Puede parecer algo anacrónico, pero lo cierto es que probablemente el teclado y ratón tal como los conocemos hoy en día tenga sus días contados gracias al espectacular avance sufrido estos años en apartado de reconocimiento de voz usando redes neuronales claramente propiciado por en las ingentes subida de capacidades de computo gracias al Cloud Commputing ,el Big Data y el aprendizaje automático
Veamos algunas soluciones de reconocimiento de voz liderado por grandes proveedores como pueden ser Google o IBM

Google Cloud Speech
En efecto desde Google proponen la API Speech de Google Cloud , la cual permite que los desarrolladores conviertan audio en texto aplicando potentes modelos de redes neuronales en una API fácil de usar. La API Speech reconoce más de 80 idiomas y sus variantes para gestionar una clientela internacional. Asimismo, se puede filtrar el contenido inapropiado en los resultados de texto.
La API Speech de Cloud se tarifica por intervalos de 15 segundos de audio procesados después de los 60 primeros minutos, que son gratuitos.
| USO MENSUAL | PRECIO POR CADA 15 SEGUNDOS* |
|---|---|
| Hasta 60 minutos | Gratuito |
| 61 – 1.000.000 de minutos* | 0,006 $ |
*Este precio es válido para aplicaciones de sistemas personales (por ejemplo, teléfonos, tablets, portátiles y ordenadores). El uso mensual está limitado a un millón de minutos.
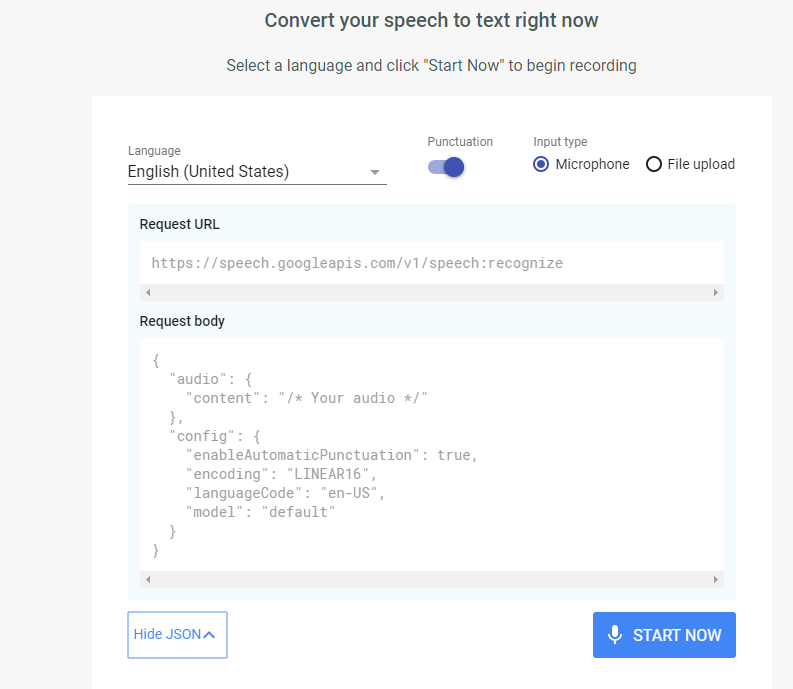
Se puede transcribir el texto que los usuarios dictan al micrófono de una aplicación, habilitar el control por voz o transcribir archivos de audio, entre muchas otras funciones.
La API Speech puede transmitir resultados de texto conforme vaya reconociendo el audio, de forma que el texto reconocido aparece inmediatamente mientras la persona habla asi que consigue resultados de texto en tiempo real
De igual modo, la API puede reconocer el texto a partir del audio almacenado en un archivo pero solo si se tiene cuenta en Google Cloud.
Como «truco» casero para probar la funcionalidad del API se puede inyectar el audio ya grabado desde un dispositivo externo por medio de un cable de audio que lo introduciría en el pc seleccionando como dispositivo grabador la entrada de audio :debería funcionar exactamente igual que si hablamos por un micrófono
En el caso de que este validado contra Google y tenga cuenta en Google Cloud este paso se puede obviar porque se pueden subir directamente los ficheros que deseamos transcribir mediante la opción File Upload teniendo en cuenta la limitación de 60 minutos en caso de no querer pasar por caja
Si quiere probar esta funcionalidad esta es la url : https://cloud.google.com/speech-to-text/
Como no podía ser de otra manera, también es posible reconocer el audio subido en la solicitud e integrarlo en su almacenamiento de audio de Google Cloud Storage.
Gracias a la tecnología del aprendizaje automático ,se aplican los algoritmos más avanzados de redes neuronales del aprendizaje profundo al audio de sus ficheros para conseguir un reconocimiento de voz de máxima precisión. Mencionar que como todos los sistemas de aprendizaje con redes neuronales la precisión de la API Speech mejora con el tiempo, conforme perfeccionan la tecnología interna de reconocimiento de voz que usa los productos de Google.
No se necesitan pues sistemas avanzados de procesamiento de señales ni reducción de ruido antes de enviar el audio a la API Speech. El servicio es capaz de procesar audio ruidoso procedente de diversos entornos de forma satisfactoria.
El reconocimiento de voz se puede adaptar al contexto suministrando un conjunto independiente de palabras clave con cada llamada a la API, lo que resulta especialmente útil para las situaciones de control de dispositivos y aplicaciones.
La API Speech es compatible con cualquier dispositivo que pueda enviar solicitudes REST o gRPC, incluidos teléfonos, ordenadores, tablets y dispositivos con Internet de las Cosas (por ejemplo, coches, televisores o altavoces).
CARACTERÍSTICAS DE LA API SPEECH
Conversión de voz en texto gracias al aprendizaje automático
- El reconocimiento automático de voz (ASR) basado en redes neuronales de aprendizaje profundo dota a las aplicaciones , la funcionalidad de búsqueda por voz o transcripción de voz.Reconoce más de 80 idiomas y variantes, con un amplio vocabulario proporcionando resultados de reconocimiento mientras los usuarios siguen hablando.
- Es posible personalizar el reconocimiento de voz según un contexto específico suministrando un conjunto de palabras y frases que tienen muchas probabilidades de aparecer. Esto resulta especialmente útil para añadir palabras y nombres personalizados al vocabulario, así como en situaciones de control por voz.
- El sonido puede proceder del micrófono de una aplicación o de un archivo de audio grabado previamente. Se admiten diversas codificaciones de audio, como FLAC, AMR, PCMU y Linear-16.
- Es capaz de procesar audio de diversos entornos ruidosos sin necesidad de reducción de ruido adicional así que puede filtrar contenido inapropiado en los resultados de texto para algunos idiomas.
- El API como vemos esta integrada:los archivos de audio se pueden subir en la solicitud o integrar en Google Cloud Storage.
Transcripción de archivos de audio cortos
Es muy sencillo transcribir un archivo de audio corto a texto utilizando el reconocimiento de voz sincrónico.
El reconocimiento de voz síncrona devuelve el texto reconocido para audio corto (menos de ~ 1 minuto) en la respuesta tan pronto como se procese(para procesar una solicitud de reconocimiento de voz para audio largo, use el Reconocimiento de voz asincrónico ).
El contenido de audio se puede enviar directamente a Cloud Speech-to-Text, o puede procesar contenido de audio que ya reside en Google Cloud Storage.
Speech-to-Text v1 se lanzó oficialmente y, en general, está disponible desde el extremo https://speech.googleapis.com/v1/speech . Las bibliotecas de cliente se lanzan como alfa y es probable que se modifiquen de formas incompatibles hacia atrás. Las bibliotecas del cliente actualmente no se recomiendan para uso de producción.
Estas muestras requieren que haya configurado gcloud y haya creado y activado una cuenta de servicio.
Realización de reconocimiento de voz síncrono en un archivo local
Aquí hay un ejemplo de cómo realizar el reconocimiento de voz sincrónico en un archivo de audio local mediantes comados de GCLOUD
recognize para obtener detalles completos.Para realizar el reconocimiento de voz en un archivo local, use la herramienta de línea de comandos de gcloud , pasando la ruta de archivo local del archivo para realizar el reconocimiento de voz.
gcloud ml speech reconoce CAMINO-AL-LOCAL-FILE --language-code = 'en-US'
Si la solicitud es exitosa, el servidor devuelve una respuesta en formato JSON:
{
"results": [
{
"alternatives": [
{
"confidence": 0.9840146,
"transcript": "how old is the Brooklyn Bridge"
}
]
}
]
}
Realización de reconocimiento de voz síncrono en un archivo remoto
Para su comodidad, la API de voz a texto puede realizar el reconocimiento de voz sincrónico directamente en un archivo de audio ubicado en Google Cloud Storage, sin la necesidad de enviar el contenido del archivo de audio en el cuerpo de su solicitud.
Aquí hay un ejemplo de cómo realizar el reconocimiento de voz sincrónico en un archivo ubicado en Cloud Storage usando comandos GCLOUD
recognize para obtener detalles completos.Para realizar el reconocimiento de voz en un archivo local, use la herramienta de línea de comandos de gcloud , pasando la ruta de archivo local del archivo para realizar el reconocimiento de voz.
gcloud ml speech reconoce 'gs: //cloud-samples-tests/speech/brooklyn.flac' \ --language-code = 'en-US'
Si la solicitud es exitosa, el servidor devuelve una respuesta en formato JSON:
{
"results": [
{
"alternatives": [
{
"confidence": 0.9840146,
"transcript": "how old is the Brooklyn Bridge"
}
]
}
]
}
Mas informacion en https://cloud.google.com/speech-to-text/docs/sync-recognize?hl=es#speech-sync-recognize-gcloud
IBM
También esta disponible para testeo Watson de IBM, que permite dictado a texto
El servicio IBM Watson Speech to Text utiliza capacidades de reconocimiento de voz para convertir el árabe, el inglés, el español, el francés, el portugués de Brasil, el japonés y el mandarín en texto.Este sistema por el momento se usa o para fines de demostración y no está destinado a procesar datos personales ,así que no se deben ingresar datos personales en este sistema, ya que puede no tener los controles necesarios para cumplir con los requisitos del Reglamento general de protección de datos (UE) 2016/679.
Lo mas destacable DE Watson es asimismo la capacidad de transcribir audio done se puede usa su micrófono para grabar audio o cargar audio pregrabado (.mp3, .mpeg, .wav, .flac o .opus solamente).
Incluso puede reproduzca uno de los archivos de audio de muestra para probar el servicio , ahora eso si los archivos de audio de muestra de banda ancha son en inglés de EE. UU y están cubiertos por la licencia de Creative Commons.
El resultado devuelto incluye el texto reconocido, las alternativas de palabras y las palabras clave moteadas. Algunos modelos pueden detectar múltiples altavoces; esto puede ralentizar el rendimiento.
A continuación esta es la url para probar el servicio en modo demo: https://speech-to-text-demo.ng.bluemix.net/
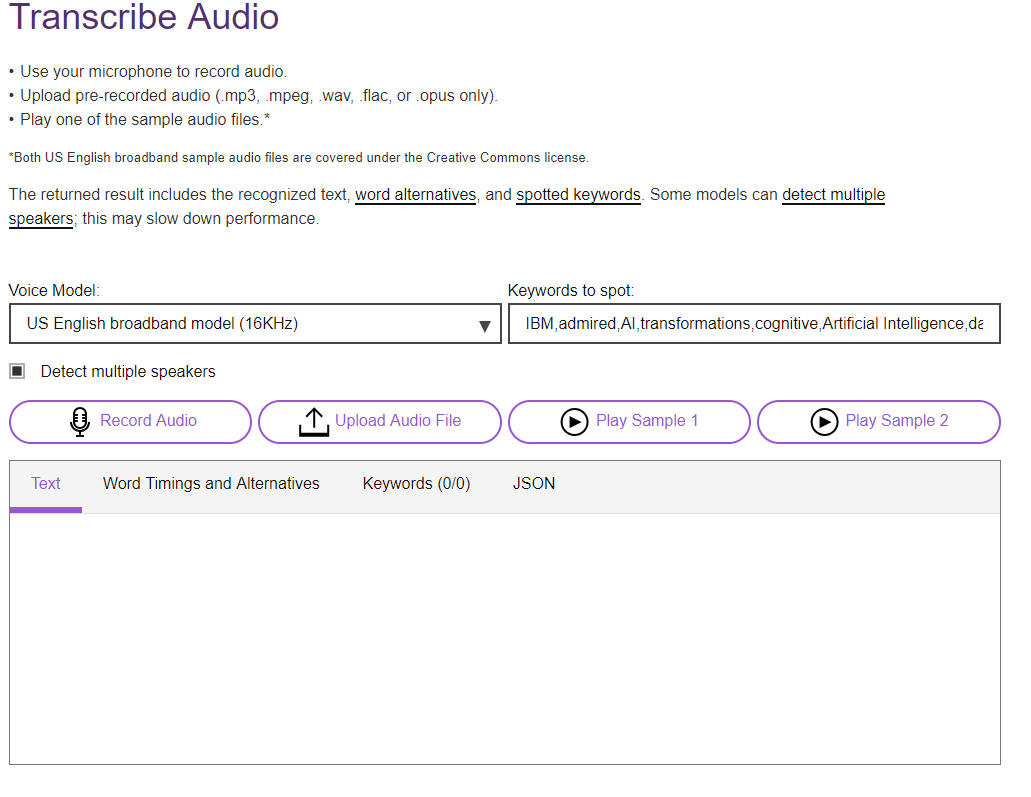
En teoría los primeros 1000 minutos al mes son gratis en el servicio estándar, así que el limite es muy superior de uso gratuito al de Google .
¿Le parece mejor opción la de IBM que la de Google?¿Conoce algún otro servicio gratuito que podamos usar desde nuestras apps? Sin duda la carrera por copar este mercado no acaba mas que empezar

Debe estar conectado para enviar un comentario.