Es realmente sorprendente hasta donde podemos llegar con una Raspberry Pi , donde probablemente la única limitación la pongamos nosotros mismos, pues esta versátil placa esta muy capacitada para tareas tan complejas , las cuales hacen tan solo unos años hubiera sido impensables que se pudieran realizar en un hw como el de esta placa.
Como ejemplo de multi-procesamiento vamos a ver en este post cómo Bob Bam Mantell , montó un monitor de bebé con una Raspberry Pi recogiendor los datos en Splunk, mediante un lector de registro y una herramienta de análisis, programando los datos de una manera significativa . Como resultado de este trabajo tendremos todas las medidas en un único tablero de mandos donde podremos controlar los patrones del sueño, temperatura y humedad.
Para construir este monitor necesitamos:
- Raspberry Pi 3 con Raspbian instalado
- Módulo Pi cámara con infrarrojo
- Sensor Temperatura y humedad DHT22
- Un servidor de host Splunk – para el tablero de informes, Linux Centos, pero se puede ejecutar en Windows para Mac, así
- El software Splunk Universal promotor para Raspberry Pi
Con cierta supervisión y alertas deberíamos ser capaces de mantener la comodidad óptima del bebé, pero antes debemos instalar Raspbian. Esta versión se descarga a partir de una nueva imagen descargada a partir del sitio oficial Raspbian ,
En la url de descarga podrá apreciar en la imagen de abajo , se mantienen tanto la imagen de la versión previa mínima (Lite) o la nueva versión Stretch para escritorio:
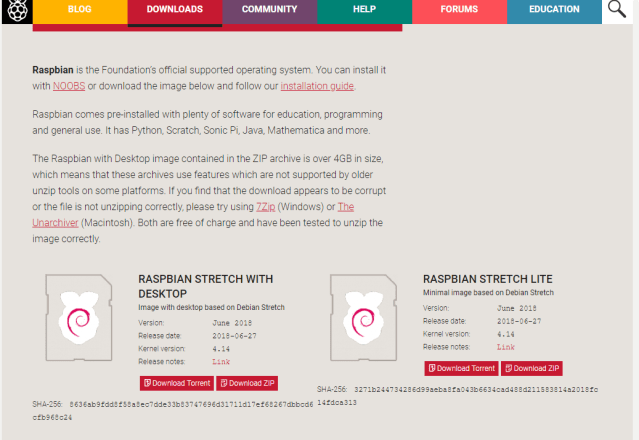
Lógicamente si la SD es suficiente grande , lo interesante es descargar la primera en lugar de la versión mínima
Una vez decidida, descargue la imagen correspondiente en su ordenador y siga los siguientes pasos:
- Inserte la tarjeta SD en el lector de tarjetas SD de su ordenador comprobando cual es la letra de unidad asignada. Se puede ver fácilmente la letra de la unidad, tal como G :, mirando en la columna izquierda del Explorador de Windows.
- Puede utilizar la ranura para tarjetas SD, si usted tiene uno, o un adaptador SD barato en un puerto USB.
- Descargar la utilidad Win32DiskImager desde la página del proyecto en SourceForge como un archivo zip; puede ejecutar esto desde una unidad USB.
- Extraer el ejecutable desde el archivo zip y ejecutar la utilidad Win32DiskImager; puede que tenga que ejecutar esto como administrador. Haga clic derecho en el archivo y seleccione Ejecutar como administrador.
- Seleccione el archivo de imagen que ha extraído anteriormente de Raspbian.
- Seleccione la letra de la unidad de la tarjeta SD en la caja del dispositivo. Tenga cuidado de seleccionar la unidad correcta; si usted consigue el incorrecto puede destruir los datos en el disco duro de su ordenador! Si está utilizando una ranura para tarjetas SD en su ordenador y no puede ver la unidad en la ventana Win32DiskImager, intente utilizar un adaptador SD externa.
- Haga clic en Escribir y esperar a que la escritura se complete.
- Salir del administrador de archivos y expulsar la tarjeta SD.
- Ya puede insertar la SD en su Raspberry Pi en el adaptador de micro-sd , conectar un monitor por el hdmi , conectar un teclado y ratón en los conectores USB, conectar la con un cable ethernet al router conectividad a Internet y finalmente conectar la alimentación para comprobar que la Raspberry arranca con la nueva imagen
La versión previa basada en Raspbian Jessie ( Debian8 ) ya incluía características y aplicaciones bastante interesantes así como algunos cambios más sutiles en el diseño del sistema, como por ejemplo,al iniciar ahora su Raspberry Pi que la pantalla inicial cambiara mostrando una imagen mas moderna .También incluía algunas aplicaciones como un navegador integrado , el software de RealVNC, para acceder a la Pi desde un escritorio remoto , wallpapers nuevos para decorar el fondo de escritorio de su Raspberry Pi,etc .
Ahora lo mas importante de esta nueva actualización es sin duda la subida de versión hacia Debian 9 ( recordemos que la versión anterior era Debian 8) trayendo ademas un gran número de cambios y mejoras internas respecto a Debian 8 destacando quizás ademas de la subida de version el incluir un nuevo asistente de configuración que será mostrado en el primer inicio, lo cual ayudará a los recién llegados a configurar el sistema Raspbian a su gusto sin tener que buscar los distintos paneles de ajustes.Por supuesto este asistente de configuración se ejecutará de forma automática en el primer inicio del sistema, permitiendo que los usuarios escojan su país, lenguaje, huso horario, configuren un perfil con contraseña, agreguen una red Wi-Fi e incluso instalen actualizaciones disponibles.
“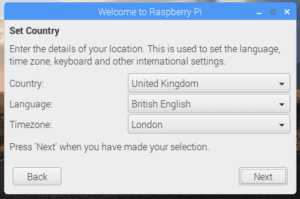
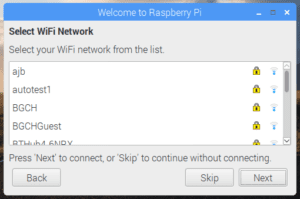
Una vez hayamos arrancado la Rasberry Pi con Raspbian, como vemos en las pantallas anteriores seguiremos el asistente de inicio donde configuramos la red wifi a la que nos conectaremos desde la Raspberry Pi.
Asimismo necesitamos permitir tanto los pines de GPIO como el de la cámara nativa
Además debemos confirmar que puede conectar mediante el programa SSH para acceder remotamente una vez instalado
Por ultimo actualizaremos el so ejecutando el comando de actualización:
sudo apt-get update
Una vez hecho esto, ya tendremos un sistema operativo base por lo que empezaremos instalando la camara NoIR
Camara NoIr
El NoIR de Pi, es la versión de visión nocturna de la cámara, que NO tiene filtro ( es decir ‘Sin Infra rojo’) , lo que significa, si usted tiene una fuente de luz infrarroja, por la noche, la cámara puede ver en la oscuridad. Puesto que los bebés suelen descansar por la noche (con suerte), ese el motivo de necesitar una cámara infrarroja para no despertarlo por lo que si usted quiere imágenes en color o prevea usar la cámara con luz normal no utilice esta cámara. El modulo de cámara de Pi de infrarrojos tiene un mayor rendimiento que las cámaras USB, por lo que lo ideal es usar cámaras del tipo compatibles con Raspberry Pi con interfaz .
Estos son los pasos para instalar la cámara Noir especifica para su uso , con la Raspberry Pi 3
Localice el puerto de la cámara y conecte la cámara:

Poner en marcha la Raspberry Pi 3
Abra la Herramienta de configuración de frambuesa Pi desde el menú principal

Asegúrese de que está activado el software de la cámara
:
Si no está activado, habilítelo y reinicie su Pi para comenzar. Es decir resumidamente; con la Raspberry Pi apagada, debe conectar el módulo de la cámara al puerto de la cámara de la Raspberry Pi, ahora encienda el Pi y asegúrese de que se activa el software.
Alternativamente la activación de la cámara se puede hacer eescribiendo los siguientes comandos:
sudo raspi-config
Select
Enable camera
Seleccione entrar, cuando haya terminado, le pedirá que reinicie siguiendo las instrucciones.
Conexión de un sensor DHT22
DHT11 y DHT22 son dos modelos de una misma familia de sensores, que permiten realizar la medición simultánea de temperatura y humedad usando ademas un único hilo para comunicar los datos vía serie, para lo cual ambos disponen de un procesador interno que realiza el proceso de medición, proporcionando la medición mediante una señal digital, por lo que resulta muy sencillo obtener la medición desde un microprocesador
Ambos son similares ( DHT11 presenta una carcasa azul , mientras que el sensor DHT22 es blanco) compartiendo además los mismos pines disponiendo de 4 patillas, de las cuales usaremos sólo 3: Vcc, Output y GND. Como peculiaridad ,la salida la conectaremos a una entrada digital , pero necesitaremos poner una resistencia de 10K entre Vcc y el Pin Output.
El DHT11 puede medir temperaturas entre 0 a 50, con una precisión de 2ºC, humedad entre 20 a 80%, con precisión del 5% y con una a frecuencia de muestreo de 1 muestras por segundo (1 Hz)
- Medición de temperatura entre -40 a 125, con una precisión de 0.5ºC
- Medición de humedad entre 0 a 100%, con precisión del 2-5%.
- Frecuencia de muestreo de 2 muestras por segundo (2 Hz)
Destacar que este tipo de sensores de temperatura ( y, aún más, los sensores de humedad) , son sensores con elevada inercia y tiempos de respuesta elevados. Es decir, al “lentos” para reflejar los cambios en la medición.

Conectar el DHT22 a una Raspberry Pi es sencillo, simplemente alimentamos al sensor a través de los pines GND y Vcc del mismo. Por otro lado, conectamos la salida Output a una entrada digital . Necesitaremos poner una resistencia de 10K entre Vcc y el Pin Output , tarea que suele hacerse mediante un jumper en la propia placa del sensor
En resumen estas son las conexiones:
- Conecte el NARANJA( masa) al Pin 6 de las RP (GND)
- Conecte el ROJO(vcc) al Pin 1 dela Rp
- Conecte el MARRON(output) al Pin 22 de la Rp ( GPIO25 )
Los sensores DHT22 usan su propio sistema de comunicación bidireccional mediante un único hilo , empleando señales temporizadas por lo que en general, lo normal es que empleemos una librería existente para simplificar el proceso. Para escribir el software, que puede leer el sensor, vamos a necesitar un par de cosas. Primero asegúrese de que el compilador ya está instalado con el común:
sudo apt-get install git-core
Necesitaremos clonar desde el git el modulo WiringPi con el comando
git clone git://git.drogon.net/wiringPi
Ahora vaya al directorio creado y compilaremos este modulo
cd wiringPi git pull origin
cd wiringPi ./build
Leer datos desde el sensor DHT22
Utilizado este sitio como una guía para escribir el software que será capaz de leer el Sensor. Aconsejaron que necesitamos utilizar un programa en C para asegurar que siempre lee el sensor. El código original has ido modificado por Bam Bam Mantell para evitar bucles y mejorar el formato de las lecturas mejores para lectura en Splunk pues a Splunk le gusta el formato nombre_variable = valor para identificar fácilmente en el registro del log
Abra su editor de texto favorito linux y cree un archivo dat.c
Inserte este código en ella el archivo dht.c
<p>/*<br> * dht.c:
* read temperature and humidity from DHT11 or DHT22 sensor
*/
#include
#include
#include
#include
#define MAX_TIMINGS 85
#define DHT_PIN 3 /* GPIO-22 */
int data[5] = { 0, 0, 0, 0, 0 };
void read_dht_data()
{
uint8_t laststate = HIGH;
uint8_t counter = 0;
uint8_t j = 0, i;
data[0] = data[1] = data[2] = data[3] = data[4] = 0;
/* pull pin down for 18 milliseconds */
pinMode( DHT_PIN, OUTPUT );
digitalWrite( DHT_PIN, LOW );
delay( 18 );
/* prepare to read the pin */
pinMode( DHT_PIN, INPUT );
/* detect change and read data */
for ( i = 0; i < MAX_TIMINGS; i++ )
{
counter = 0;
while ( digitalRead( DHT_PIN ) == laststate )
{
counter++;
delayMicroseconds( 1 );
if ( counter == 255 )
{
break;
}
}
laststate = digitalRead( DHT_PIN );
if ( counter == 255 )
break;
/* ignore first 3 transitions */
if ( (i >= 4) && (i % 2 == 0) )
{
/* shove each bit into the storage bytes */
data[j / 8] <<= 1;
if ( counter > 16 )
data[j / 8] |= 1;
j++;
}
}
/*
* check we read 40 bits (8bit x 5 ) + verify checksum in the last byte
* print it out if data is good
*/
if ( (j >= 40) &&
(data[4] == ( (data[0] + data[1] + data[2] + data[3]) & 0xFF) ) )
{
float h = (float)((data[0] << 8) + data[1]) / 10;
if ( h > 100 )
{
h = data[0]; // for DHT11
}
float c = (float)(((data[2] & 0x7F) << 8) + data[3]) / 10;
if ( c > 125 )
{
c = data[2]; // for DHT11
}
if ( data[2] & 0x80 )
{
c = -c;
}
float f = c * 1.8f + 32;
printf( "Humidity=%.1f Temperature=%.1f\n", h, c );
}else {
printf( "Data not good, skip\n" );
}
}
int main( void )
{
if ( wiringPiSetup() == -1 )
exit( 1 );
read_dht_data();
return(0);
}</p>
El código anterior del archivo dot.c ahora necesita ser compilado, para ello escriba el comando
cc -Wall dht.c -o dht -lwiringPi
A continuación, puede ejecutar el programa con el comando
sudo ./dat
Usted debe ver algunas salida, lo cual sólo funcionará si el sensor está conectado correctamente y el código está trabajando. Se le mostrará una salida similar a la siguiente:
Humidity=66.9 Temperature=18.3
........
Necesitamos llegar a utilizar Splunk para que lea archivos de registro. Así que los datos que estamos recogiendo de los sensores vamos a escribirlos en un archivo de registro, para que Splunk pueda monitorear los cambios.
Primero vamos a crear un directorio en la carpeta de inicio pi, llamada registros, para almacenar los archivos :
mkdir /home/pi/logs
Ahora, en el directorio cree un archivo script de bash
touch /home/pi/temperature_script.sh
Editar el archivo anterior con su editor de texto favorito ( vi ) e inserte este código:
#! /bin/bash log="/home/pi/logs/" #run the client "/home/pi/dht" > temperature.txt OUTPUT=`cat temperature.txt` # Write values to the screen TEMPERATURE=`echo "$OUTPUT"` # Output data to a log file echo "$(date +"%Y-%m-%d %T" ): ""$TEMPERATURE" >>"$log"temperature.log
Para automtizar la ejecución de este script vamos a utilizar Cron en la Raspberry Pi para ejecutar el trabajo, lo cual nos dará la flexibilidad de tiempo ejecutar cada uno de nuestros scripts
El sensor de temperatura requiere acceso de sudo (raíz) para ejecutarlos, así que tenemos que ejecutar el sudo crontab, para ello escriba el comando
sudo crontab -e
Agregue la línea en el archivo;
*/5 * * * * /home/pi/temperature_script.sh
Esto ejecutará el programa de temperatura cada cinco minutos.
A partir de este momento ,su registro debe empezar a mostrarse como en la siguiente imagen:.
Usted puede comprobar en el archivo de registro como se escriben nuevos datos con el comando
cat /home/pi/logs/temperature.log
Configurar la cámara web
Hemos habilitado anteriormente la cámara pero ahora vamos a instalar algun software para usarlo realmente , isa que vamos a configurar la cámara web.
El software se llama motion, y puede ejecutar un servidor web, para su visualización, detección de movimiento y marcos de registro y fotos. En esta configuración, se ve apagar pues no se cuenta con un montón de espacio para archivos de vídeo, así que se ejecutara para el control y utilizaremos el registro para el seguimiento de movimientos de sueño.
La instalación por defecto de movimiento no tiene soporte para la cámara de Pi. Así que estamos usando una compilación especial para trabajar con él. La guía completa está aquí.
Escriba el comando
sudo apt-get install motion
Ahora descargue este compilacioon especial
wget href="https://www.dropbox.com/s/0gzxtkxhvwgfocs/motion-mmal.tar.gz
Ahora descomprimir el sw:
tar zxvf motion-mmal.tar.gz
Abra el archivo config del movimiento mmalcam.conf con su editor de texto favorito y actualize algunos de los ajustes, daemon para que se ejecute en background, aumento de altura video y video de calidad, el archivo de registro a nuestra ubicación y aumentar el nivel de registro para eventos.
daemon on width=1280 height=720 logfile /home/pi/logs/motion.log log_level 7
Apague el host local para que puede conectarse a él remotamente.
stream_localhost off
Text_Left es el texto que sale en el feed_
text_left Baby's Room %t
Hay una opción para nombre de usuario y contraseña para validarse si se conecta desde internet. De lo contrario dejarlo como está.
Guarde el archivo y empiece a detectar el movimiento con el comando
sudo ./motion -c motion-mmalcam.conf
Ahora podrá conectarse a la corriente de la web de la cámara
El navegador web, preferentemente Chrome o Firefox en
Y debe recibir un alimento vivo. También puede comprobar el registro de movimiento y ver si se registran eventos.
cat /home/pi/logs/motion.log
Estos eventos de movimiento son lo que vamos a contar para detectar movimientos de sueño.
Si desea apagar el LED rojo, hacer más discreta la cámara, editar la configuración de arranque
sudo vim /boot/config.txt
Agregue estas líneas, y después de reiniciar no vino en.
# Turn off camera Red LED disable_camera_led=1
Instalar Splunk y promotor Universal
No vamos a entrar en mucho detalles sobre el servidor de Splunk. Se puede instalar en cualquier sistema operativo que se desee (Mac OSX , Linux,etc ). Tan sólo tiene que seguir la Guía de Splunk. Una vez tenga instalado Splunk, asegurase que se consiguió al menos una conexión receptora. El puerto predeterminado es 9997. Una vez que esto se realiza, y suponiendo que no hay cortafuegos bloqueará, puede configurar un promotor Universal para enviar datos.
Ir a Splunk y obtener el promotor universal para Linux. Necesita para obtener la versión para ARM .Siga las instrucciones en Splunk.
Ejecute al instalador de Splunk cuando tenga el archivo
tar xvzf splunkforwarder-<…>-Linux-arm.tgz -C /opt
Configurar el promotor para apuntar a su servidor de Splunk.
Editar el archivo en
sudo vim opt/splunkforwarder/etc/system/local/outputs.conf
Si su servidor es 192.168.0.10. tendrá que poner:
[tcpout:default-autolb-group] server = 192.168.0.10:9997
Guardar y cerrar, ya puede comenzar a promotor de splunk
/splunkforwarder/bin/splunk start
No añadir un motor a nuestra ubicación archivo de registro
sudo /opt/splunkforwarder/bin/splunk add monitor /home/pi/logs
Nuestro promotor de Splunk ahora debe comenzar a recoger registros en ese directorio. Usted puede comprobar el registro de transportista de Splunk si su no va a verificar los problemas de
sudo cat /opt/splunkforwarder/var/log/splunk/splunkd.log
Crear un panel de control
Ahora inicie sesión en el servidor de Splunk y confirmar si los datos está llegando.
Realizar una búsqueda de eventos
index=main source="/home/pi/logs/temperature.log"
Si se cambia a modo detallado de Splunk, deben identificar las variables de temperatura y humedad. Ahora usted puede ver a través de una búsqueda de Splunk, como;
index=main source="/home/pi/logs/temperature.log"| timechart max(Temperature)
Puede crear una línea para la temperatura, ejecutar el debajo de buscar y salvar a un tablero de instrumentos nuevo, darle un nombre «Baby Monitor»
index=main Temperature source="/home/pi/logs/temperature.log" | stats first(Temperature)
Y otra vez para humedad, seleccione Visualización, manómetro Radial. Guardar como un tablero panel, el Panel existente, «Baby Monitor»
index=main Humidity source="/home/pi/logs/temperature.log" | stats first(Humidity)
Si el registro de movimiento es ingresado con éxito debemos tener eventos para él en Splunk ahora. Si buscamos eventos detectados, nos deberíamos volver resultados
index=main detected
Si tenemos resultados las podemos ver. Vamos a ver el volumen de eventos. Esto nos mostrará cuánto movimiento se detectó en el tiempo.
La consulta se ve así
index=main detected | timechart count span=5min
Combinando estas búsquedas y agregar a un panel de control podemos construir una gran cantidad de métricas útiles en interior y las temperaturas exteriores y movimientos del bebé.
La consulta para el interior y temperatura exterior juntos se ve así:
index=main source="/home/pi/logs/outside_weather.log" OR source="/home/pi/logs/temperature.log" | timechart max(Temperature) AS "Baby's Room" max(Outside_Weather) AS "Outside" span=30min
Via instructables

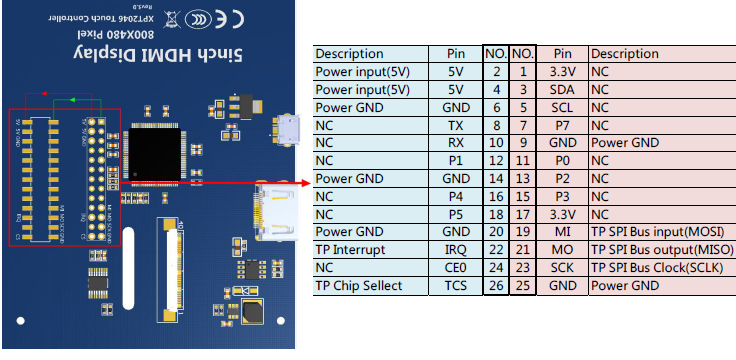
 .
. Conecte ahora la pantalla LCD y la Raspberry Pi con el adaptador HDMI espacial .Observe que debe encajar el puente hdmi -hdmi entre ambas placas , lo cual ademas le dará rigidez mecánica al montaje
Conecte ahora la pantalla LCD y la Raspberry Pi con el adaptador HDMI espacial .Observe que debe encajar el puente hdmi -hdmi entre ambas placas , lo cual ademas le dará rigidez mecánica al montaje


Debe estar conectado para enviar un comentario.