgregación de la energia eléctrica , tema que hemos tratado en numerosas ocasiones en este blog tanto a nivel hardware , como a nivel software. Se ha intentado priorizar la creación de un entorno base estable con versiones de paquetes que se sabe son compatibles, y luego instalar los componentes de NILMTK.
Tenemos en principio dos opciones:
Opción A — Conda (más sencilla, pero limitada)
conda install -c nilmtk nilmtk=0.4.3 -y
✅ Más fácil de instalar.
❌ Solo funciona si no hay conflictos con versiones de pandas, python, etc.
❌ Puede fallar en Windows por incompatibilidades del canal conda de nilmtk.
✅ No necesitas clonar el repositorio manualmente.
👉 Recomendada si funciona sin errores tras crear el entorno con python=3.7.
Opción B — Instalación desde GitHub (más flexible y robusta)
git clone https://github.com/nilmtk/nilmtk.git cd nilmtk python setup.py develop
✅ Te da más control.
✅ Puedes modificar código fuente de nilmtk.
✅ Obligatoria si usarás también nilmtk-contrib, que depende de modificar código fuente.
❗ Necesitas instalar manualmente las versiones compatibles de las dependencias (como pandas==0.25.3, numpy==1.18.5, etc.).
👉 Recomendada si quieres usar también nilmtk-contrib, o evitar errores con conda install. Dado que quremos instalar nilmtk, nilm_metadata y nilmtk-contrib, lo más robusto y estable es usar la Opción B (instalación desde GitHub) con dependencias bien controladas por pip.
OPCION B— INSTALACIÓN DE NILMTK EN WINDOWS (2025)
📌 Requisitos previos
Tienes instalado Anaconda o Miniconda(Miniconda es gratuito y funciona perfectamente).
Usas Windows 10 u 11.
Tienes Git instalado (git --version debe funcionar). Si no lo tienes descargalo e instala Git desde https://git-scm.com/download/win.
Tienes conexión a Internet.
Tener descargado desde Github los paquetes nilmtk, nilmtk_metadata y nilmtk_contrib (descargados y descomprimidos en carpetas colgado del directorio personal).
Microsoft Visual Studio Code con los complementos de Python y Jupyter Notebook (aconsejable)
GUÍA COMPLETA Y FUNCIONAL PARA INSTALAR NILMTK Y NILM_METADATA EN WINDOWS:
🔁 PASO 0 – Eliminar entorno anterior y limpiar caché
Problema posible:El error PackagesNotFoundError: The following packages are not available from current channels: - python=3.7.12 ocurre porque la versión específica de Python (3.7.12) que intentas instalar no está disponible en el canal defaults para Windows actualmente.
Soluciones 1. Usa una versión disponible de Python 3.7:En vez de pedir la versión exacta 3.7.12, puedes solicitar simplemente python=3.7, lo que instalará la versión 3.7 más reciente disponible en los canales configurados:
conda create -n nilmtk-env python=3.7 Esto suele ser suficiente para la mayoría de los casos y es la recomendación general de la documentación de conda.
2. Agrega canales adicionales (conda-forge) ACONSEJABLE:Algunas versiones antiguas solo están disponibles en otros canales como conda-forge. Puedes añadir este canal y luego intentar crear el entorno:
conda create -n nilmtk-env python=3.7.12 -c conda-forge Esto amplía las fuentes de paquetes y puede resolver el problema si el paquete existe en conda-forge.
3. Verifica versiones disponibles :Puedes consultar las versiones de Python disponibles para Windows-64 en conda-forge en la página oficial de Anaconda. Si ves que 3.7.12 no está disponible para win-64, deberás usar una versión diferente o cambiar de canal.
4. Considera usar una versión más reciente de Python :Si el paquete o proyecto lo permite, considera usar una versión más reciente de Python (por ejemplo, 3.9, 3.10, etc.), ya que las versiones antiguas pueden estar descontinuadas en los canales principales.
cd C:\Users\carlo\nilmtk pip install -e . --no-deps
🧪 PASO 4 – Instalar NILM Metadata (modo editable)
cd C:\Users\carlo\nilm_metadata pip install -e .
✅ PASO 5 – Verificar instalación
Abre Python o un notebook y ejecuta:
import nilmtk import nilm_metadata print("¡NILMTK y NILM Metadata funcionando correctamente!")
PROBLEMAS:El error ModuleNotFoundError: No module named 'networkx' indica que el módulo networkx no está instalado en el entorno donde estás ejecutando Jupyter y usando NILMTK.
Cómo solucionarlo Paso 1: Instalar networkx:Abre una terminal o usa una celda en Jupyter para instalar el paquete: pip install networkx O si usas conda (recomendado si NILMTK está en un entorno conda): conda install networkx Paso 2: Verifica que la instalación sea en el entorno correcto.Si usas un entorno conda llamado, por ejemplo, nilmtk-env, asegúrate de activarlo antes de instalar:
conda activate nilmtk-env conda install networkx O desde Jupyter, asegúrate de que el kernel que usas corresponde a ese entorno.
Paso 3 (opcional): Instalar todas las dependencias de NILMTK,Para evitar problemas con otros módulos faltantes, puedes instalar NILMTK con todas sus dependencias:
pip install nilmtk[all] O si lo instalaste desde conda-forge:
bash conda install -c conda-forge nilmtk El nuevo error ModuleNotFoundError: No module named 'matplotlib' indica que el paquete matplotlib no está instalado en tu entorno actual.
Solución Paso 1: Instalar matplotlib Abre una terminal o usa una celda en Jupyter y ejecuta:
bash pip install matplotlib O si usas conda:
bash conda install matplotlib Paso 2: Verifica el entorno activo Si usas un entorno conda, asegúrate de activarlo antes de instalar:
bash conda activate nilmtk-env conda install matplotlib Paso 3: Reinicia el kernel de Jupyter Después de instalar, reinicia el kernel para que los cambios tengan efecto.
Recomendación adicional Para evitar problemas con dependencias faltantes, puedes instalar todas las dependencias recomendadas para NILMTK con:
bash pip install nilmtk[all] O asegurarte de instalar todos los paquetes necesarios listados en la documentación oficial
La opción B, es la opción deseable mas probada y que debería funcionar , pero como este mundo es tan variable no siempre las cosas funcionan como quisiéramos , así que ahora os muestro algunas otras opciones se supone que deberían llegar al mismo final:
OPCION 1 ( NO SIEMPRE FUNCIONAL)
1. Limpieza (Opcional, pero recomendado si hubo intentos previos en la nueva máquina): Si ya has intentado instalar NILMTK en la nueva máquina y falló, es bueno empezar limpio. Abre «Anaconda Prompt» (o tu terminal configurada para Conda) y ejecuta:
2. Crear un Entorno Conda Base Compatible: Este es el paso más crucial. Crearemos un entorno con Python 3.7 y versiones específicas de las dependencias clave que son conocidas por su compatibilidad con nilmtk 0.4.345.
python=3.7: Versión de Python que ofrece buena compatibilidad con las dependencias más antiguas que nilmtk 0.4.3 podría necesitar.
numpy=1.19.5: Crucial para nilmtk 0.4.3 (requiere <1.20).
pandas=1.1.5: Una versión de Pandas que debería funcionar bien con NumPy 1.19.5 y Python 3.7. (Si nilmtk=0.4.3 del canal nilmtk insiste en pandas<1.0, Conda podría intentar degradarlo durante la instalación de nilmtk).
Otras dependencias: Versiones específicas para evitar conflictos.
-c conda-forge: Usar el canal conda-forge para obtener estos paquetes.
3. Activar el Nuevo Entorno:
conda activate nilmtk-env
4. Instalar nilmtk (Versión Estable de Conda): Instalaremos la versión 0.4.3 directamente desde el canal nilmtk134.
conda install -c nilmtk nilmtk=0.4.3 -y
Verifica si Conda intenta cambiar la versión de Pandas. Si es así y lo degrada a algo <1.0 (p.ej., 0.25.3), está bien, ya que nilmtk=0.4.3 podría requerirlo.
5. Instalar nilm_metadata desde tu Repositorio Local (si lo prefieres así): Si tienes un repositorio local de nilm_metadata que sabes que funciona y quieres usar:
cd RUTA_A_TU_REPOSITORIO_NILM_METADATA pip install -e .
Alternativamente, puedes instalarlo desde GitHub 4:
6. Instalar Dependencias de nilmtk-contrib (TensorFlow y CVXPY) con Conda (¡con cuidado!):<–OPCIONAL Este es el paso delicado. Necesitamos instalar tensorflow y cvxpy sin que rompan nuestro numpy=1.19.5.
Intentaremos con TensorFlow 2.4.x, que es una de las últimas versiones que podría ser compatible con NumPy 1.19.x .
Si NumPy sigue siendo 1.19.5 (o <1.20): ¡Perfecto! Procede al siguiente paso.
Si NumPy se actualizó: Esto indica un conflicto fundamental. La instalación de tensorflow=2.4 no fue compatible con mantener numpy=1.19.5. En este punto, tendrías que:
O bien, encontrar una versión aún más antigua de TensorFlow (y Keras) que sí sea compatible.
O, si tu nilmtk-contrib local no usa características muy nuevas de TensorFlow, podrías intentar la instalación de nilmtk-contrib sin TensorFlow preinstalado y ver si pip puede encontrar una solución (aunque esto es arriesgado).
O reconsiderar la necesidad de nilmtk-contrib si este conflicto es irresoluble con nilmtk 0.4.3.
7. Instalar nilmtk-contrib desde tu Repositorio Local (usando --no-deps): Asumiendo que el Paso 6 fue exitoso y NumPy está intacto:
cd RUTA_A_TU_REPOSITORIO_NILMTK_CONTRIB pip install -e . --no-deps
La opción --no-deps es crucial para evitar que pip intente reinstalar dependencias (como NumPy) que ya has configurado cuidadosamente con Conda.
Alternativamente, si no necesitas tu versión local y quieres probar la de GitHub 4:
(Pero esto podría traer sus propios problemas de dependencias si la rama principal de nilmtk-contrib ha avanzado).
8. Modificar nilmtk-contrib para Importaciones de Keras/TensorFlow (si es necesario): Puede ocurrir que tu nilmtk-contrib local podría usar rutas de importación obsoletas para Keras. Si, después de la instalación, obtienes errores como ModuleNotFoundError: No module named 'tensorflow.keras.layers.core' o ...tensorflow.keras.layers.pooling':
Navega a los archivos .py dentro de tu nilmtk-contrib local que causan el error.
Cambia las importaciones. Por ejemplo:
from tensorflow.keras.layers.core import Activation -> from tensorflow.keras.layers import Activation
from tensorflow.keras.layers.pooling import AveragePooling1D -> from tensorflow.keras.layers import AveragePooling1D
Repite para cualquier otra importación obsoleta de Keras.
9. Instalar Jupyter y Registrar el Kernel (Opcional, para uso con notebooks):
10. Verificar la Instalación Completa: Abre Python en tu entorno nilmtk-env y ejecuta el siguinte script: python import numpy print(f»NumPy: {numpy.__version__}») # Esperado: 1.19.5 import pandas print(f»Pandas: {pandas.__version__}») # Esperado: 1.1.5 o <1.0 (p.ej., 0.25.3) import tensorflow print(f»TensorFlow: {tensorflow.__version__}») # Esperado: ~2.4.x import nilm_metadata print(f»nilm_metadata: {nilm_metadata.__version__}») import nilmtk print(f»NILMTK: {nilmtk.__version__}») # Esperado: 0.4.3 from nilmtk import DataSet print(«NILMTK DataSet importado.») # Intenta importar un componente de nilmtk_contrib si la instalación fue exitosa # from nilmtk_contrib.disaggregate import CO # print(«Componente de nilmtk_contrib importado.») print(«¡Verificación completada!»)
Esta guía es un intento de consolidar las lecciones aprendidas. La clave es la creación de un entorno base con versiones muy específicas y el manejo cuidadoso de la instalación de nilmtk-contrib para no perturbar numpy. Si el conflicto de tensorflow con numpy=1.19.5 resulta ser insuperable (Paso 6), esa será la principal barrera para usar tu nilmtk-contrib local con nilmtk 0.4.3..
Una solución más robusta: Recrear el entorno con Python 3.7
Como los conflictos de dependencia con Python 3.8 pueden ser persistentes para las versiones más antiguas de Pandas que nilmtk=0.4.3 requiere, la estrategia más efectiva es recrear el entorno utilizando Python 3.7. Varias guías, incluida la de soloelectronicos.com4, sugieren explícitamente python=3.7 para una instalación más fluida de NILMTK y sus componentes más antiguos.
Desactiva y elimina el entorno actual:>conda deactivate C:\Users\carlo>conda env remove -n nilmtk-env C:\Users\carlo>conda clean --all --yes
Crea un nuevo entorno con python=3.7 y las dependencias base compatibles: Nos basaremos en la configuración recomendada en la guía de soloelectronicos.com4, que ha demostrado ser efectiva-C:\Users\carlo>conda create -n nilmtk-env python=3.7 numpy=1.19.5 pandas=1.1.5 matplotlib=3.1.3 scikit-learn=0.22.2.post1 h5py=2.10 pytables=3.6.1 networkx=2.5 pip -c conda-forge -y
Este comando crea un entorno con versiones específicas de Python y las principales bibliotecas científicas que se sabe que funcionan bien juntas para NILMTK.
pandas=1.1.5 se usa aquí porque con Python 3.7 debería ser compatible. El conflicto anterior era específico de nilmtk=0.4.3 (del canal nilmtk) exigiendo pandas<1.0. Si después de instalar nilmtk hay problemas, podríamos ajustar pandas a 0.25.3.
Activa el nuevo entorno:bashC:\Users\carlo>conda activate nilmtk-env
Instala nilmtk: Ahora que el entorno base es más compatible, la instalación de nilmtk debería ser más sencilla conda install -c nilmtk nilmtk=0.4.3 -y El requisito de pandas<1.0 de nilmtk=0.4.3 podría entrar en conflicto con el pandas=1.1.5 que acabamos de instalar. Si es así, Conda debería intentar degradar Pandas. Si no puede, entonces el pandas=1.1.5 en el comando de creación del entorno fue un mal consejo de la guía, y deberíamos haber usado pandas=0.25.3 desde el principio con Python 3.7.Si el comando anterior falla debido a un conflicto con Pandas: Intenta esto en su lugar, omitiendo pandas en el comando de creación del entorno (paso 2) y dejando que nilmtk lo traiga: # (Si estás rehaciendo desde el paso 1)# Paso 2 modificado: conda create -n nilmtk-env python=3.7 numpy=1.19.5 matplotlib=3.1.3 scikit-learn=0.22.2.post1 h5py=2.10 pytables=3.6.1 networkx=2.5 pip -c conda-forge -y# Paso 3: conda activate nilmtk-env# Paso 4: >conda install -c nilmtk -c conda-forge nilmtk=0.4.3 numpy=1.19.5 -y # Esto debería instalar nilmtk=0.4.3 y, como dependencia, pandas <1.0.
Reinstala nilm_metadata desde tu directorio local: Una vez que nilmtk y sus dependencias estén instalados, reinstala nilm_metadata desde la ubicación donde lo tienes descargado. cd RUTA_A_TU_REPOSITORIO_NILM_METADATA (nilmtk-env) C:\ruta\a\tu\repositorio\nilm_metadata>pip install -e .
Verifica la instalación completa: Ejecuta tu script de diagnóstico o prueba las importaciones manualmente en un intérprete de Python. import sys print(f"Python version: {sys.version}") # Debería ser ~3.7.x import numpy print(f"NumPy version: {numpy.__version__}") # Debería ser 1.19.5 import pandas print(f"Pandas version: {pandas.__version__}") # Debería ser <1.0 (p.ej., 0.25.3) import nilmtk print(f"NILMTK version: {nilmtk.__version__}") # Debería ser 0.4.3 import nilm_metadata print(f"nilm_metadata version: {nilm_metadata.__version__}") # Debería ser 0.2.5 from nilmtk import DataSet print("¡Importación de 'from nilmtk import DataSet' EXITOSA!")
Recrear el entorno con python=3.7 es la estrategia más prometedora en este punto, ya que la compatibilidad de pandas<1.0 con Python 3.8 parece ser el principal obstáculo con el paquete nilmtk=0.4.3 del canal nilmtk. La salida del script de diagnóstico deberia mostar:
Ruta del ejecutable de Python: c:\Users\carlo\anaconda3\envs\nilmtk-env\python.exe 'nilmtk' está instalado en este kernel: True (Versión: 0.4.0.dev1+git.303d45b) 'nilm_metadata' está instalado en este kernel: True (Versión detectada: 0.2.5) (Detalle: 'nilm-metadata' (pip style): True, 'nilm_metadata' (conda style): False) --- Intentando importar nilmtk y DataSet --- Versión de nilmtk importada: 0.4.0.dev1+git.303d45b Versión de nilm_metadata importada: 0.2.5.dev-7ed4bab from nilmtk import DataSet -- ¡ÉXITO!
Análisis de la situación :
Versiones de desarrollo locales: Estás utilizando las versiones de desarrollo de nilmtk y nilm_metadata de tus repositorios locales (instaladas probablemente con pip install -e .). Esto es evidente por las cadenas de versión que incluyen dev1+git....
Éxito en la importación: Lo más importante es que from nilmtk import DataSet funciona sin errores. Esto significa que, para estas versiones específicas que tienes, las dependencias principales (como NumPy y Pandas) están en un estado compatible.
No hay error de np.bool: El hecho de que no aparezca el error module 'numpy' has no attribute 'bool' al importar DataSet implica que la combinación de nilmtk 0.4.0.dev1+git.303d45b, la versión de pandas que tiene, y la versión de numpy que tiene, son compatibles en este aspecto.
Esto podría significar que la versión de desarrollo de nilmtk que estás usando ya no depende de partes de pandas que usaban np.bool de forma problemática, o que la versión de pandas que se instaló con ella ya maneja esto correctamente, o que la versión de numpy instalada (que podría ser más nueva, compatible con los requisitos del setup.py de tu nilmtk de desarrollo) es la que pandas espera.
Conclusión: Has logrado un entorno funcional utilizando las versiones de tus repositorios locales para nilmtk y nilm_metadata. Esto es genial porque querías usar estas versiones que sabías que funcionaban en Ubuntu. Posibles próximos pasos (opcional, solo si quieres instalar nilmtk-contrib o alinear con versiones de Conda):
Verificar versiones de NumPy y Pandas: Sería útil saber qué versiones de NumPy y Pandas están realmente activas en este entorno funcional. Puedes ejecutar:pythonimport numpy print(f"NumPy version: {numpy.__version__}") import pandas print(f"Pandas version: {pandas.__version__}") Esto te ayudará a entender qué combinación específica de estas dependencias es la que funciona con tu nilmtk 0.4.0.dev1+git.303d45b.
Instalación de nilmtk-contrib: Si ahora intentas instalar nilmtk-contrib desde tu repositorio local, el proceso podría ser más fluido si las dependencias de nilmtk-contrib (especialmente TensorFlow/Keras y sus requisitos de NumPy) son compatibles con las versiones de NumPy y Pandas que ya tienes en tu entorno.
Procede con cuidado, instalando nilmtk-contrib con pip install -e . desde su directorio.
Presta atención a si pip intenta cambiar tu versión actual de NumPy. Si lo hace, podrías volver a tener conflictos. Podrías necesitar instalar tensorflow y cvxpy (dependencias de nilmtk-contrib) por separado usando Conda, intentando encontrar versiones que sean compatibles con tu NumPy actual, y luego instalar nilmtk-contrib con pip install -e . --no-deps.
Alineación con versiones de Conda (si alguna vez lo necesitas): Si en el futuro quisieras pasar de tus versiones locales a las versiones de Conda (por ejemplo, nilmtk 0.4.3), tendrías que:
Desinstalar las versiones editables (por ejemplo, navegando a cada directorio y usando pip uninstall nilmtk, pip uninstall nilm-metadata).
Instalar las versiones de Conda (conda install -c nilmtk nilmtk=0.4.3, etc.).
Asegurarte de que NumPy y Pandas estén en versiones compatibles con nilmtk 0.4.3 (NumPy <1.20, Pandas <1.0 o ligeramente superior pero compatible).
Pero por ahora, ¡celebra que los componentes principales de NILMTK están funcionando! Ya puedes empezar a trabajar con tus datasets.Después de este extenso proceso, refinar la guía es una excelente idea. El objetivo es que sea lo más robusta y clara posible para futuras instalaciones o para otros usuarios.Aquí una versión mejorada de la guía, incorporando las lecciones aprendidas, especialmente sobre la compatibilidad de versiones y el manejo de nilmtk-contrib.
Guía para Instalar NILMTK, NILM-Metadata y NILMTK-Contrib en Windows 11
Esta guía se enfoca en usar versiones estables y conocidas de los componentes principales y aborda los problemas comunes de dependencia y las adaptaciones necesarias para nilmtk-contrib.
Requisitos Previos:
Anaconda o Miniconda: Instalado y añadido al PATH (o usar «Anaconda Prompt»).
Git para Windows: Instalado y accesible desde la línea de comandos.
Repositorios Locales (Opcional, pero asumido para nilm_metadata y nilmtk-contrib según tus preferencias):
Clona o descarga los repositorios de nilmtk-metadata y nilmtk-contrib a una ubicación conocida si planeas usar tus versiones locales.
nilmtk-contrib: git clone https://github.com/nilmtk/nilmtk-contrib.git (o la URL de tu fork/versión específica)
Fase 1: Creación y Configuración del Entorno Conda Base
Limpieza (Recomendado para una nueva máquina o después de intentos fallidos): Abre «Anaconda Prompt» (o tu terminal). conda deactivate conda env remove -n nilmtk-env conda clean --all --yes
Crear Entorno nilmtk-env con Python 3.7 y Dependencias Clave: Python 3.7 ofrece la mejor compatibilidad con las versiones de NILMTK y Pandas que buscamos. conda create -n nilmtk-env python=3.7 numpy=1.19.5 pandas=1.1.5 matplotlib=3.1.3 scikit-learn=0.22.2.post1 h5py=2.10 pytables=3.6.1 networkx=2.5 pip -c conda-forge -y
Explicación de versiones:
python=3.7: Base del entorno.
numpy=1.19.5: Requisito para nilmtk 0.4.3 (que es <1.20).
pandas=1.1.5: Versión compatible con NumPy 1.19.5 y Python 3.7.
Otras: Versiones específicas para estabilidad.
-c conda-forge: Esencial para la disponibilidad de estos paquetes.
Activar el Nuevo Entorno:conda activate nilmtk-env
Nota:nilmtk=0.4.3 del canal nilmtk podría tener una dependencia estricta de pandas<1.0. Si es así, Conda intentará degradar pandas (p.ej., de 1.1.5 a 0.25.3). Esto es aceptable y esperado.
Instalar nilm_metadata (desde tu local o GitHub):
Opción A (Desde tu repositorio local):cd RUTA_A_TU_REPOSITORIO_NILM_METADATA pip install -e .
Opción B (Desde GitHub, si no necesitas tu versión local):pip install git+https://github.com/nilmtk/nilm-metadata.git
Verifica que NumPy sea 1.19.5, Pandas sea el esperado (p.ej., 1.1.5 o <1.0), NILMTK sea 0.4.3 y nilm_metadata se importe.
Fase 3: Instalación de NILMTK-Contrib y sus Dependencias
Este es el paso más propenso a errores debido a TensorFlow.
Instalar Dependencias de nilmtk-contrib (TensorFlow, CVXPY) con Conda: El objetivo es instalar versiones compatibles que no rompan numpy=1.19.5. TensorFlow 2.4.x es una buena apuesta inicial. conda install -c conda-forge tensorflow=2.4 cvxpy keras -y
Nota sobre Keras: Aunque TensorFlow 2.x incluye Keras (tf.keras), algunas partes de nilmtk-contrib podrían intentar import keras. Instalar el paquete keras de conda-forge puede ayudar a resolver esto, ya que a menudo es un meta-paquete que se alinea con la versión de TF.
Verificar NumPy INMEDIATAMENTE después de instalar TensorFlow:python -c "import numpy; print(f'NumPy version tras TF: {numpy.__version__}')"
Si NumPy sigue siendo 1.19.5 (o <1.20): ¡Excelente! Procede.
Si NumPy se actualizó (p. ej., a 1.21.x o más): El conflicto es profundo.
Alternativa: Intenta con una versión más antigua de TensorFlow (p. ej., tensorflow=2.3 o tensorflow=2.2). Cada vez que lo hagas, verifica NumPy. Si ninguna versión de TF 2.x funciona sin romper NumPy 1.19.5, la compatibilidad es muy difícil de lograr para tu nilmtk-contrib local.
Instalar nilmtk-contrib (desde tu repositorio local): Asumiendo que NumPy está intacto, instala nilmtk-contrib sin que pip maneje sus dependencias.bashcd RUTA_A_TU_REPOSITORIO_NILMTK_CONTRIB pip install -e . --no-deps
Modificar Código de nilmtk-contrib para Importaciones de Keras/TensorFlow: Si al intentar usar nilmtk-contrib (o durante la importación) obtienes ModuleNotFoundError para módulos como tensorflow.keras.layers.core o tensorflow.keras.layers.pooling:
Edita los archivos .py de nilmtk-contrib que causan el error.
Cambia las importaciones obsoletas a las rutas modernas. Ejemplos:
from tensorflow.keras.layers.core import Activation -> from tensorflow.keras.layers import Activation
from tensorflow.keras.layers.pooling import AveragePooling1D -> from tensorflow.keras.layers import AveragePooling1D
Y así sucesivamente para otras capas (Dense, Conv2D, LSTM, etc.). Todas suelen estar directamente bajo tensorflow.keras.layers.
Guarda los cambios. Necesitarás hacer esto para cada importación obsoleta que encuentres.
Prueba de Importación Completa: Abre un intérprete de Python o un Jupyter Notebook usando el kernel nilmtk-env.python
import numpy
print(f"NumPy: {numpy.__version__}")
import pandas
print(f"Pandas: {pandas.__version__}")
import tensorflow
print(f"TensorFlow: {tensorflow.__version__}")
import nilm_metadata
print(f"nilm_metadata: {nilm_metadata.__version__}")
import nilmtk
print(f"NILMTK: {nilmtk.__version__}")
from nilmtk import DataSet
print("NILMTK DataSet importado.")
# Intenta importar un componente de nilmtk_contrib
try:
from nilmtk_contrib.disaggregate import CO # O cualquier otro que uses
print("Componente de nilmtk_contrib importado con éxito.")
except Exception as e_contrib:
print(f"Error al importar de nilmtk_contrib: {e_contrib}")
print("Revisa si necesitas hacer más correcciones de importación en nilmtk_contrib o si hay otro problema de dependencia.")
print("¡Configuración base de NILMTK lista!")
Consideraciones Adicionales:
Rutas de Repositorios Locales: Reemplaza RUTA_A_TU_REPOSITORIO_... con las rutas absolutas correctas.
Errores de Compilación (poco probables con este enfoque): Si algún paquete necesita compilación y falla (p. ej., pytables), asegúrate de tener las herramientas de compilación de C de Microsoft instaladas (Build Tools for Visual Studio).
Flexibilidad de nilmtk-contrib: Si el conflicto de TensorFlow/NumPy es insuperable, la única opción podría ser:
Encontrar/adaptar una versión de nilmtk-contrib compatible con TensorFlow más antiguo (y por ende, NumPy 1.19.5).
Actualizar nilmtk a una versión más moderna (de desarrollo) que funcione con NumPy más nuevo, y luego adaptar nilmtk-contrib a ese entorno. Esto es más complejo y nos devuelve a los problemas iniciales.
Esta guía intenta ser lo más determinista posible. La clave es el control estricto de las versiones de las dependencias críticas (Python, NumPy, Pandas, TensorFlow) a través de Conda antes de introducir los paquetes locales con pip.




Debe estar conectado para enviar un comentario.