Como continuación de un post anterior sobre las fuentes sin transformador, vamos a ver en este post algunos diseños de circuitos electrónicos que nos sirvan para alimentar un led de potencia sin tener que recurrir a una fuente convencional.
1- Controlador LED SMPS pequeño de 1 vatio
En este diseño, que es el más recomendado, estudiamos un circuito de controlador de LED SMPS que se puede usar para conducir LED de potencia con capacidad de entre 1 vatio LED y de hasta 12 vatios que se puede accionar directamente desde cualquier toma de corriente doméstica de 220 V CA o 120 V CA.
Introducción
El primer diseño explica un pequeño diseño de convertidor reductor SMPS no aislado (Punto de carga no aislado), que es un circuito muy preciso, seguro y fácil de construir. Aprendamos los detalles.
Principales características
El circuito de controlador de LED smps propuesto es extremadamente versátil y específicamente adecuado para la conducción de LED de alto vatio.
Sin embargo, al ser una topología no aislada no proporciona seguridad contra descargas eléctricas en el lado LED del circuito. Además del inconveniente anterior, el circuito es casi perfecto y está prácticamente protegido de todos los posibles peligros relacionados con la sobretensión.
Aunque una configuración no aislada puede parecer un poco indeseable, alivia al constructor del devanado de secciones primarias / secundarias complejas en núcleos E, ya que el transformador aquí se reemplaza con un par de estranguladores simples de tambor de ferrita.
El componente principal aquí responsable de la ejecución de todas las funciones es el IC VIPer22A de ST microelectronics, que ha sido diseñado específicamente para aplicaciones de controlador LED de 1 vatio compactas sin transformador .
Diagrama de circuito
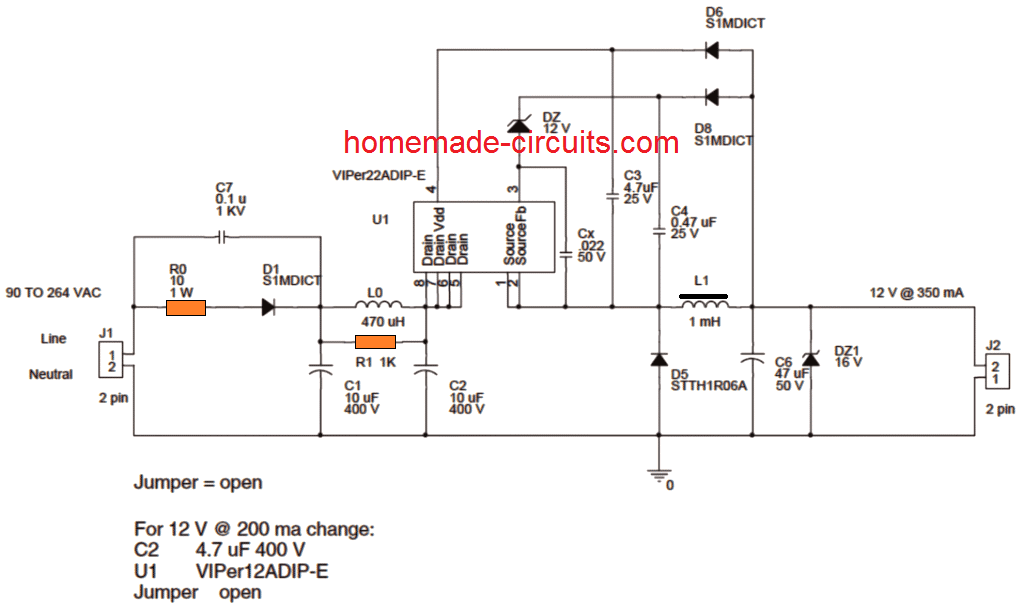
Imagen cortesía: © STMicroelectronics
Operación de circuito
El funcionamiento del circuito de este controlador LED de 1 vatio a 12 vatios puede entenderse como se detalla a continuación:
- La entrada de la red de 220V o 120V AC es media onda rectificada por D1 y C1. C1 junto con el inductor L0 y C2 constituyen una red de filtro de tarta para cancelar las perturbaciones EMI. D1 debe ser reemplazado preferiblemente con dos diodos en serie para sostener las ráfagas de picos de 2kv generadas por C1 y C2.R10 asegura cierto nivel de protección contra sobretensiones y actúa como un fusible durante situaciones catastróficas.
- Como se puede ver en el diagrama de circuito anterior, el voltaje a través de C2 se aplica al drenaje de mosfet interno del IC en el pin5 al pin8.
- Una fuente de corriente constante incorporada del VIPer IC entrega una corriente de 1 mA al pin4 del IC, que también es el pin Vdd del IC. Aproximadamente a 14.5V en Vdd, las fuentes de corriente se APAGAN y fuerza el circuito IC a un modo oscilatorio o inicia el pulso del IC.
- Los componentes Dz, C4 y D8 se convierten en la red de regulación de circuitos, donde D8 carga C4 al voltaje máximo en el período de marcha libre y cuando D5 está polarizado hacia adelante.
- Durante las acciones anteriores, la fuente o la referencia del IC se establece a aproximadamente 1V bajo tierra.
NOTA: Para obtener una información completa sobre los detalles del circuito del controlador LED de 1 a 12 vatios, consulte la hoja de datos en PDF de ST microelectronics.
2- Uso de fuente de alimentación capacitiva sin transformador
El siguiente controlador de LED de 1 vatio explicado a continuación muestra cómo construir un circuito de controlador de LED de 1 vatio simple de 220 V o 110 V , que le costaría no más de 1/2 dólar, excluyendo el LED, por supuesto.
Ya hemos visto el tipo de fuente de alimentación capacitiva en un par de post anteriores , como en el circuito de luz de tubo LED y en un circuito de fuente de alimentación sin transformador, asi que en el circuito actual también se utiliza el mismo concepto para controlar el LED de 1 vatio propuesto.
Operación de circuito
En el diagrama del circuito vemos un circuito de fuente de alimentación capacitiva muy simple para controlar un LED de 1 vatio, que se puede entender con los siguientes puntos:
- El condensador de 1uF / 400V en la entrada forma el corazón del circuito y funciona como el principal componente limitador de corriente del circuito.
- La función de limitación de corriente asegura que el voltaje aplicado al LED nunca exceda el nivel de seguridad requerido, sin embargo, los condensadores de alto voltaje tienen un problema grave, estos no restringen o no pueden inhibir el encendido inicial de la alimentación de la red en la carrera, lo que puede ser fatal para cualquier circuito electrónico. Los LED no son excepciones.
- Agregar una resistencia de 56 ohmios en la entrada ayuda a introducir algunas medidas de control de daños, pero aún así no puede hacer la protección completa de la electrónica involucrada. Un MOV ciertamente lo haría, ¿y qué pasa con un termistor? Sí, un termistor también sería una propuesta bienvenida.
Pero estos están relativamente en el lado más costoso y estamos discutiendo una versión barata para el diseño propuesto, por lo que querríamos excluir cualquier cosa que cruce una marca de dólar en lo que respecta al costo total.
Así que pensemos en una forma innovadora de reemplazar un MOV por una alternativa ordinaria y barata.¿Cuál es la función de un MOV? Es hundir la ráfaga inicial de alto voltaje / corriente a tierra de modo que sea a tierra antes de llegar al LED en este caso. ¿No haría un condensador de alto voltaje la misma función si se conecta a través del LED? Sí, seguramente funcionaría de la misma manera que un MOV.
La figura muestra la inserción de otro condensador de alto voltaje directamente a través del LED, que absorbe el influjo instantáneo de la sobretensión durante el encendido, lo hace mientras se carga y, por lo tanto, hunde casi todo el voltaje inicial en forma acelerada, lo que genera todas las dudas asociadas con Un tipo de fuente de alimentación capacitiva claramente clara.
El resultado final, como se muestra en la figura, es un circuito de controlador de LED de 1 vatio limpio, seguro, simple y de bajo costo, que cualquier aficionado a la electrónica puede construir en casa y usar para placeres personales y utilidad.
PRECAUCIÓN: EL CIRCUITO QUE SE MUESTRA A CONTINUACIÓN NO ESTÁ AISLADO DE LA RED DE CA, POR LO TANTO ES EXTREMADAMENTE PELIGROSO TOCAR EN LA POSICIÓN DE ENERGÍA.
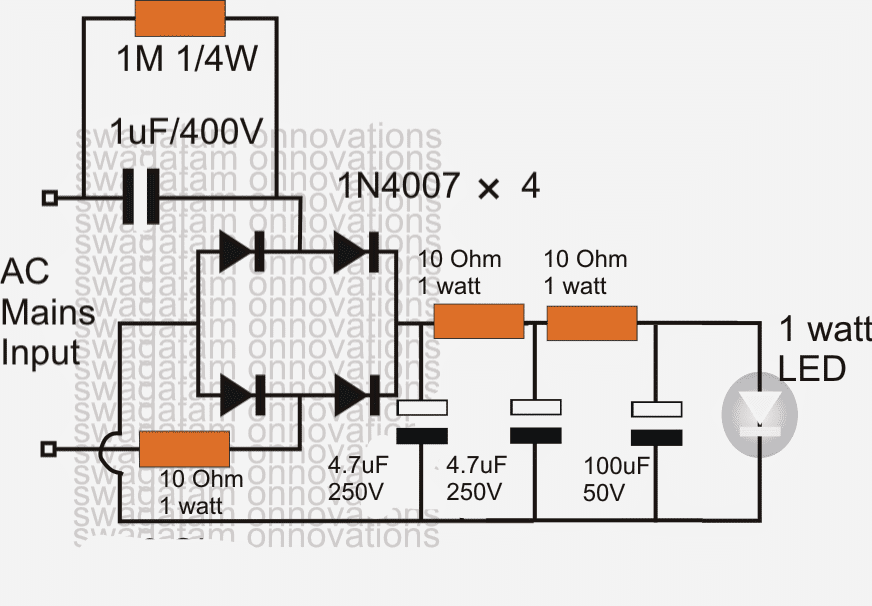
Diagrama de circuito
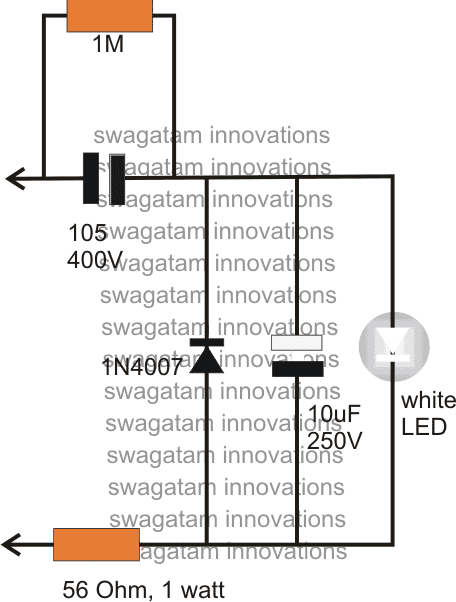
NOTA: El LED en el diagrama anterior es un 12V 1 vatio como se muestra a continuación:

En el circuito de controlador de led de 1 vatio simple que se muestra arriba, los dos condensadores de 4.7uF / 250 junto con las resistencias de 10 ohmios forman una especie de «interruptor de velocidad» en el circuito, este enfoque ayuda a detener el arranque inicial del interruptor de sobretensión ON que Ayuda a evitar que el LED se dañe.
Esta característica se puede reemplazar con un NTC que son populares por sus características de supresión de sobretensiones. Esta forma mejorada de abordar el problema de la sobretensión inicial podría ser conectando un termistor NTC en serie con el circuito o la carga.
Consulte el siguiente enlace para saber cómo incorporar un termistor NTC en el circuito de controlador LED de 1 vatio propuesto.
El circuito anterior se puede modificar de la siguiente manera, sin embargo, la luz puede verse un poco comprometida. Una buena manera de abordar el problema de la corriente de arranque inicial es conectando un termistor NTC en serie con el circuito o la carga.
3- Un controlador LED estabilizado de 1 vatio con fuente de alimentación capacitiva
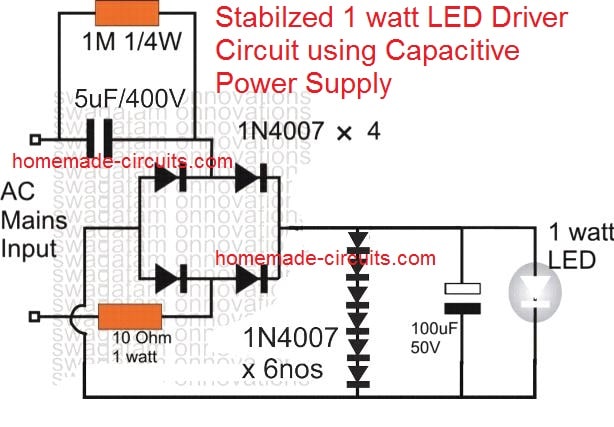
Como se puede ver, se utilizan 6nos de diodos 1N4007 a través de la salida, en su modo de polarización directa. Dado que cada diodo produciría una caída de 0.6V en sí mismo, 6 diodos crearían una caída total de 3.6V, que es la cantidad correcta de voltaje para el LED.
Esto también significa que los diodos desviarían el resto de la energía desde la fuente de tierra tp, y así mantendrían el suministro del LED perfectamente estabilizado y seguro.
Otro circuito de controlador capacitivo estabilizado de 1 vatio
El siguiente diseño controlado por MOSFET es probablemente el mejor circuito controlador de LED universal que garantiza una protección del 100% para el LED de todo tipo de situaciones peligrosas, como sobrevoltaje repentino y sobrecorriente o sobretensión.
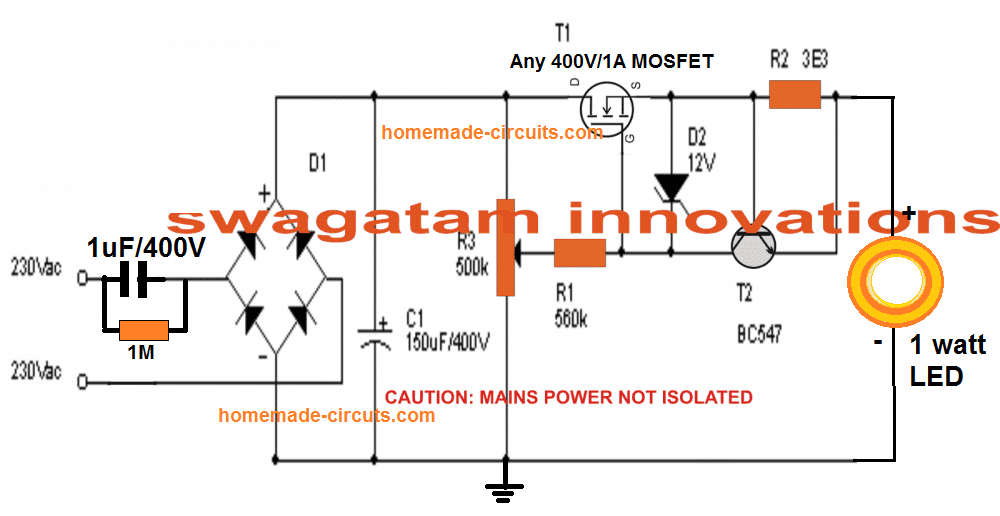
Un LED de 1 vatio conectado con el circuito anterior podría producir alrededor de 60 lúmenes de intensidad de luz, equivalente a una lámpara incandescente de 5 vatios.
El circuito anterior se puede modificar de la siguiente manera, sin embargo, la luz puede verse un poco comprometida.
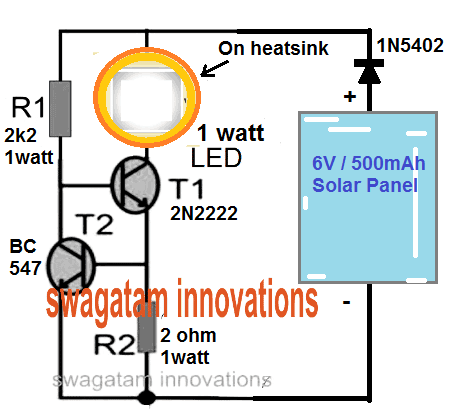
4- Circuito de controlador LED de 1 vatio con una batería de 6V
Como se puede ver en el cuarto diagrama, el concepto apenas utiliza ningún circuito o, más bien, no incorpora ningún componente activo de alta gama para la implementación requerida de la conducción de un LED de 1 vatio.
Los únicos dispositivos activos que se han empleado en el circuito controlador de LED de 1 vatio más simple propuesto son algunos diodos y un interruptor mecánico.
Los 6 voltios iniciales de una batería cargada se reducen al límite requerido de 3.5 voltios manteniendo todos los diodos en serie o en la ruta del voltaje de suministro del LED.
Dado que cada diodo deja caer 0.6 voltios a través de él, los cuatro juntos permiten que solo 3.5 voltios lleguen al LED, iluminándolo de manera segura y brillante.
A medida que cae la iluminación del LED, cada diodo se omite posteriormente utilizando el interruptor, para restaurar el brillo del LED.
El uso de los diodos para bajar el nivel de voltaje a través de los LED asegura que el procedimiento no disipe ningún calor y, por lo tanto, se vuelva muy eficiente en comparación con una resistencia, que de lo contrario habría disipado mucho calor en el proceso.

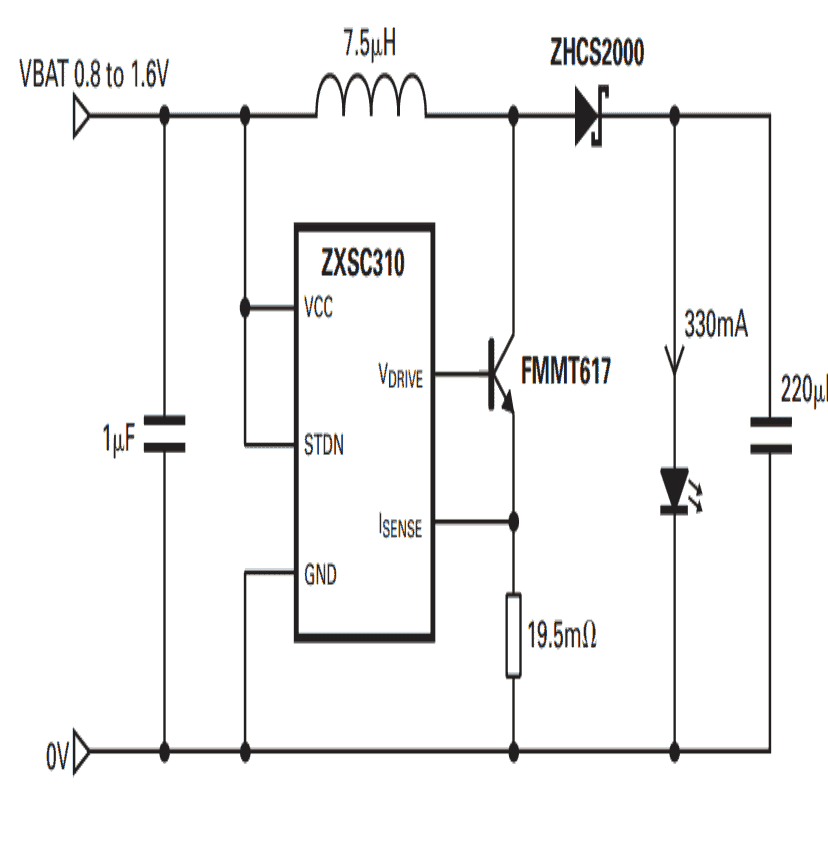
5- Iluminar un LED de 1 vatio con una celda AAA de 1.5V
En el quinto diseño, aprendamos a iluminar un LED de 1 vatio utilizando una celda AAA de 1.5 por un tiempo razonable. Obviamente, el circuito se basa en la tecnología de impulso de impulso, de otra manera, manejar una carga tan grande con una fuente tan mínima está más allá de la imaginación.
Un LED de 1 vatio es relativamente grande en comparación con una fuente de celda AAA de 1.5 V y sólo necesita un suministro mínimo de 3 voltios, que es el doble de la capacidad nominal de la celda anterior. En segundo lugar, un LED de 1 vatio requeriría entre 20 y 350 mA de corriente para funcionar, siendo 100 mA una corriente respetable para conducir estas máquinas ligeras.
Por lo tanto, el uso de una celda de linterna AAA para la operación anterior se ve muy remota y fuera de discusión.
Sin embargo, el circuito discutido aquí demuestra que todos estamos equivocados y maneja con éxito un LED de 1 vatio sin muchas complicaciones.
GRACIAS A ZETEX, por proporcionarnos este pequeño y maravilloso IC ZXSC310, que requiere solo unos pocos componentes pasivos comunes para hacer posible esta hazaña.
Operación de circuito
El diagrama muestra una configuración bastante simple, que es básicamente una configuración de convertidor de impulso. La entrada de CC de 1.5 voltios es procesada por el IC para generar una salida de alta frecuencia. La frecuencia es conmutada por el transistor y el diodo schottky a través del inductor.La rápida conmutación del inductor proporciona el aumento requerido en el voltaje que se convierte en apropiado para controlar el LED de 1 vatio conectado.
Aquí, durante la finalización de cada frecuencia, la energía almacenada equivalente dentro del inductor se bombea nuevamente al LED generando el aumento de voltaje requerido, lo que mantiene el LED iluminado durante largas horas incluso con una fuente tan pequeña como una celda de 1.5 voltios.
Controlador LED solar de 1 vatio
Siempre que se requiera un controlador solar simple pero seguro, inevitablemente optaremos por el omnipresente IC LM317. Aquí también, utilizamos el mismo dispositivo económico para implementar la lámpara LED propuesta de 1 vatio usando un panel solar.
El diseño completo del circuito se puede ver a continuación:
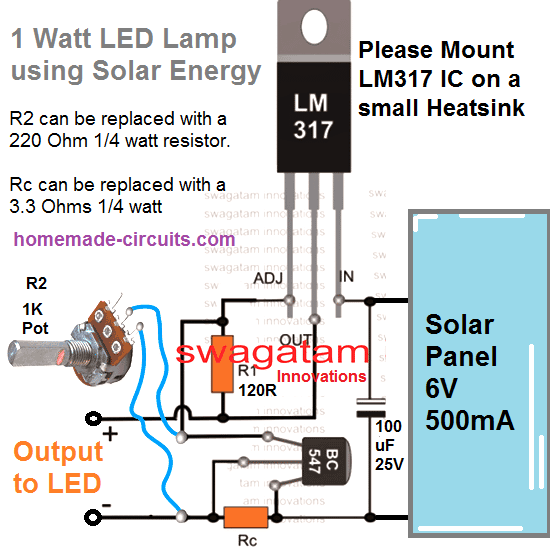
Una inspección rápida revela que si hay un control de corriente presente, se puede ignorar la regulación de voltaje. Aquí hay una versión simplificada para el concepto anterior, que usa solo un circuito limitador de corriente .


Debe estar conectado para enviar un comentario.