EL NILM o Non-Intrusive Load Monitoring, es decir la desagregación no intrusiva de la demanda . es una técnica computacional para la estimación del consumo individual de diversos dispositivos utilizando para ello la lectura agregada de un único medidor de energía (Smart Meter, SM).
Gracias a las ventajas en cuanto instalación , coste e implementación, éste concepto ha tomado relevancia en los últimos años en el ámbito de las Smart Grids, al aportar una estimación de los hábitos de consumo de los clientes sin la necesidad de un despliegue masivo de contadores inteligentes en cada punto de consumo.
Tal es el interés por esta técnica que desde el 2010 , el número de publicaciones científicas referentes al NILM se ha incrementado exponencialmente sin duda condicionado por los beneficios de esta técnica en el marco de las redes inteligentes de energía como por ejemplo la posibilidad de generar facturas de electricidad que muestren en detalle el consumo de los electrodomésticos utilizando solamente las lecturas de un SM
Asimismo, existen aplicaciones de Energy Management System (EMS) en conjunto con NILM, las cuales pueden ser compatible con los programas de respuesta a la demanda o Demand Response (DR) de las compañías de electricidad.
Por otro lado, algunos plantean la posibilidad de usar NILM para detectar averías en los dispositivos cuando se presenta un comportamiento anómalo en las mediciones desagregadas.
Es así como NILM se presenta como una valiosa herramienta para reducir el consumo de energía, tanto así que algunos afirman que es el “santo grial de la eficiencia energética”.
En este contexto vamos a ver una herramienta o toolkit open software llamado NILMTK que nos va a ayudar a comparar algoritmos para implementar la desagregación ( ademas particularmente no contempla un uso diferente a este)
Para el análisis de la desagregación , necesitamos recolectar datos del consumo centralizado , lo cual nos va permitir a creación de un nuevo dataset el cual puede ser analizado usando las funciones de NILMTK lo que permite, por ejemplo, visualizar los datos de potencia en un determinado periodo u obtener estadísticas de energía del dataset.
Posteriormente, en la etapa de preprocesamiento se toman decisiones en línea con los análisis realizados, con el objetivo de preparar correctamente los datos para del entrenamiento de los modelos de desagregación. Básicamente, el entrenamiento de un modelo consiste en enseñarle a reconocer por separado las características de los dispositivos para luego identificarlos dentro de una señal agregada. El entrenamiento contempla el uso de los algoritmos Combinatorial Optimization (CO) y Factorial Hidden Markov Model (FHMM).

Photo by Dimitry Anikin on Pexels.com
HDF5
HDF5 es un formato de datos jerárquico que se usar en el NILMTK como fuente datos basado en HDF4 y NetCDF (otros dos formatos de datos jerárquicos).El formato de datos jerárquico, versión 5 (HDF5), es un formato de archivo de código abierto que admite datos grandes, complejos y heterogéneos. HDF5 utiliza una estructura similar a un «directorio de archivos» que le permite organizar los datos dentro del archivo de muchas formas estructuradas diferentes, como lo haría con los archivos en su computadora. El formato HDF5 también permite la incrustación de metadatos, lo que lo hace autodescriptivo .

Estructura jerárquica: un directorio de archivos dentro de un archivo
El formato HDF5 se puede considerar como un sistema de archivos contenido y descrito en un solo archivo. Piense en los archivos y carpetas almacenados en su computadora. Es posible que tenga un directorio de datos con algunos datos de temperatura para varios sitios de campo. Estos datos de temperatura se recopilan cada minuto y se resumen cada hora, día y semana. Dentro de un archivo HDF5, puede almacenar un conjunto de datos similar organizado de la misma manera que podría organizar archivos y carpetas en su computadora. Sin embargo, en un archivo HDF5, lo que llamamos «directorios» o «carpetas» en nuestras computadoras, se llaman groupsy lo que llamamos archivos en nuestra computadora datasets.
2 Términos importantes de HDF5
- Grupo: un elemento similar a una carpeta dentro de un archivo HDF5 que puede contener otros grupos O conjuntos de datos dentro de él.
- Conjunto de datos: los datos reales contenidos en el archivo HDF5. Los conjuntos de datos se almacenan a menudo (pero no es necesario) dentro de grupos en el archivo.
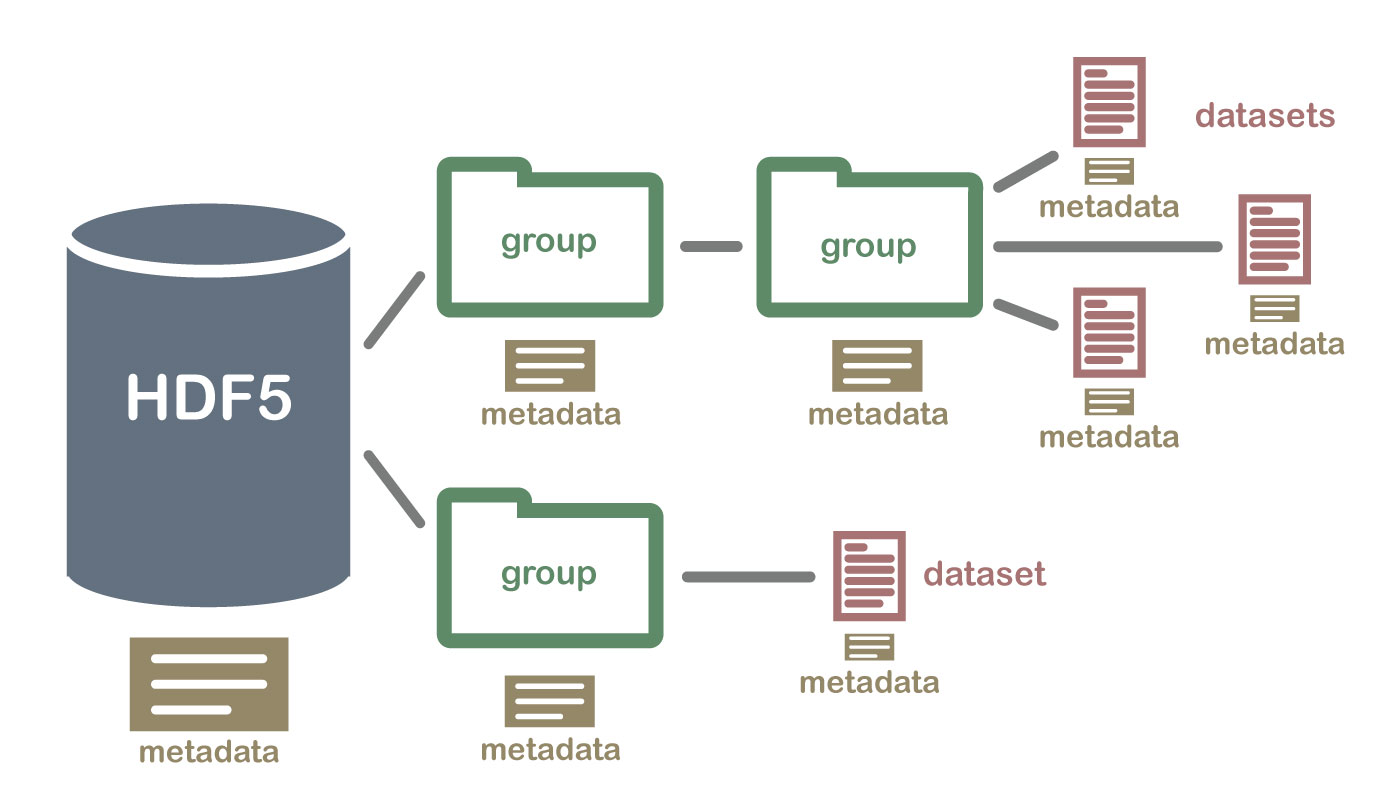
Un archivo HDF5 que contiene conjuntos de datos podría estructurarse así:
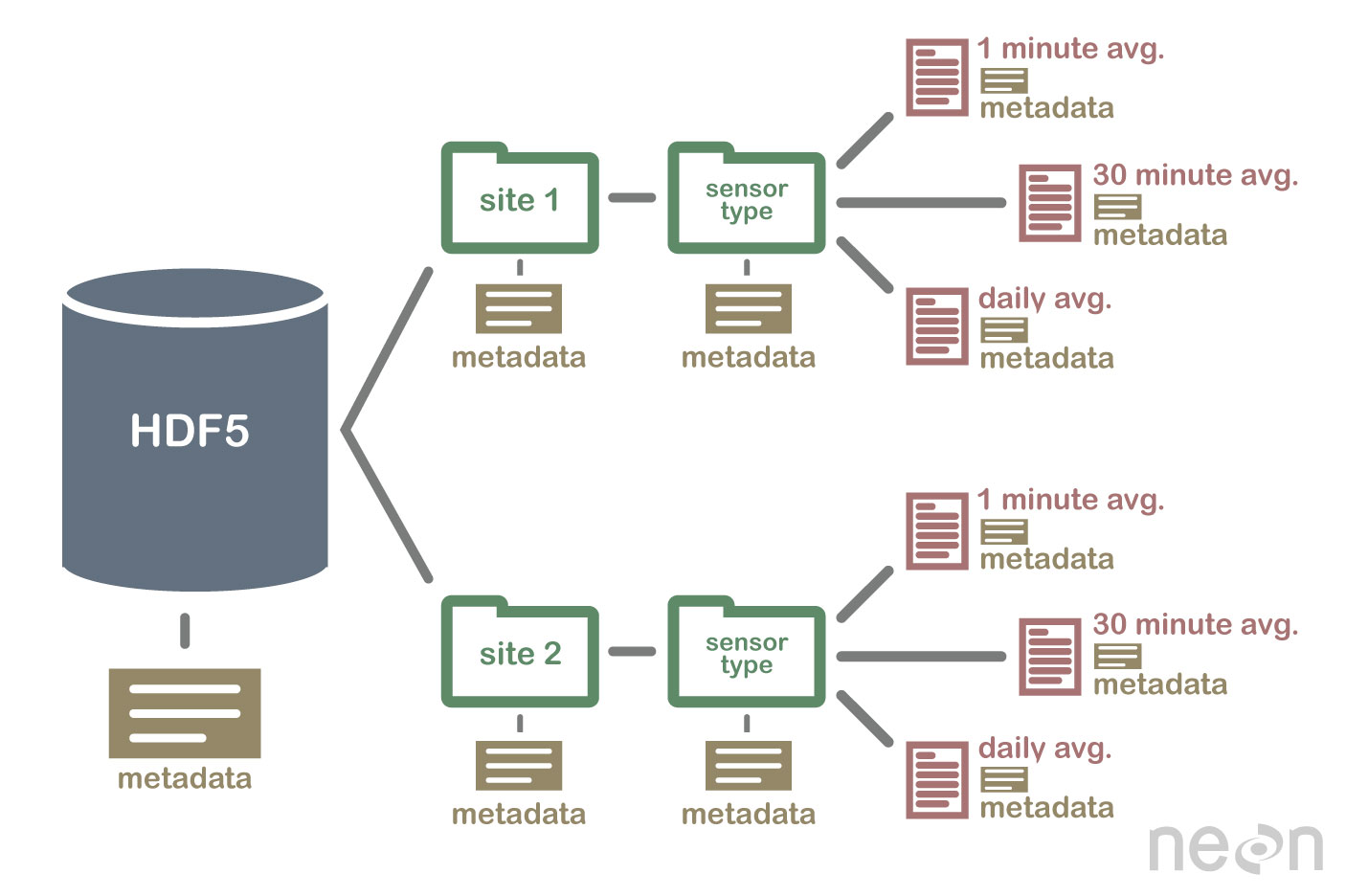
HDF5 es un formato autodescriptivo
El formato HDF5 es autodescriptivo. Esto significa que cada archivo, grupo y conjunto de datos puede tener metadatos asociados que describen exactamente cuáles son los datos. Siguiendo el ejemplo anterior, podemos incrustar información sobre cada sitio en el archivo, como por ejemplo:
- El nombre completo y la ubicación X, Y del sitio.
- Descripción del sitio.
- Cualquier documentación de interés.
De manera similar, podríamos agregar información sobre cómo se recopilaron los datos en el conjunto de datos, como descripciones del sensor utilizado para recopilar los datos de temperatura. También podemos adjuntar información, a cada conjunto de datos dentro del grupo de sitios, sobre cómo se realizó el promedio y durante qué período de tiempo están disponibles los datos.
Un beneficio clave de tener metadatos adjuntos a cada archivo, grupo y conjunto de datos es que esto facilita la automatización sin la necesidad de un documento de metadatos separado (y adicional). Usando un lenguaje de programación, como R o Python, podemos obtener información de los metadatos que ya están asociados con el conjunto de datos y que podríamos necesitar para procesar el conjunto de datos.
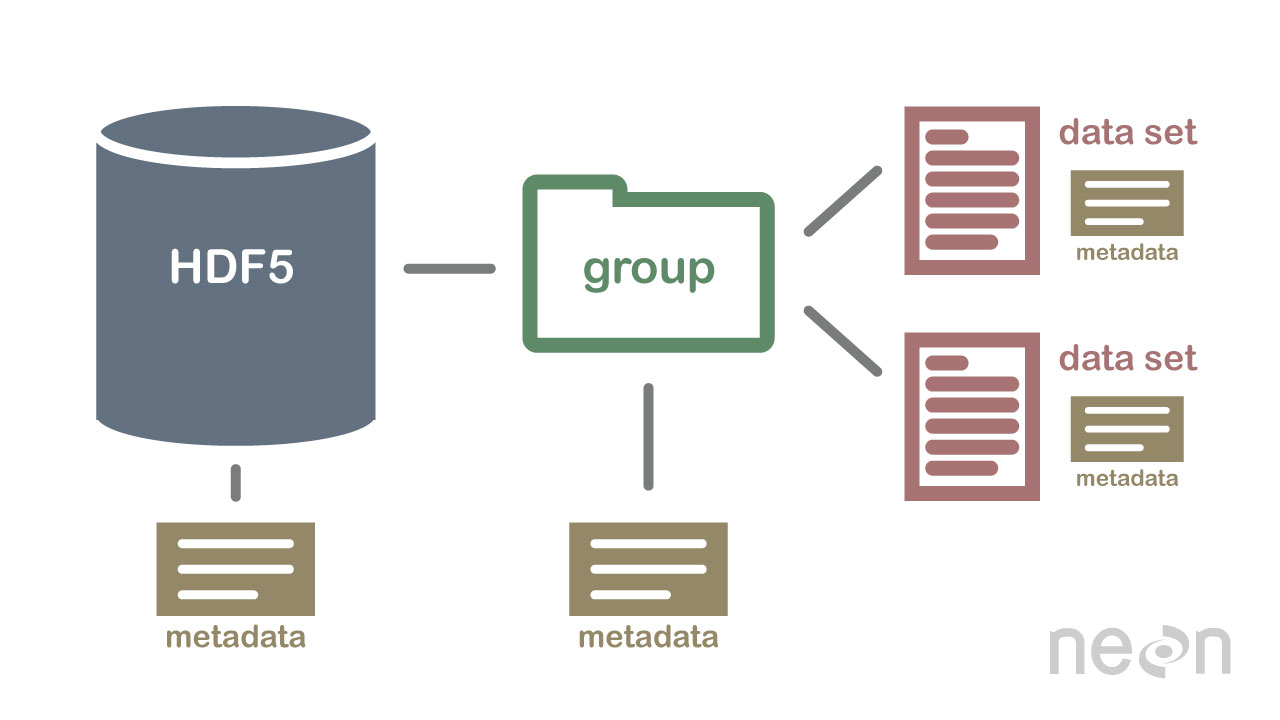
Subconjunto comprimido y eficiente
El formato HDF5 es un formato comprimido. El tamaño de todos los datos contenidos en HDF5 está optimizado, lo que reduce el tamaño general del archivo. Sin embargo, incluso cuando están comprimidos, los archivos HDF5 a menudo contienen grandes volúmenes de datos y, por lo tanto, pueden ser bastante grandes. Un atributo poderoso de HDF5 es data slicingmediante el cual se puede extraer un subconjunto particular de un conjunto de datos para su procesamiento. Esto significa que no es necesario leer el conjunto de datos completo en la memoria (RAM); muy útil para permitirnos trabajar de manera más eficiente con conjuntos de datos muy grandes (gigabytes o más).
Almacenamiento de datos heterogéneos
Los archivos HDF5 pueden almacenar muchos tipos diferentes de datos dentro del mismo archivo. Por ejemplo, un grupo puede contener un conjunto de conjuntos de datos para contener datos enteros (numéricos) y de texto (cadenas). O bien, un conjunto de datos puede contener tipos de datos heterogéneos (por ejemplo, tanto texto como datos numéricos en un conjunto de datos). Esto significa que HDF5 puede almacenar cualquiera de los siguientes (y más) en un archivo:
- Datos de temperatura, precipitación y PAR (radiación fotosintética activa) para un sitio o para muchos sitios
- Un conjunto de imágenes que cubren una o más áreas (cada imagen puede tener asociada información espacial específica, todo en el mismo archivo)
- Un conjunto de datos espaciales multi o hiperespectral que contiene cientos de bandas.
- Datos de campo para varios sitios que caracterizan insectos, mamíferos, vegetación y clima.
- Un conjunto de imágenes que cubren una o más áreas (cada imagen puede tener asociada información espacial única)
- ¡Y mucho más!
Formato abierto
El formato HDF5 es abierto y de uso gratuito. Las bibliotecas de apoyo (y un visor gratuito) se pueden descargar desde el sitio web de HDF Group . Como tal, HDF5 es ampliamente compatible con una gran cantidad de programas, incluidos lenguajes de programación de código abierto como R y Python, y herramientas de programación comerciales como Matlaby IDL. Los datos espaciales que se almacenan en formato HDF5 se pueden utilizar en los programas de SIG y de imagen que incluyen QGIS, ArcGISy ENVI.
Beneficios de HDF5
- Autodescripción Los conjuntos de datos con un archivo HDF5 son autodescriptivos. Esto nos permite extraer metadatos de manera eficiente sin necesidad de un documento de metadatos adicional.
- Admite datos heterogéneos : un archivo HDF5 puede contener diferentes tipos de conjuntos de datos.
- Admite datos grandes y complejos : HDF5 es un formato comprimido que está diseñado para admitir conjuntos de datos grandes, heterogéneos y complejos.
- Admite la división de datos: la «división de datos», o la extracción de partes del conjunto de datos según sea necesario para el análisis, significa que los archivos grandes no necesitan leerse por completo en la memoria o RAM de la computadora.
- Formato abierto: soporte amplio en las muchas herramientas : debido a que el formato HDF5 es abierto, es compatible con una gran cantidad de lenguajes y herramientas de programación, incluidos lenguajes de código abierto como R y
Pythonherramientas SIG abiertas comoQGIS.E
Instalación del NILTK
Descargue e instale Conda
Los entornos virtuales hacen que la organización de paquetes de Python sea pan comido. Además, el proyecto NILMTK ofrece varias versiones de Conda Forge. Primero, consiga Anaconda aquí. Luego, abra una ventana de terminal e inicie la instalación desde la línea de comando:
Dowloads cd /
bash Anaconda3-2020.11-Linux-x86_64.sh -uSe le guiará a través de varios pasos. Instale Conda y pruebe la instalación ejecutando el comando conda en el símbolo del sistema:
condaEn caso de que el comando conda resulte en «un error de intérprete incorrecto» (es decir, no existe tal error de archivo o directorio), aplique la siguiente solución:
cd / inicio / usuario /
nano .bashrcagregue la línea:
export PATH = ~ / anaconda3 / bin: $ PATHGuarde los cambios en el archivo y, finalmente, ejecute el comando:
source .bashrcFelicidades, acaba de instalar Conda.
Instalación de NILMTK
Abra una ventana de terminal, cree un nuevo entorno de Conda y actívelo:
conda create --name nilmtk-env
conda activate nilmtk-envSi aún no está presente en su instalación de Conda, agregue el conda-forge a la lista de canales:
conda config --add channels conda-forgeFinalmente, instale la última versión de NILMTK de conda-forge :
conda install -c nilmtk nilmtk=0.4.3Observe que el signo igual no lleva espacios(piense estamos usando Python.
La ejecución del comando puede tardar un rato. Mientras tanto, consulte otros paquetes en Forge de NILMTK .
Como puede experimentar algunos problemas posteriores a la instalación con NILMTK y Matplotlib., para s olucionarlos, aplique el comando:
conda install matplotlib=3.3.2Agregar un kernel de Jupyter
Básicamente, NILMTK ahora está instalado en su ordenador. El siguiente paso involucra los cuadernos de Jupyter. Trabajar con Jupyter abre muchas posibilidades y se dice que es una herramienta imprescindible. Por lo tanto, agregue el entorno NILMTK a Jupyter:
python -m ipykernel install --user --name nilmtk-env --display-name "Python (nilmtk-env)"Prueba de la instalación
Ha llegado el momento de comprobar su instalación. Antes que nada, cree una nueva carpeta y descargue el conjunto de prueba aleatorio de Github:
mkdir nilmtk_test /
cd nilmtk_test /
wget https://raw.githubusercontent.com/nilmtk/nilmtk/master/data/random.h5Como puede comprobar random.h5 es el fichero de de datos en en formato hdf5 .A continuación, levante Jupyter:
notebook jupyterPara probar su instalación, intente importar el conjunto de datos aleatorio usando NILMTK y trazar todos los medidores:https://klemenjak.medium.com/media/9ba2be16d331653a7b4093a0fe412434
La salida debe ser:
MeterGroup (metros =
ElecMeter (instancia = 1, edificio = 1, conjunto de datos = Ninguno, electrodomésticos = [])
ElecMeter (instancia = 2, edificio = 1, conjunto de datos = Ninguno, electrodomésticos = [])
ElecMeter (instancia = 3, edificio = 1, conjunto de datos = Ninguno, electrodomésticos = [])
ElecMeter (instancia = 4, edificio = 1, conjunto de datos = Ninguno, electrodomésticos = [])
ElecMeter (instancia = 5, edificio = 1, conjunto de datos = Ninguno, electrodomésticos = [])
)¡Felicitaciones! Lo ha logrado. ¡NILMTK parece funcionar según lo previsto! La próxima vez, discutiremos cómo usar la API de NILMTK para una experimentación rápida y conveniente.
Mas información en https://github.com/nilmtk/nilmtk

Debe estar conectado para enviar un comentario.