Gracias el bajo coste y la gran popularidad de la Raspberry Pi , hoy en día es muy fácil ofrecer soluciones muy flexibles de control de dispositivos por Internet mediante diferentes vías de una forma muy sencilla sin necesidad de realizar una gran inversión ,saber electrónica ni por supuesto escribir una sola línea de código para ello
La solución que vamos a proponer es una utilidad capaz de controlar 8 cargas de hasta 10 Amp pero también se puede expandir con otras 6 cargas mas ( añadiendo una placa de mas relés) pudiendo por tanto controlar hasta 14 cargas simultáneamente sin multiplexar ,todo ello como decíamos sin escribir ninguna línea de código gracias a la solución gratuita Cayenne ,la cual consigue una gran automatización , pues es capaz de gracias a una app móvil instalar un agente en la Raspberry Pi, que una vez instalado, permite poderlo controlar ( y ver el estado ) de forma remota desde cualquier parte del mundo, bien desde un navegador o bien desde la propia app móvil.
Para empezar si contamos con una Raspberry Pi , lo primero es si aun no lo ha hecho ,es generar la imagen del SO con la que arrancara la Raspberry Pi . Aunque hay diferentes opciones (de hecho en este blog hemos visto que es posible instalar otras SO incluso Windows 10.) , para la solución propuesta, lo mejor es usar la ultima distribución disponible de Raspbian pues al ser el sistema operativo mas instalado en el mundo en la Raspberry Pi es la distribución compatible con el software propuesto (además precisamente hace unos días , Raspbian hace acaba de recibir una actualización intensa conocida como Pixel llena de muchísimas novedades y mejoras tanto en el diseño como en el rendimiento del software).
Si no ha instalado Pixel puede hacerlo descargando la imagen de la SD a partir del sitio oficial Raspbian ,donde hay dos opciones :la versión previa mínima (Jessie) o la nueva de Jessie con Pixel:
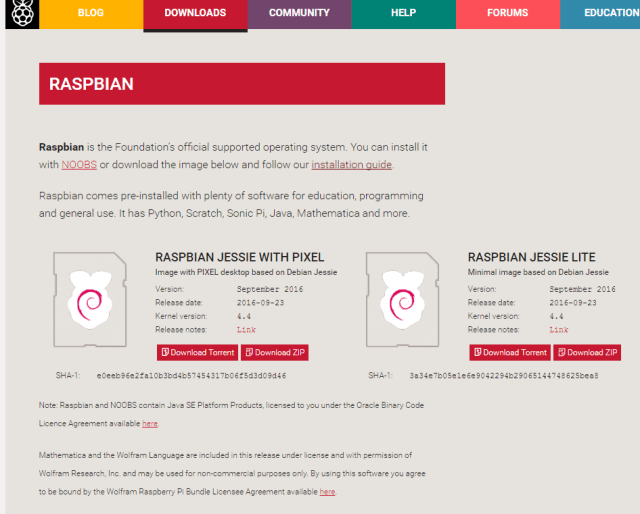
Lógicamente si la SD es suficiente grande , lo interesante es descargar la primera en lugar de la versión mínima que ademas esta obsoleta
Una vez descargada la imagen correspondiente en su ordenador siga los siguientes pasos:
- Inserte la tarjeta SD en el lector de tarjetas SD de su ordenador comprobando cual es la letra de unidad asignada. Se puede ver fácilmente la letra de la unidad, tal como G :, mirando en la columna izquierda del Explorador de Windows. Puede utilizar la ranura para tarjetas SD, si usted tiene uno, o un adaptador SD barato en un puerto USB.
- Descargar la utilidad Win32DiskImager desde la página del proyecto en SourceForge como un archivo zip; puede ejecutar esto desde una unidad USB.
- Extraer el ejecutable desde el archivo zip y ejecutar la utilidad Win32DiskImager; puede que tenga que ejecutar esto como administrador. Haga clic derecho en el archivo y seleccione Ejecutar como administrador.
- Seleccione el archivo de imagen que ha extraído anteriormente de Raspbian.
- Seleccione la letra de la unidad de la tarjeta SD en la caja del dispositivo. Tenga cuidado de seleccionar la unidad correcta; si usted consigue el incorrecto puede destruir los datos en el disco duro de su ordenador! Si está utilizando una ranura para tarjetas SD en su ordenador y no puede ver la unidad en la ventana Win32DiskImager, intente utilizar un adaptador SD externa.
- Haga clic en Escribir y esperar a que la escritura se complete.
- Salir del administrador de archivos y expulsar la tarjeta SD.
- Ya puede insertar la SD en su Raspberry Pi en el adaptador de micro-sd , conectar un monitor por el hdmi , conectar un teclado y ratón en los conectores USB, conectar la con un cable ethernet al router conectividad a Internet y finalmente conectar la alimentación para comprobar que la Raspeberry arranca con la nueva imagen
Una vez instalado Raspbian en su SD, lo siguiente es instalar el agente de Cayenne:
Instalación del agente Cayenne en la Raspberry Pi
El proceso de instalación de Cayenne en la Raspberry Pi es bastante simple y no debería tomar demasiado tiempo para obtener su creación y funcionamiento. Usted tendrá que asegurarse de que ha instalado en su Raspbian Pi. .
- En primer lugar, vaya a myDevices Cayenne y regístrese para obtener una cuenta gratuita.
- Una vez que ya se ha registrado usted tendrá que registrarse / conectar el Pi hasta la cuenta que acaba de crear. Para ello sólo tiene que copiar las 2 líneas de comandos que se muestran después de su inscripción. Por ejemplo :
wget https://cayenne.mydevices.com/dl/rpi_qcps12pc3d.sh sudo bash rpi_qcps12pc3d.sh -v
Introduzca estos en el terminal para su Pi.(Estos archivos son únicos para cada instalación nueva)
Alternativamente, se puede descargar la aplicación y se puede localizar e instalar en su Cayenne Pi automáticamente. (Tenga en cuenta SSH debe estar habilitado )
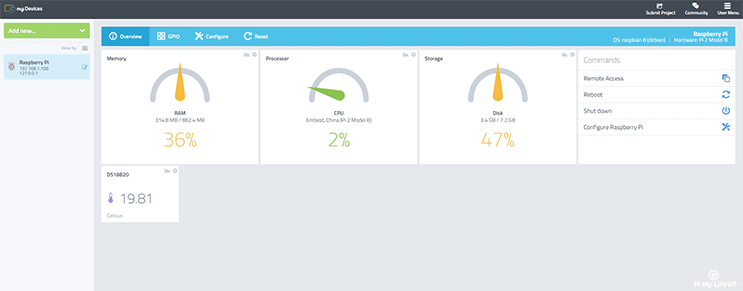
- Tomará unos minutos para instalar en el Pi en función de la velocidad de su conexión a Internet es. El navegador web o aplicación deben actualizar automáticamente con información sobre el proceso de instalación.
- Una vez instalado el tablero de instrumentos se mostrará y debe verse como algo más adelante.
Placa de Relés
Para implementar el control vamos a utilizar una placa de relés de 5V y ocho canales de bajo coste ( unos 8 € en Amazon), que para mayor seguridad esta optoacoplada para proteger la Raspberry PI
Obviamente los relés electromecánicos también ofrecen un separación galvánica entre la lógica y la parte de AC pero como que los aparatos que vamos a controlar funcionan con 220V, y los pines GPIO de Raspberry trabajan con un máximo de3,3V no esta mal que la placa cuente con este doble factor de aislamiento para evitar problemas.
Un módulo económico y perfecto para nuestro propósito es el Timetop distribuido por Andoer , un módulo con alimentación de 5V , la cual tomara directamente de la Raspberry Pi .Se trata de una placa de interfaz de relé de 8 canales, que puede ser controlada directamente por una amplia gama de microcontroladores tales como Arduino, AVR, del PIC, ARM, PLC, Raspberry Pi etc
El contacto de cada relé soporta una salida máxima en AC 250V de 10A y en corriente continua DC30V también de 10A lo cual lo hace ideal para controlar varios aparatos y otros equipos de la corriente grande. .
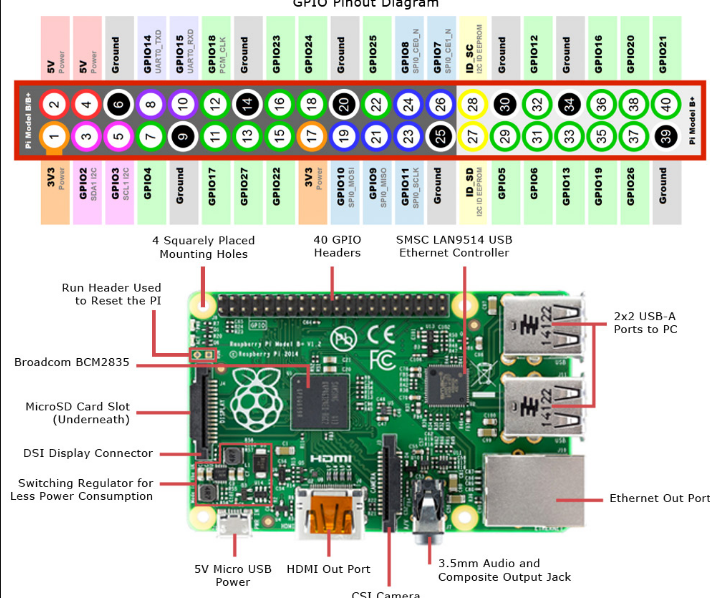
En la imagen nos muestra en la parte superior los conectores con la Raspberry, el GND lo conectaremos a tierra, el IN1 de la placa de reles que controlara el canal de K1 (IN2 para el K2…) los conectaremos a un GPIO y haremos lo mismo con todas las conexiones IN2,IN3,IN4,IN5,IN6,IN7,IN8 ( según el numero de relés que tenga la placa) Finalmente el VCC lo conectamos a los 5V de la Raspberry. En la parte izquierda de la placa de relés ( donde vemos la clemas azules ) controlaremos los circuitos donde conectaremos los cables, si cerramos el circuito entre 1 y 2, el circuito normalmente estará ‘abierto’, si lo cerramos entre el 2 y el 3, el circuito normalmente estará ‘cerrado’.

Prueba Manual desde la Raspberry Pi
Como se puede puede imaginar el circuito es bastante simple En la RaspberryPi para probar localmente que todo esta correcto instalaremos wiringpi y no hay que instalar nada más.
tar xfzv wiringPi-xxx.tar.gz |
cd wiringPi-xxx |
./build |
En el Raspberry ejecutamos:
|
1
|
gpio -g mode 18 out |
Para encenderla:
|
1
|
gpio -g write 18 1 |
Para apagar la luz ejecutamos:
|
1
|
gpio -g write 18 0 |
gpio readall --> Nos saca el status de todos los GPIO. |
gpio -g mode 24 out --> Enciende GPIO24. |
gpio -g mode 24 in --> Apaga el GPIO24. |
gpio -g read 24 --> Saca el status, encendido 0, apagado 1. |
Una vez probado el circuito ya desde el interfaz de cayenne ( desde la web o desde la aplicación móvil) si esta nuestra placa correctamente configurada podremos ver el estado de los relés así como interactuar con ellos .
Dudas mas comunes
- Bien, he descargado la aplicación, ¿qué hago ahora? En primer lugar, asegúrese de que tiene el Sistema Operativo Raspbian (OS) instalado en su Raspberry Pi. Este es el sistema operativo estándar que viene de los propios fabricantes de Raspberry Pi. Si usted compró NOOBS, la tarjeta SD pre-formateada, entonces se debe instalar fácilmente Raspbian para usted.
- ¿Necesito un poco más de instrucción? Raspberry Pi tiene un tutorial aquí que le guiará a través de cómo instalar el sistema operativo Raspbian en su Raspberry Pi. En segundo lugar, su Raspberry Pi debe estar conectada a Internet. Si su Raspberry Pi está conectada a la misma red que su teléfono, entonces la aplicación myDevices Cayenne encontrará automáticamente su Raspberry Pi y descargará el agente para que puedas empezar a construir tus proyectos IoT en un abrir y cerrar de ojos.
- ¿Tengo que saber programar para utilizar myDevices Cayenne? He probado otras plataformas y me exigían programar. Una vez que el agente Cayenne está instalado en su Raspberry Pi, myDevices Cayenne se encarga de toda la codificación. De esta forma, ¡puedes centrarse en crear!
- He oído hablar del término «agente», ¿qué es? Es un software que instalamos en tu Raspberry Pi y que le permite controlar y gestionar todos los sensores, actuadores y extensiones que utilices en tus proyectos IoT. También significa que usted no tiene que escribir ningún código.
- ¿Tengo que estar conectado a la misma red WiFi que mi Raspberry Pi para poder controlarla y gestionarla? No, conectan su Raspberry Pi a la nube por esta misma razón.
- El panel de control de mi cuenta tarda un poco en reconocer que he encendido mi Raspberry Pi, ¿por qué? Esto es correcto. Después de arrancar su Raspberry Pi, se tarda aproximadamente un minuto para que todo se cargue. Esto es normal en todos los ordenadores.
- ¿Tendré que pagar alguna vez para utilizar la aplicación myDevices Cayeene o el panel web?De momento, no. Si alguna vez planeamos cobrar por algo, serás el primero en saberlo.
- ¿Debo apagar mi Raspberry Pi cuando conecte sensores, actuadores o extensiones? Sí, debe desconectar la alimentación de su Raspberry Pi cuando añada o quite cables. Una vez que haya terminado, conecte su Raspberry Pi de nuevo a la fuente de alimentación.
- ¿Funciona myDevices Cayenne a través de bluetooth?Todavía no. Por favor, ¡hágales saber a los programadores de Cayenne si esta es una característica importante!
- La función de escritorio remoto no funciona.Es posible que tenga que permitir las ventanas emergentes para que funcione el acceso remoto.









Debe estar conectado para enviar un comentario.